






写在前面
这是第二次参加Datawhale的组队学习活动,非常感谢遇到这个平台,让我开始系统地去学些什么,而不是漫无目的地到处学点皮毛。
这次的学习内容是:Python爬虫编程实践,学习目的:
- 掌握基础的爬虫知识,并转换为未来的一些实用技能(嗯哼
- 借机消化之前拉勾教育活动时买的《52讲轻松搞定网络爬虫》
学习笔记
首先几个思维导图(来源:公众号:数林觅风 ),看完北理嵩天教授-《Python网络爬虫与信息提取》(B站链接、MOOC链接),再结合这个思维导图复习,再好不过,估计思维导图的作者也是上了这个课的,内容基本吻合。
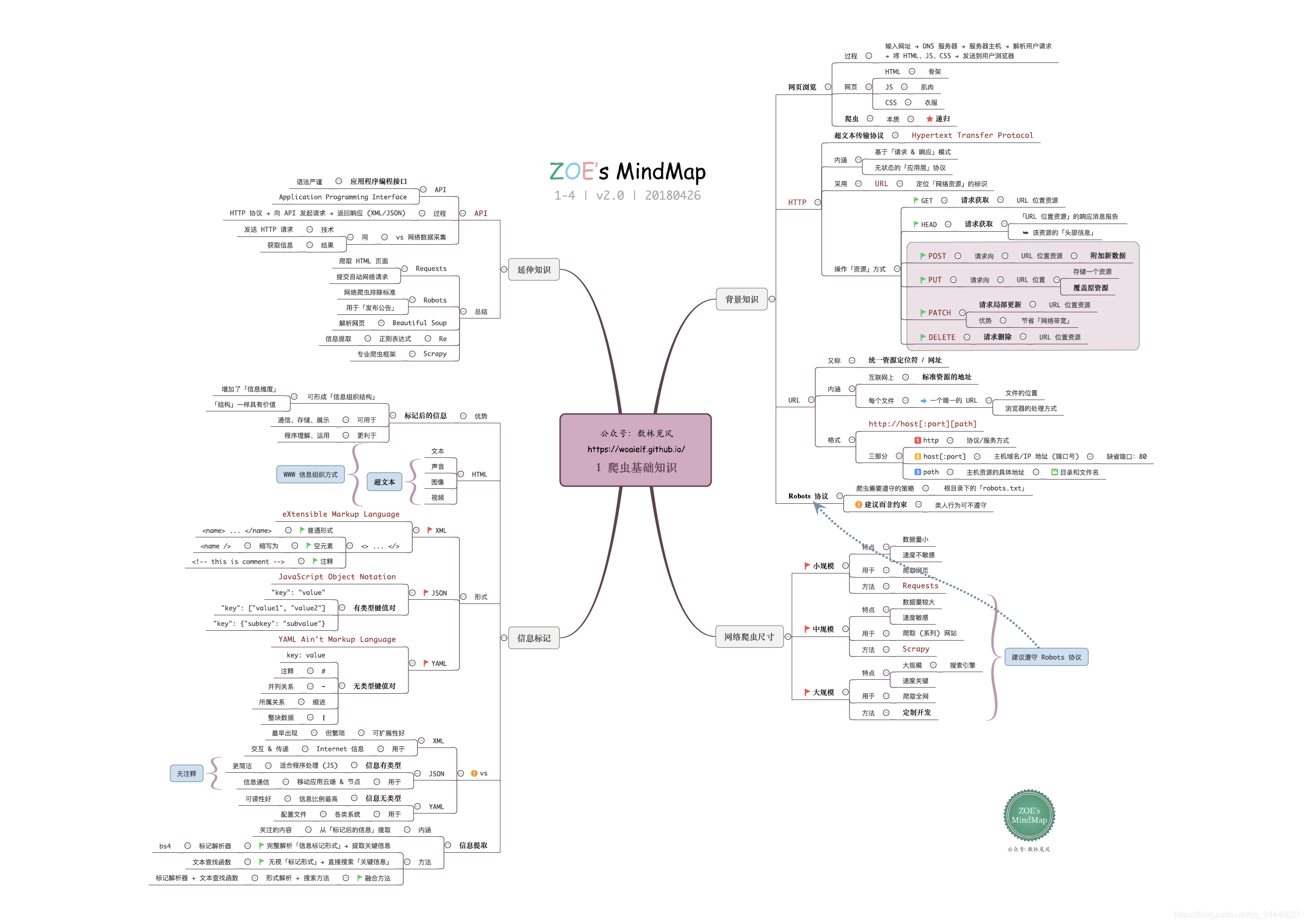
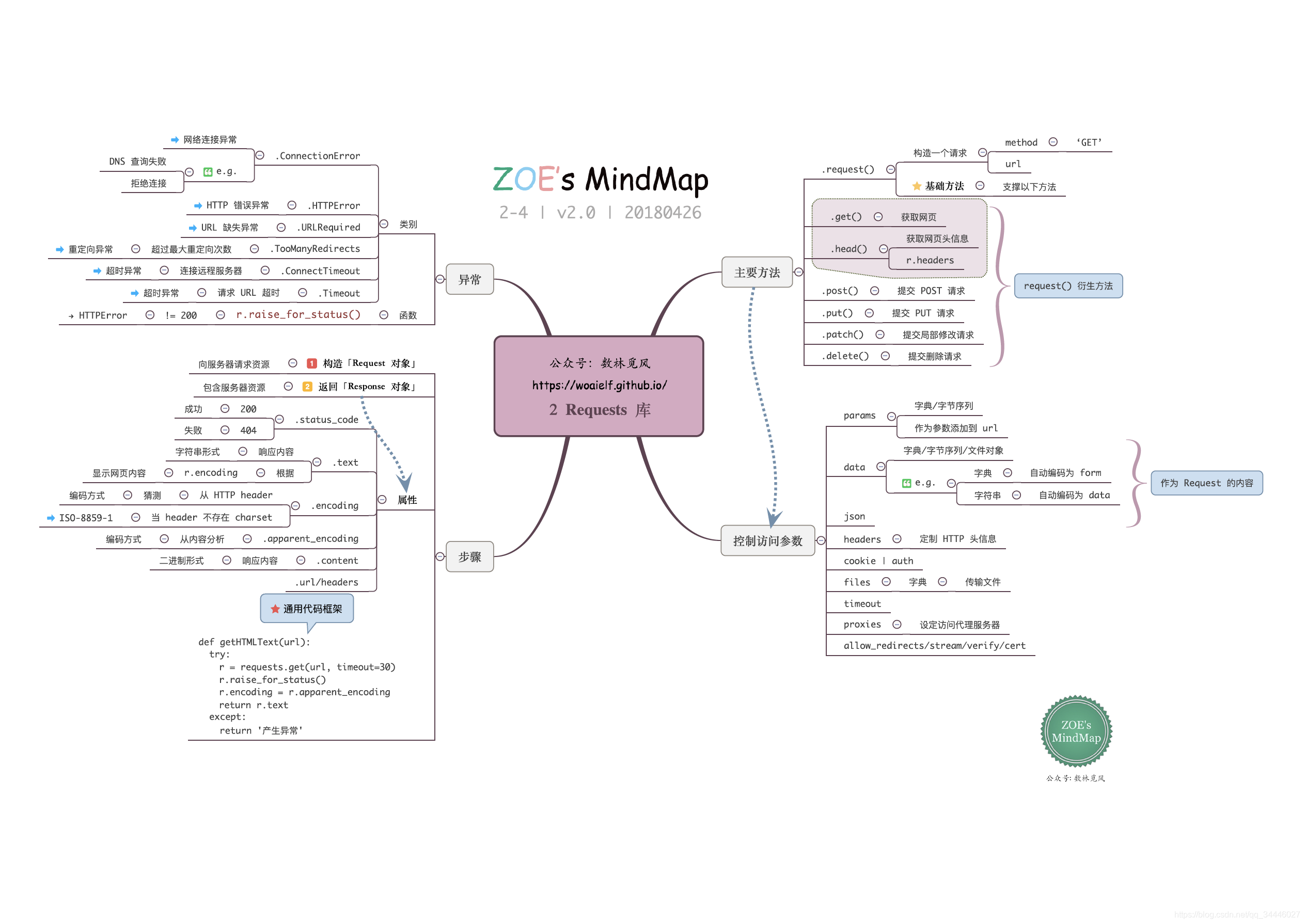
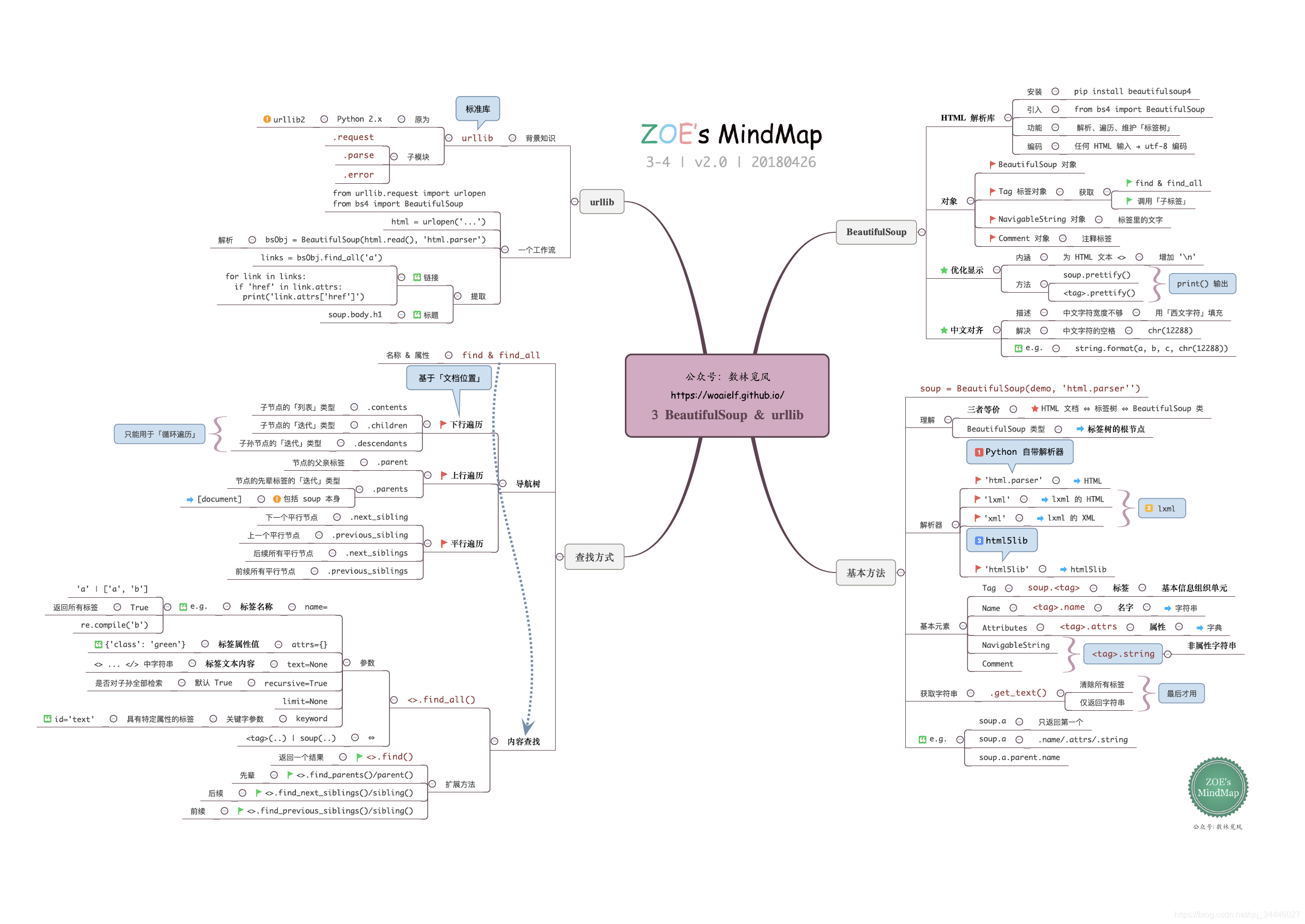
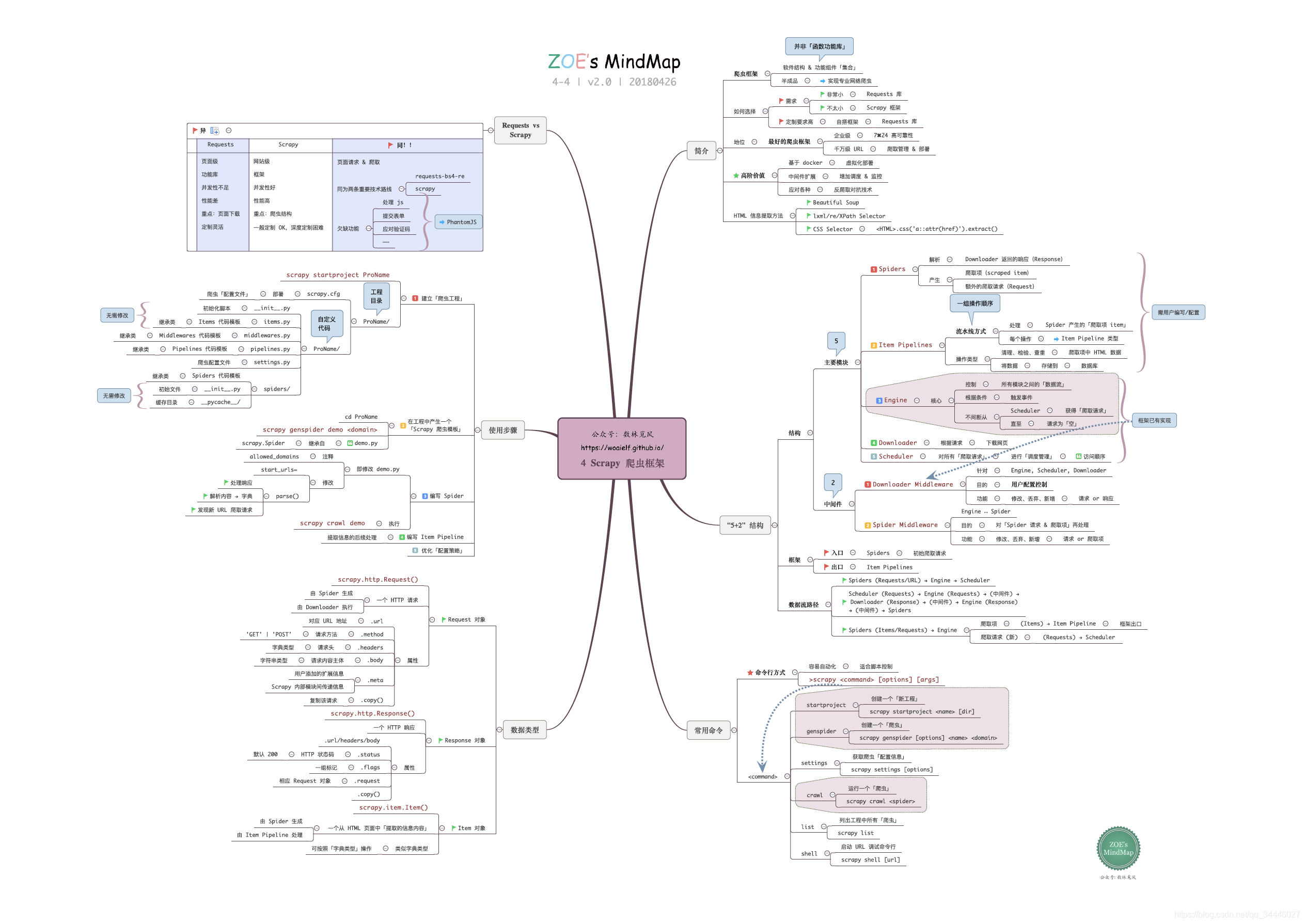
另外:
requests中文文档
bs4中文文档
学了一堆基础知识,当然少不了实践.
首先,爬取豆瓣top250电影名称(感觉豆瓣就是用来做爬虫实战demo的,哈哈)
参考:某大大CSDN博客的爬虫部分,当然是选择Ctrl+C/V!然后:
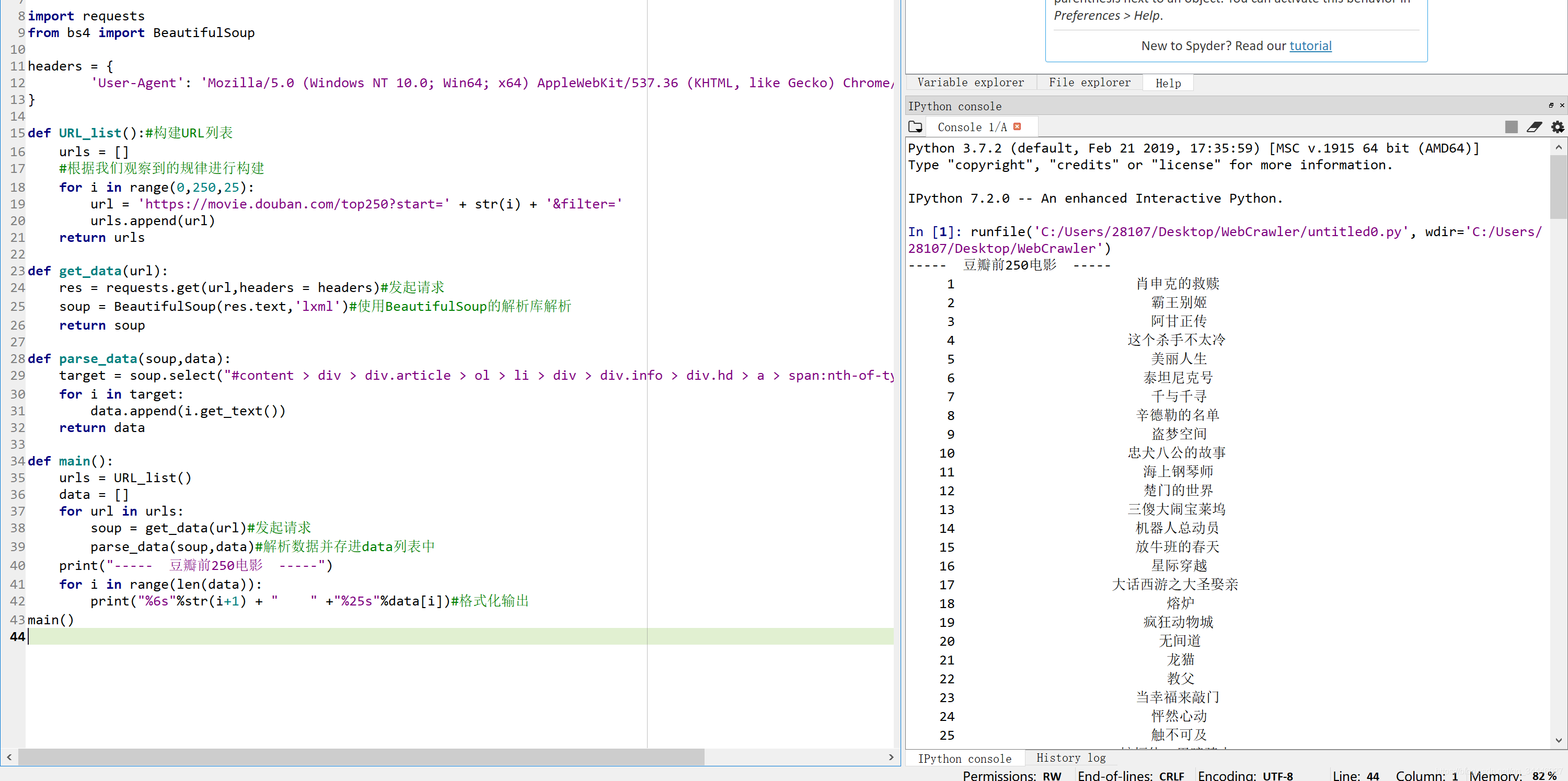
以上是用requests+bs4的实现,基本上就是三步走:
- 从网页上获取数据
- 存储到合适的数据结构
- 展示结果
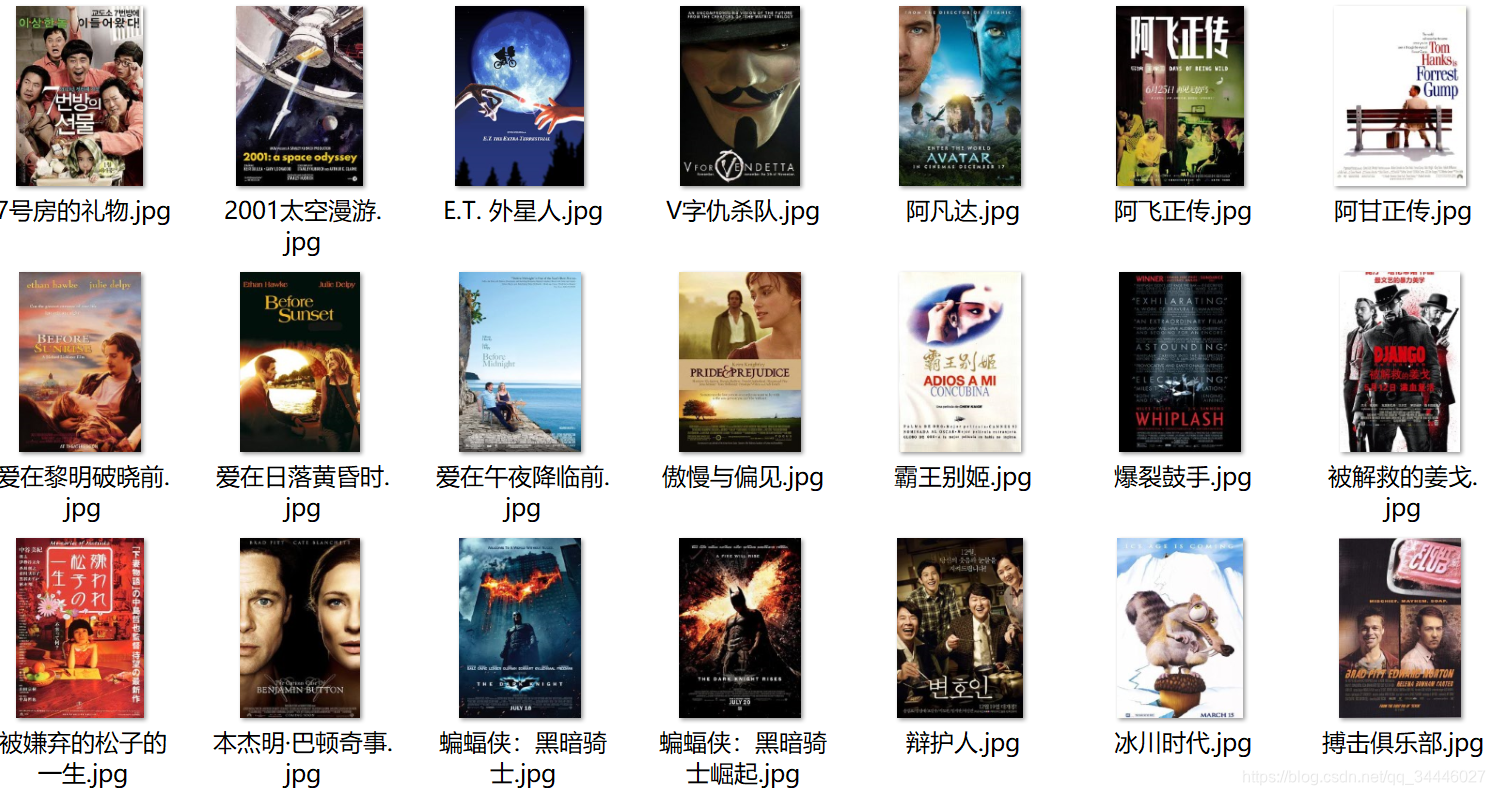
然后,爬取豆瓣top250电影海报,参考Datawhale提供的代码:
import requests
import os
if not os.path.exists('image'):
os.mkdir('image')
def parse_html(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"}
res = requests.get(url, headers=headers)
text = res.text
item = []
for i in range(25):
text = text[text.find('alt')+3:]
item.append(extract(text))
return item
def extract(text):
text = text.split('"')
name = text[1]
image = text[3]
return name, image
def write_movies_file(item, stars):
print(item)
with open('douban_film.txt','a',encoding='utf-8') as f:
f.write('排名:%d\t电影名:%s\n' % (stars, item[0]))
r = requests.get(item[1])
with open('image/' + str(item[0]) + '.jpg', 'wb') as f:
f.write(r.content)
def main():
stars = 1
for offset in range(0, 250, 25):
url = 'https://movie.douban.com/top250?start=' + str(offset) +'&filter='
for item in parse_html(url):
write_movies_file(item, stars)
stars += 1
if __name__ == '__main__':
main()
结果:
写在最后
其实还有部分内容没学,如:
- HTML、API、JavaScript等,后期填坑吧。
再次感谢Datawhale的付出,顺便感慨一下那些学有余力的大佬真是让人景仰。














 916
916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









