






为什么分类问题不能用均方误差(MSE)而用交叉熵
1. 从最优化的角度
MSE 函数对于一个输出范围是的数来说是凸的(标准的u型),而分类问题通常会接sigmoid或softmax,它的输出范围为。会导致损失函数变成非凸函数,有多个极值点。
2.从梯度的角度
使用MSE作为损失函数,MSE对参数的偏导受sigmoid导数的影响,会造成梯度不稳定;而CE对参数的偏导没有受到激活函数导数的影响,保证了梯度的稳定。
对均方误差损失函数而言,要得到稳定的梯度,输出不能经过激活函数,这样的情况只有线性回归,所以SE较适合做回归问题。
交叉熵与相对熵(KL散度)的关系
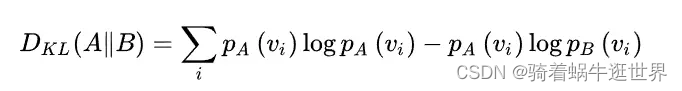
即A和B的KL散度=A的熵-AB的交叉熵,在机器学习中,训练数据的分布是固定的,因此最大化相对熵(KL散度)等价于最小化交叉熵

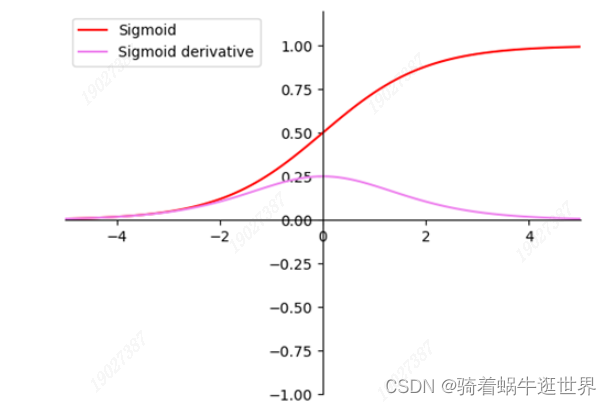

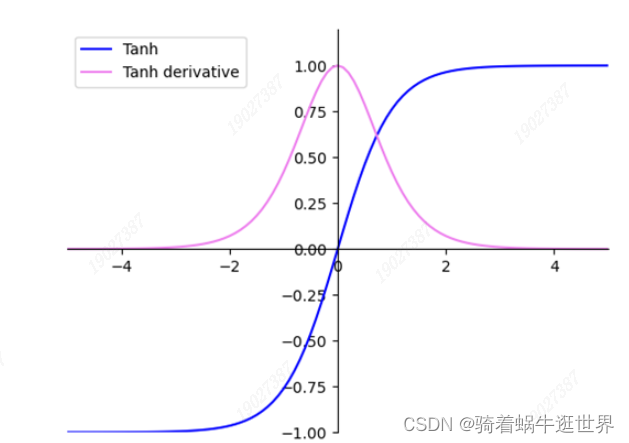
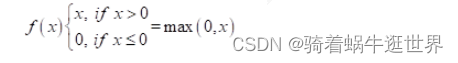
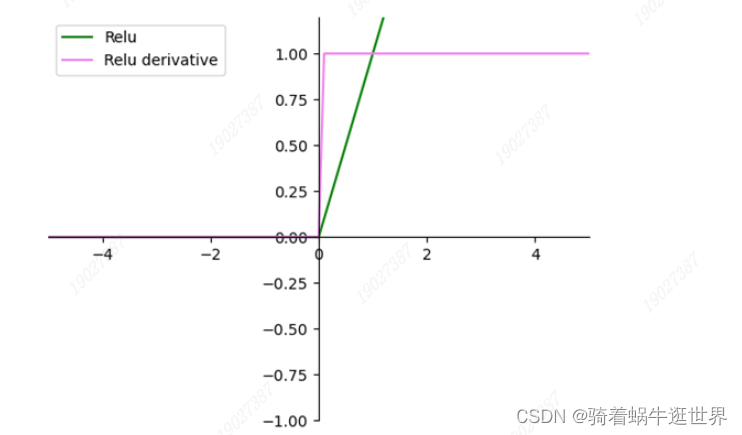

softmax激活函数通过指数函数加大差距
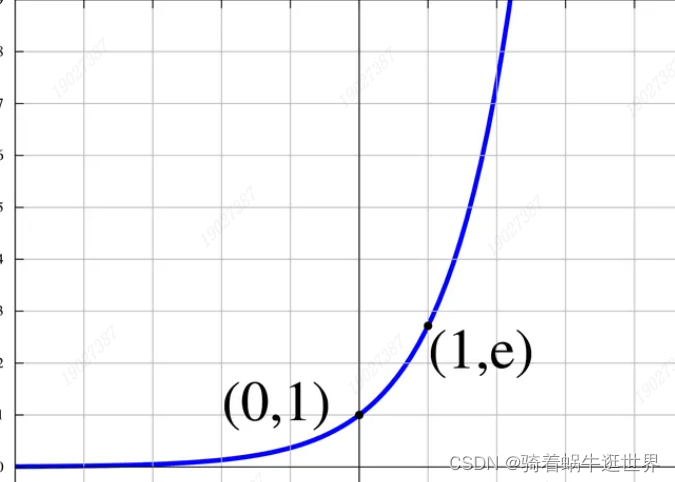
差距过大时,内存溢出

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









