








打造你的智能家居管家-DIY智能音箱完全指南
在前几年智能音箱刚开始面世的时候,它那颠覆性的创新,能说会道,可以听歌,可以设置闹钟甚至还可以控制家里的用电器,这着实惊艳了我,当然买一个体验也是必然的,然而用着用着就对“它”越来越嫌弃。其中不仅仅是由于它那不懂变通套路式的“机械回答”,更有对自己不能随意添加自己想要的技能感到苦闷。以小爱同学为例想要添加一个技能需要先注册一个开发者账号,然后准备服务器搭建自己的业务逻辑,最后上线服务,这个对于我们这些非专业人士来说实在过于复杂且麻烦。若要自己开发一个智能音箱那更是难如登天,其中涉及到语音唤醒、语音识别、语义理解等各种技术点更是无从下手。随着自己了解的知识越来越多以及各种人工智能技术的发展与大语言模型的兴起,我那曾经遥不可及的梦似乎有了实现的可能,那些无法逾越过的“鸿沟们”也正在逐一被解决。现在我将自己实现该目标的过程进行整理与大家分享这一旅程的点滴和成果。
视频演示
下面让我们来看看DIY智能音箱的演示视频,该视频当中展示了大语言模型对话以及传感器状态查询与自定义执行器控制。
香橙派DIY智能音箱
所用硬件
本项目用到了Orangepi zero3与USB音箱一体麦克风(见图1),树莓派对于玩开源硬件的小伙伴来说应该是无人不知无人不晓,它可以用来学Python玩机器视觉等,本质上就是一个功能完备的迷你电脑,但其价格相对来说较为昂贵,而Orangepi则是树莓派的国产平替,它们都有着相同的架构与外设,代码也几乎通用,故而这里我们使用物美价廉的Orangepi zero3。项目需要用到语音识别与语音合成因此需要用到麦克风与扬声器,这里采用2合1的USB音箱一体麦克风,这样我们不需要独立的两个设备而仅需1个USB口便可同时使用语音识别与语音合成,使用时将Orangepi zero3隐藏仅保留麦克风主体部分在桌面这样既整洁又美观。
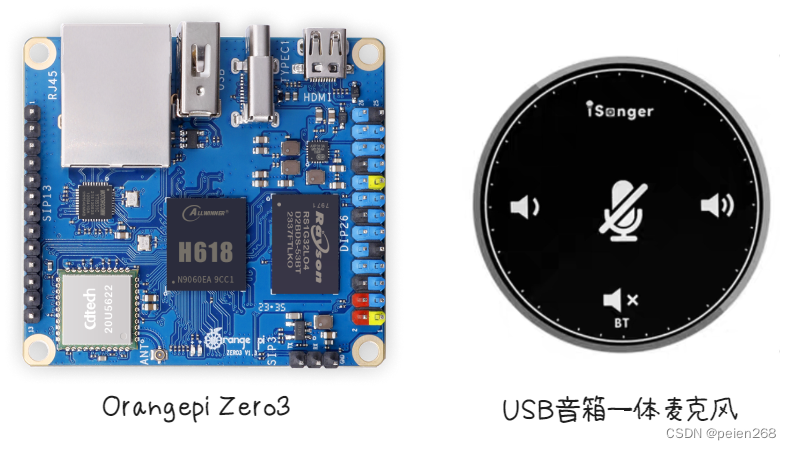
硬件特点
- 四核Cortex-A53处理器、WiFi、蓝牙
- 26Pin扩展功能口
- HDMI音视频输出
- USB2.0 X 3
- GPIO、I2C、UART、SPI、PWM
- 音箱麦克风二合一
本教程所需准备
软硬件准备
- Orangepi Zero3 Linux 6.1.31系统镜像(Orangepi官网下载)
- Orangepi Zero3 2G版本开发板(至少2G,内存过低会导致系统拓展性差,某些应用可能无法正常使用)
- 一张SD卡(考虑可拓展性建议不低于16GB且为高速卡)
- balenaEtcher镜像烧录工具
关于镜像的下载与烧录配置等不在本文讨论范围,大家可以在Orangepi官网下载查阅OrangePi_Zero3_H618用户手册进行相关学习。
项目思维导图
根据我们的项目预期目标绘制思维导图(见图2),下面我们详细介绍每个功能如何实现。
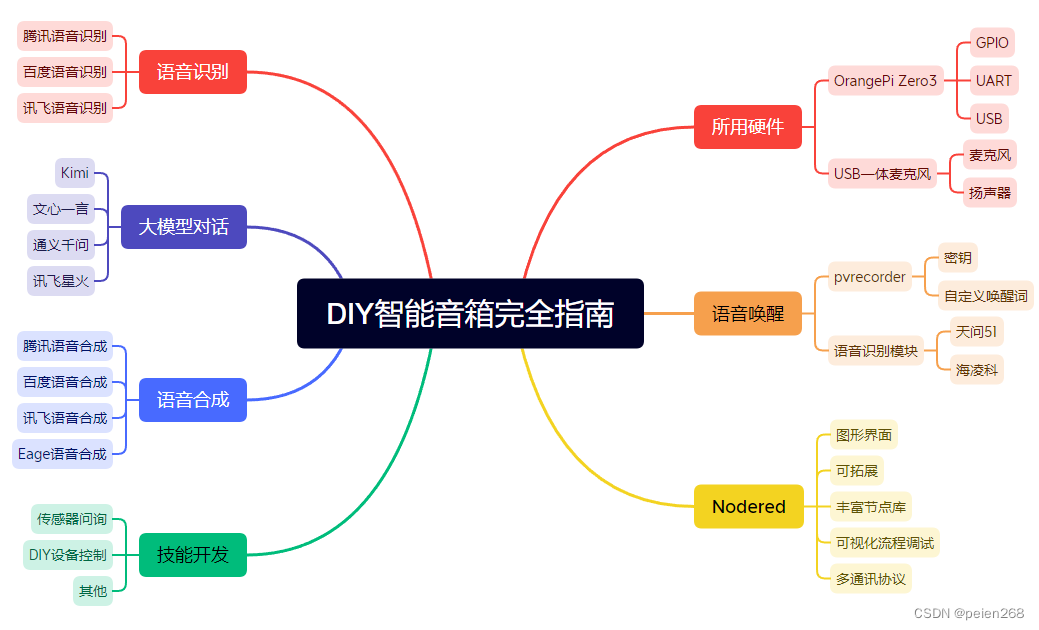
项目实现原理
设备查询
当给linux系统接入了一个音频设备后,我们想要使用这个音频设备第一步是要获取设备ID,例如我们这里接入的USB音箱一体麦克风,我们写一个python代码进行查询,代码如程序1所示。
程序1
import pyaudio
def list_audio_input_devices():
audio = pyaudio.PyAudio()
device_count = audio.get_device_count()
input_devices = []
print("Available audio input devices:")
for i in range(device_count):
device_info = audio.get_device_info_by_index(i)
if device_info.get('maxInputChannels') > 0:
input_devices.append((i, device_info['name'], device_info['defaultSampleRate']))
audio.terminate()
return input_devices
input_devices = list_audio_input_devices()
print("Device Index\tDevice Name\t\tDefault Sample Rate (Hz)")
for device in input_devices:
print(f"{device[0]}\t\t{device[1]}\t\t{device[2]}")
代码保存为query_device.py运行程序1将得到设备上所有已连接的音频设备列表(见图3)。

在图3中我们可以发现当前存在两个音频设备,设备ID分别是1(自带的HDMI接口)和2,里面的JieLi BR21便是接入的USB音箱一体麦克风,其设备ID为2,音频播放设备是hw:3,0,麦克风音频采样率是48000,记住这3个参数,后面的代码中将会用到。
语音唤醒
语音唤醒(Voice Wake-up)是指通过声音识别技术,使设备在未被激活的状态下响应特定的唤醒词,从而启动语音助手或其他应用程序。常见的开源唤醒框架有Snowboy、pvrecorder、Snips等,它们的优点是麦克风即可作为唤醒设备也能作为录音设备使用,这里我们使用简单易用的pvrecorder。想要使用pvrecorder我们得要注册一个pvrecorder账号,我们访问pvrecorder官网进行注册并登录后可进入到控制台主页(见图4)在该页面可以看到自己的密钥,使用设备的数量(个人账户一个密钥可以使用3台设备)与自定义唤醒词按钮,这里我们记录自己的密钥备用。
下面的程序2是pvrecorder语音唤醒的一个简单示例,这里的device_index便是程序1中查询到的设备2,具体以自己查询到的为准。
程序2
import pvporcupine
from pvrecorder import PvRecorder
access_key = "ziFMmG4cpz5pEJj+u/mhS/K9AcqhDUI7b5zAJCN6TQZfohpW8xxxxx=="
keywords = ["hey siri", "jarvis", "hey google", "ok google"]
porcupine = pvporcupine.create(access_key=access_key, keywords=keywords)
recoder = PvRecorder(device_index=2, frame_length=porcupine.frame_length)
print('开始语音唤醒')
try:
recoder.start()
while True:
keyword_index = porcupine.process(recoder.read())
if keyword_index >= 0:
print(f"Detected {keywords[keyword_index]}")
except KeyboardInterrupt:
recoder.stop()
finally:
porcupine.delete()
recoder.delete()
代码保存为wake/wake_test.py运行程序2效果如下(见图5)。
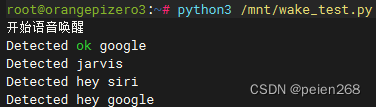
当我们说出hey siri, jarvis, hey google, ok google这四个唤醒词后SSH终端将打印对应的唤醒词,这些关键词是不是感觉很熟悉呢?它们都是pvrecorder预训练的唤醒词,如果你想偷懒就用这些那么到这里就可以了,当然还有别的预置唤醒词,具体可以自行前往pvrecorder官网了解。
自定义唤醒词
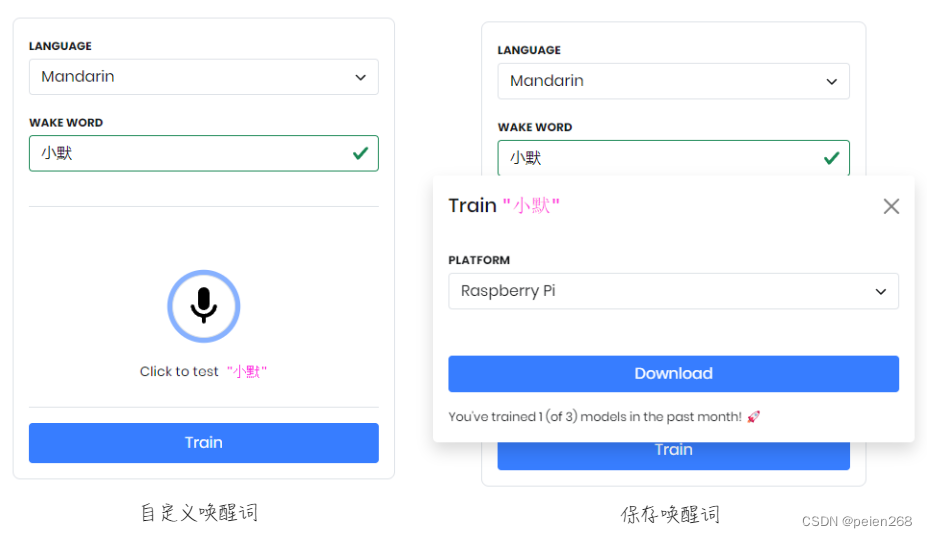
如果你对现有的唤醒词不满意当然你可以自己设置唤醒词,这里我们以中文唤醒词为例自定义唤醒词如下所示(见图6)
具体步骤如下:
- pvrecorder控制台点击序号3所示的按钮进入到自定义唤醒词页面
- 自定义唤醒词页面LANGUAGE下拉选择Mandarin选项
- WAKE WORD添加自定义的唤醒词(建议简短且非常用语)
- 填写完成后点击麦克风图标说出唤醒词在线测试(使用电脑麦克风测试)
- 点击Train下载唤醒词模型(RLATFORM选择Raspberry Pi)
这里我们可以自定义多个唤醒词,下载后的模型为压缩包,解压后得到后缀为.ppn的模型文件,模型文件名可以自定义,为了使用中文唤醒词我们还需要去语言模型页下载中文语言模型porcupine_params_zh.pv,下载后将唤醒词模型、中文模型、与自定义唤醒词的pyhton文件放到同一个目录。其中自定义唤醒词需要微调语音唤醒代码如程序3所示,代码中我们发现其与程序2相比仅多了唤醒词与语言模型文件位置。
程序3
import pvporcupine
from pvrecorder import PvRecorder
access_key = "ziFMmG4cpz5pEJj+u/mhS/K9AcqhDUI7b5zAJCN6TQZfohpW8xxxxx=="
keywords = ["小默","小静","佩恩",]
porcupine = pvporcupine.create(
access_key=access_key,
keyword_paths=['/mnt/xiaomo.ppn','/mnt/xiaojing.ppn','/mnt/peien.ppn'],
model_path='/mnt/porcupine_params_zh.pv'
)
recoder = PvRecorder(device_index=2, frame_length=porcupine.frame_length)
print('开始语音唤醒')
try:
recoder.start()
while True:
keyword_index = porcupine.process(recoder.read())
if keyword_index >= 0:
print(f"Detected {keywords[keyword_index]}")
except KeyboardInterrupt:
recoder.stop()
finally:
porcupine.delete()
recoder.delete()
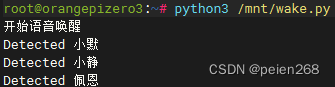
代码保存为wake.py运行程序3效果如下(见图7)。
到这一步我们可以实现任意唤醒词的唤醒,当我们定义了多个唤醒词后,还可以使用不同唤醒词充当不同的角色,每个唤醒词都用不同的音色回答我们问题,这就有趣多了。
自动录音
当我们唤醒设备后,我们需要录制一段音频用来表明我们的意图,我们采取的方法是自动录音,当停顿2秒未发声表示说话结束,此时结束录音,自动录音的代码见程序4。
程序4
import pyaudio
import wave
from pydub import AudioSegment
CHUNK = 4096
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 48000
WAVE_OUTPUT_FILENAME = "/mnt/output.wav"
THRESHOLD = 1000 # 设置声音的阈值
PAUSE_SECONDS = 2 # 设置停顿时间
DEVICE_INDEX = 2
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK,
input_device_index=DEVICE_INDEX)
frames = []
silent_count = 0 # 音量小于阈值的计数器
print('开始录音')
while True:
data = stream.read(CHUNK)
frames.append(data)
audio_data = AudioSegment(data, sample_width=2, frame_rate=RATE, channels=CHANNELS)
volume = audio_data.rms # 计算音频数据的RMS音量
if volume < THRESHOLD:
silent_count += 1
else:
silent_count = 0
if silent_count >= int(RATE / CHUNK * PAUSE_SECONDS):
break
audio = AudioSegment.from_file("/mnt/output.wav")
duration = audio.duration_seconds
print(f"{duration:.2f}")
print('结束录音')
stream.stop_stream()
stream.close()
p.terminate()
waveFile = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
waveFile.setnchannels(CHANNELS)
waveFile.setsampwidth(p.get_sample_size(FORMAT))
waveFile.setframerate(RATE)
waveFile.writeframes(b''.join(frames))
waveFile.close
代码保存为automatic_recording.py运行程序4说一段话后停顿2秒我们可以得到路径为/mnt/output.wav的wav录音文件。
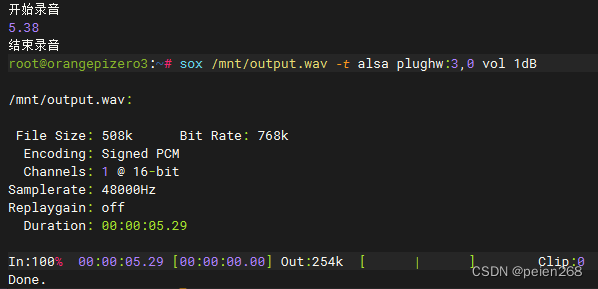
测试录音文件
我们通过命令sox /mnt/output.wav -t alsa plughw:3,0 vol 1dB播放上一步自动录音录制的音频,该命令意思是使用设备plughw:3,0(这里的设备来源于代码1查询的结果)以1dB的声音增益播放/mnt/output.wav音频,可以通过vol参数提高播放的音量。播放录音效果(见图8)。
语音识别
得到录音文件后接下来我们需要使用语音识别来将音频转换为文字,这里我们使用腾讯云语音识别(提前注册腾讯云并开通语音识别服务,腾讯云每个月赠送了5000次免费API调用次数,对于学习足够)腾讯云语音识别代码见程序5。
程序5
import json
import base64
import os
from tencentcloud.common import credential
from tencentcloud.common.profile.client_profile import ClientProfile
from tencentcloud.common.profile.http_profile import HttpProfile
from tencentcloud.common.exception.tencent_cloud_sdk_exception import TencentCloudSDKException
from tencentcloud.asr.v20190614 import asr_client, models
try:
# 实例化一个认证对象
cred = credential.Credential("AKIDve7i8ML5ZnlTv73kBMHvKTLwGLBlxxxx", "SebIjvrYy94j8HAnAH8j49zav0qPxxxx")
# 实例化一个http选项
httpProfile = HttpProfile()
httpProfile.endpoint = "asr.tencentcloudapi.com"
# 实例化一个client选项
clientProfile = ClientProfile()
clientProfile.httpProfile = httpProfile
# 实例化要请求产品的client对象,clientProfile是可选的
client = asr_client.AsrClient(cred, "", clientProfile)
# 实例化一个请求对象
req = models.SentenceRecognitionRequest()
# 读取 WAV 文件内容并进行 base64 编码
with open("/mnt/output.wav", "rb") as wav_file:
wav_content = wav_file.read()
encoded_content = base64.b64encode(wav_content).decode('utf-8')
# 准备参数字典并设置音频数据和长度
params = {
"ProjectId": 0,
"SubServiceType": 2,
"EngSerViceType": "16k_zh",
"ConvertNumMode": 0,
"SourceType": 1,
"Data": encoded_content,
"DataLen": os.path.getsize("/mnt/output.wav"),
"VoiceFormat": "wav"
}
# 将参数传递给请求对象
req.from_json_string(json.dumps(params))
# 发起请求并输出结果
resp = client.SentenceRecognition(req)
print(resp.to_json_string())
except TencentCloudSDKException as err:
print(err)
代码保存为tencentcloud_speech_recognition.py运行程序5将程序4中录制的音频转换为文字。语音识别效果(见图9)。

在国内大语言模型如雨后春笋般冒出来后,我第一时间体验了如文心一言、通义千问、Kimi等平台,在对其响应速度,使用难易程度进行综合考虑后我选择了Kimi大语言模型,我们访问其官网注册账号并开通服务后会得到一个API Key,查看Kimi开发文档我们可以得到其API请求方式,下面程序6就是Python请求Kimi的使用例子。
程序6
import requests
url = 'https://api.moonshot.cn/v1/chat/completions'
headers = {
'Authorization': 'Bearer sk-WYhx1E1zaLD8PQQPn1IzbDIMQC1bW5XOnNZCyT6N95Bvxxxx',
'Content-Type': 'application/json'
}
payload = {
"model": "moonshot-v1-8k",
"messages": [
{
"role": "system",
"content": "你是 Kimi,由 Moonshot AI 提供的人工智能助手。"
},
{ "role": "user", "content": "你是谁"}
],
"temperature": 0.3
}
response = requests.post(url, headers=headers, json=payload)
# 输出服务器的响应状态码和内容
print(response.status_code)
print(response.json())
代码保存为kimi.py运行程序6我们便可以得到Kimi的问题响应(见图10)。
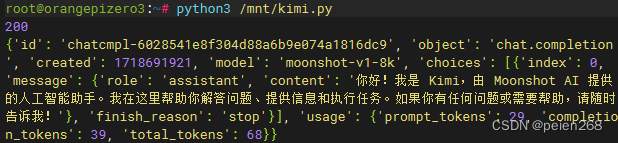
我们解析获响应的json字符串提取出其中的content键值便得到了我们问题的答案。
语音合成
语音合成又称为TTS可以将文本转换为语音,国内的各大厂如腾讯、百度、讯飞等均提供了TTS的服务,感兴趣的小伙伴可以自行去了解。我们知道微软的Edge浏览器可以语音合成,正好有edge_tts这个python库文件可以实现Edge浏览器的TTS功能,这里我们秉承着能省就省的原则“白嫖”微软的这个服务,微软语音合成pyhon程序如程序7所示。
程序7
import argparse
import asyncio
import edge_tts
DEFAULT_TEXT_FILE = '/mnt/tts.txt'
OUTPUT_FILE = "/mnt/test.mp3"
async def _main(text=None, voice="zh-CN-XiaoyiNeural") -> None:
if text is None:
with open(DEFAULT_TEXT_FILE, 'r', encoding='utf-8') as f:
text = f.read()
communicate = edge_tts.Communicate(text, voice)
await communicate.save(OUTPUT_FILE)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Text-to-Speech Program")
parser.add_argument("--text", type=str, help="Text to be synthesized")
parser.add_argument("--voice", type=str, help="Voice for synthesis", default="zh-CN-XiaoyiNeural")
args = parser.parse_args()
asyncio.run(_main(text=args.text, voice=args.voice))
代码保存为edgetts.py,ssh运行python3 /mnt/edgetts.py --text "世上无难事,只怕有心人。" --voice "zh-CN-XiaoyiNeural"命令将使用zh-CN-XiaoyiNeural发音人合成出我们指定text参数的音频保存到/mnt/test.mp3路径,注意当我们语音合成的文本过长时将其保存为tts.txt文件再进行合成。
Nodered使用
到这里我们已经成功解决了智能音箱的语音唤醒、语音识别、对话和语音合成等关键技术。接下来,我们需要将这些独立的功能整合起来。我们可以简化智能音箱的工作流程,如图11所示。
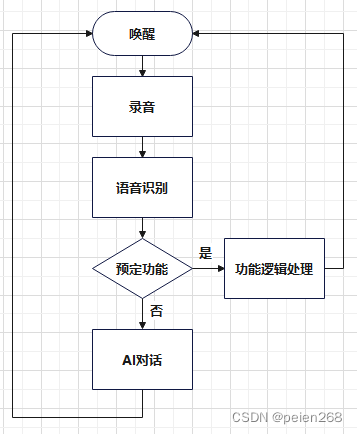
当我们唤醒设备后我们说出的话将转换为文本进入到预定功能判断,其作用就是对事先定义的关键词(例如开灯、关灯、房间温度是什么等)做匹配,这类关键词匹配后的逻辑处理与控制或者语音输出都属于自定义技能范畴,非定义的关键词将作为大语音模型的对话语料。那么我们要如何有机结合各服务并处理呢?答案就是使用Nodered。Nodered就像一个”万能胶水“一样,它用于可视化编程和自动化,可以连接各种硬件设备、API 和在线服务。Nodered整合各个服务的流程如图12所示。
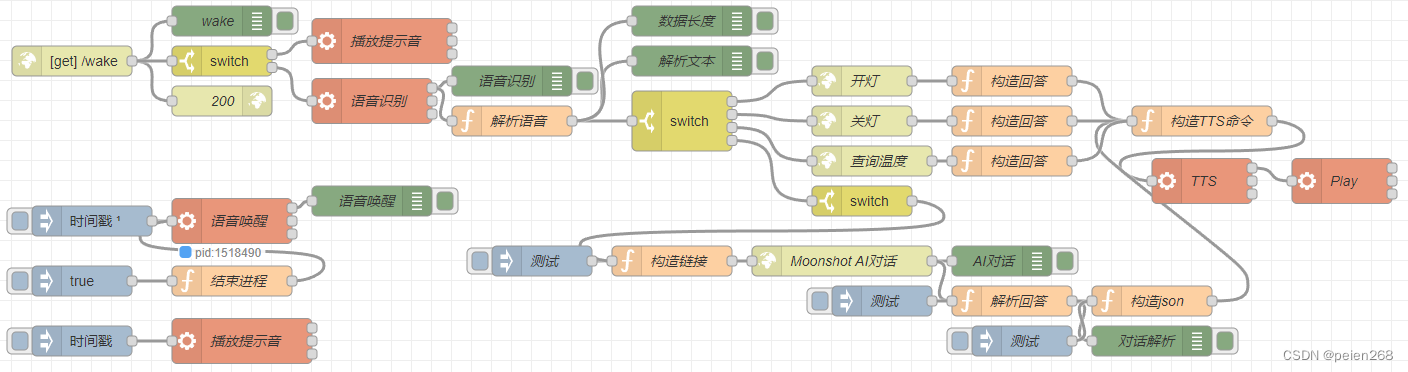
这里我们将语音唤醒与录音进行合并,Nodered运行后语音唤醒脚本自启,当设备唤醒后分别发送唤醒、开始录音与结束录音状态到wake节点,switch节点判断状态播放提示音或者识别语音,语音识别后将文字解析出来进入switch自定义功能逻辑判断,根据不同意图执行对应服务并根据结果构造语音回复指令播报。利用该方法我们可以在switch自定义功能逻辑判断中添加任意技能关键词,从而实现完全功能自定义的个人专属智能音箱。
展望与总结
本教程从一个智能音箱基本原理开始一步步循序渐进使用python代码实验方式进行了语音唤醒、语音识别、语音合成与大语言模型对话等功能,在这里我们没有展示如何安装python库的步骤,项目中用到的python库,大家需要自行使用pip进行安装,项目中用到的python代码与Nodered安装与流程等均放教程附件供大家进行下载学习。对于自定义的技能来说其本质就是关键词匹配然后执行对应的处理逻辑后输出回复语。对于固定回答的语音是固定的,如果我们每次都重新生成语音那么就会导致语音回复“滞后”,对于这种情况我们可以用固定的音频来回答,这样能够更加快速的响应逻辑并且回复,这是对项目优化的一个方向。对于我们这个项目来说每次添加新的技能都需要去增加switch的判断项,且关键词必须是固定的,如果我们说了类似的关键词,那么会进入到大语言模型对话逻辑去,这明显不符合我们的预期,那么我们能不能将语音识别文字直接输入大语言模型,,让它来自动判断我们的意图呢?还有我们项目思维导图中,语音唤醒还可以用天问51的离线语音识别模块结合香橙派的26Pin扩展功能来唤醒设备,这种方式和现在的唤醒对比有何优缺点?这些问题就留给大家活跃思维,思考一下如何改进与优化本项目。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











