







这里写目录标题
java基础入门–上
java 背景知识
Sun公司研发 ---- Oak 面向对象语言
java之父 詹姆斯 高斯林 java 创始人之一
1991 年Oak 语言诞生
1995 年 Oak 更名叫 java
2009 年 Sun公司被甲骨文公司收购
java 语言的特性
程序运行步骤:编译程序,编译文件,运行程序
动态: 变量在定义时无需指定类型
静态: 变量在定义时需要指定类型
强类型: 先定义后使用 不能中途更改类型
弱类型: 根据上下文判断数据类型,可以随时更改数据类型
编译型语言: 通过编译器编译成机器码,指定平台可以直接使用
解释型语言: 通过解释器对源码动态解析,安装运行工具,即可以执行
内存分析
- 程序计数器:记录当前执行行数
- 方法区/静态区:存放静态代码,方法
- 本地方法栈:存放本地方法(native)给栈内存提供方法
- 虚拟机栈/VM栈/栈内存:执行代码
- 栈空间:栈内存,以栈数据结构为模型的一小段数据空间(弹夹)
- 栈帧:栈空间内的元素。(弹夹的子弹)
- 栈底元素:栈空间内最下面的栈帧
- 栈顶元素:栈空间内最上面的栈帧
- 压栈:向栈空间放入栈帧的过程
- 弹栈:从栈空间弹出栈帧的过程
- 先进后出
- 堆区/堆内存:保存对象
- 运行机制
- javac编译代码成.class文件
- 代码,先被加载到静态区
- 栈内存会自动调用main方法===把main方法压栈
- 如果说main方法里面不再调用其他方法,直接弹栈main(销毁),程序结束
- 如果说main方法里面有其他的方法,继续压栈其他的方法。
- 然后依次运行,依次弹栈,最终弹出main,程序结束。
对象内存图
| 方法区 | 加载类的时候,这个类的字节码文件会进入内存图(临时) |
|---|---|
| 对象内存原理 | |
| 加载class文件 | |
| 申明局部变量 | |
| 为new堆内存开辟空间 | |
| 默认初始化 | |
| 显示初始化 | |
| 构造方法初始化 | |
| 将堆内存的地址赋值给左边局部变量 |
变量和常量
常量的使用:
作用:作为系统配置信息,方便维护
用 final 修饰 不可以改变的
命名规范:常量的命名都大写,单词与单词之间用下划线隔开
final int A = 10;
变量的使用:变量相反就是可以被修改的 关键词 变量名 = 变量值
变量拥有就近原则
int a = 10;
- 局部变量:在方法内部声明的变量,只能在本方法内部使用
- 静态变量:在类体中被static修饰的变量。在本类中使用,可以忽略类名,调用,类名 . 变量
命名规则
| Java 严格区分大小写 | |
|---|---|
| 只能包含大小写字母,数字,下划线,美元符号$ | |
| 数字不能开头 | |
| 不能使用关键字和保留字(goto , const) | |
| 规范 | 使用驼峰命名法:(单词的第一个字母大写) |
| 类名使用大驼峰:HelloWord | |
| 方法名,变量名使用小驼峰: hellwWord | |
| 变量:使用小驼峰 |
类型转换 变量详解 运算符
数据单位 byte详解
介绍: byte,即字节,由8位的二进制组成。在Java中,byte类型的数据是8位带符号的二进制数。
1bit(位) = 1 位
1 byte(字节) = 8 位
那么 1111 1111 = 255
但是 java 中 第一位是符号位
1 代表负数 0 代表正数
一共八位,那么 0 111 1111 那么现在第一位0 就代表这是一个正数,因为符号位的出现这个值等于
0 111 1111 = 127
所以 byte 的最大值是127
负数在计算机里是以补码的形式存储的
1 000 0010 = 也就是(原码) 需要转换反码,在转换成补码
反码:符号位不变 0变1 1变0 最后 + 1
1 111 1101 反码
1 111 1110 补码 +1
进制
二进制 用 0b 开头
int i = 0b0010;
八进制 用数字 0 开头
int i = 020;
十进制直接写
十六进制用0x表示
A 表示10 以此类推~~~~
int i = 0x9C;
数据的分类
| 引用数据类型 | 类 接口 数组 |
|---|---|
| 基本数据类型 | |
| 整型 | byte 字节 = 8 bit 位 |
| short 短整型 = 16 bit位 | |
| int 整型 = 32 bit 位 | |
| long 长整型 = 64 bit 位 | |
| 浮点型 | float 单精度 = 32 bit 位 |
| double 双精度 = 64 bit 位 | |
| 字符型 | char 字符型 = 16 bit 位 |
| 布尔型 | boolean = 8 bit 位 |
| true: 0000 0001 | |
| false: 0000 0000 |
注意点:
- byte取值范围-128~127
- int取值范围 -2147483648~2147483647
- long 定义的变量超过int的范围,要在变量值后加L
- float 定义的变量超过float的范围,要在变量值后加F
- char 字符型没有符号位,最大值65535
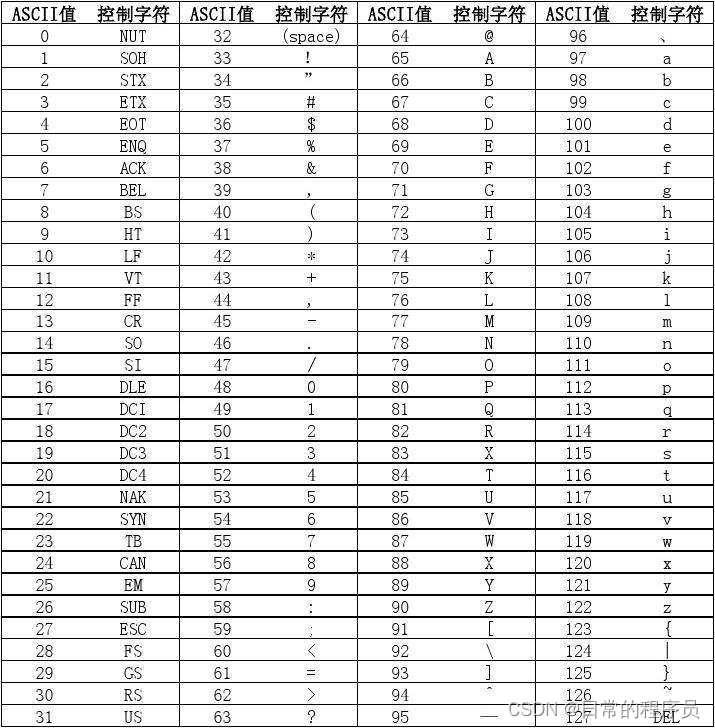
字符类型
char i = 97
ASCll表 对应值 a 是 97
打印 i 就是 a
Boolean 布尔值
布尔值只有 true(真) 和 false(假)
布尔值不参与计算
转义符 \
| ’ \ ’ ’ | 把 ’ 转义成没有意义的字符 |
|---|---|
| ’ \t ’ | 制表符 打印的时候把前面的字符长度,补齐至八位或者八的倍数 |
| ’ \n ’ | 换行符 |
类型转换
| 自动类型转换 | 在整型中低字节到高字节 |
|---|---|
| 浮点型中低精度到高精度 可以自动转换,比如 |
char s1 = 'a'; // a 的 ascll 是 97
int j = s1;
System.out.println(j); // 输出 97
| 强制类型转化 | 高精度到低精度 |
|---|
// 定义一个 int整型
int s = 200;
// 强制转换成byte
byte aa = (byte)s;
注意: 强转可以导致数据丢失,错乱
算术运算符
自增运算 i++ --i
自减 i-- 同理
int i = 0;
i++;
// 这个时候是 1
System.out.println(i);
// 因为i 是在 ++ 的前面 所以i先打印在自增
System.out.println(i++);
// 因为i 是在 ++ 的后面 所以i先自增后打印
System.out.println(++i);
关系运算符
< > == <= >= !=
逻辑运算符
& | ! ^ && ||
| ^ 异或 | 转换为二进制比较----两个相同为true 1 不相同为false 0 |
|---|---|
| && 短路与 | 有一个为false 则为false,后面不执行 |
| || 短路或 | 有一个为true则为true,后面不执行 |
赋值运算符
= += -= *= /=
位移运算符
<< >>
三目运算符
表达式 ?值1 : 值2
如果表达式为 true 则取 值1 为 false 取值 2
int a = 1, b = 10;
System.out.println(a > b ? "1000" : "2000");
拼接
System.out.println(12 + 20 + "dd");
以上输出的是32dd
因为,算术运算符从左计算,10 + 20 == 32,然后拼接字符串
那把字符串写在最左边就是dd1220
流程控制
if语句
if( 表达式 ){
语句1;
}else if(表达式2){
语句2;
}else{
语句3;
}
如果成立,则执行语句1,否则如果执行语句2,如果都不成立则执行语句3 (只会执行一个)
细节:else 语句可省略,else 语句会自动匹配最近的 if 语句
else if 可以写多个 else 只能有一个或者没有
如果 if 语句后面的大括号省略了,那么只能控制距离它最近的那一条语句
switch 语句
switch (表达式){
case 值:
语句体1; break;
case 值:
语句体2; break;
default:
语句体;
}
用法:当switch表达式的值等于后面case的值时,就会执行case后面的语句体
default 当所有值不匹配时执行
细节: 如果case语句体没有break(跳出当前循环),就会一直执行
也就是case穿透
for 循环
介绍:循环执行一段语句
for(初始变量;终止条件;条件控制语句){
语句体;
}
细节:初始变量 终止条件 条件控制语句; 都可以省略,后面的分号不可以
while 循环
介绍:循环执行一段语句,最基本的循环,控制语句都要自己写
while(条件判断语句){
语句体;
}
do while 循环
介绍:它与前两个不同,它是先执行一次,再判断条件成立不成立
do{
语句体;
}while (条件判断语句);
break 跳出当前循环
continue 跳过本次循环,执行下一次
while(条件判断语句){
语句体;break; continue;
}
键盘录入
需要导包Import java.util.Scanner
| 创建对象 | Scanner 变量 = new Scanner(System.in) |
|---|---|
| 变量.nextInt() | 录入整数 |
| 变量.nextLine() | 录入字符串(会自动换行) |
| 遇到制表符以及空格不会结束录入 |
随机数
Random r = new Random();
int i = r.nextInt();
数组
数据结构:计算机存储、组织数据的方式
注意点:数据类型前后必须保持一致,数组一旦创建长度不能发生改变
// 静态声明
数据类型[] 数组名 = {值,值 }
// 动态声明
数据类型[] 数组名 = new 数据类型[长度]
获取数组长度:数组名 . length
常见错误:
下标越界:ArrayIndexOutOfBoundsException
空指针: NullPointerException
方法传值和传址
传值指的是基本数据类型
传址指的是引用数据类型
传值:不会修改主方法里面的变量
public static void main(String[] args) {
int a = 10;
getsum(a);
System.out.println(a);
}
private static void getsum(int a) {
a = a + 10;
}
传址:会修改主方法里面的引用数据
public static void main(String[] args) {
int[] a = {1,2,3};
getsum(a);
System.out.println(a[0]);
}
private static void getsum(int[] a) {
a[0] = 50;
}
方法
方法必须先创建才可以使用,必须手动调用
public 公开的
static 静态的
public static 返回值类型 方法名(参数1, 参数2) {
语句体;
}
// 方法的调用
方法名( );
细节:
1. 方法调用时,参数的数量、顺序和类型必须与定义时相匹配,否则报错
2. 方法不能嵌套定义
3. void 的可以省略 return
构造方法
| 构造方法 | 用来初始化类的一个对象 |
|---|---|
| 方法名必须和类名相同 | |
| 没有返回值类型 | |
| 创建对象时是虚拟机调用的,无法手动调用给成员变量赋值 | |
| 每创建一次就会调用一次构造方法 | |
| 如果没写,虚拟机会创建空参 | |
| 规范 | 有参构造和无参构造都手动创建 |
返回值
public static int 方法名(参数1, 参数2) {
语句体;
return 1; // 是根据返回值类型 int 类型,如果是float 就要返回一个小数
}
// 方法的调用
int a = 方法名( ); // 此时 a 就等于 1
方法重载
介绍:指同一个类中,定义多个方法之间的关系
重载条件:
1. 多个方法在同一个类中
2. 多个方法具有相同的方法名
3. 重载只对定义有关,重载识别的是 参数的位置,类型,个数
public static void main(String[] args) {
sum(1);
sum(1, 2);
}
// 方法 1 和 方法 2 ,就少了一个参数,就没有报错,实现方法重载
private static void sum(int i) {
}
private static void sum(int i, int j) {
}
递归
介绍:就是方法本身调用自己,必须要设置终止条件,要不然会内存溢出报错
面向对象
对象的三大特征:继承、多态、封装
链式编程:调用方法的时候不需要考虑结果,可以继续调用方法
所有的包装类都都覆写了equals和hasCode方法,toString方法
打印一个引用数据类型实际上就是调用他的toString方法
| 面向过程 | 核心是分步骤、流程 |
|---|---|
| 带main方法的类 | 测试类 |
| JavaBean类 | 专业类 |
| 面向对象 | 核心分模块 |
| 构造器 | 创建对象 |
| 没有返回值类型,方法名和类名相同 | |
| 构造器注意点: | 默认有一个无参构造,如果写了任何一个构造方法 |
| 那么默认的无参构造就没了 | |
| 类 | 很多个对象的集合 |
| 对象 | 某一个类的具体个体 |
| 成员变量和静态变量的区别 | |
|---|---|
| 定义上:static | |
| 用途:静态直接使用,成员需要创建对象 | |
| 静态方法和成员方法的用法 | 静态方法不允许直接使用成员变量 |
| 使用要创建对象 | |
| 静态方法中不允许直接使用成员方法 | |
| 使用要创建对象 | |
| 成员方法可以调用其他成员方法和成员变量 |
| 类的组成 | 由属性和方法组成 |
|---|---|
| 属性 | 在类中通过成员变量来体现 |
| 方法 | 在类中通过成员方法来体现 |
public class 类名 {
// 成员变量
修饰符 数据类型 变量名;
修饰符 数据类型 变量名;
//·····
// 成员方法
方法1;
方法2;
对象的使用
//创建对象的格式:
类名 对象名 = new 类名();
//调用成员的格式:
对象名.成员变量;
对象名.成员方法();
成员变量和局部变量的区别
| 类中位置不同 | 成员变量在类中方法外 |
|---|---|
| 局部变量在方法内或者在方法声明上 | |
| 内存位置不同 | 成员变量在堆内存,局部变量在栈内存 |
| 生命周期不同 | 成员变量随着对象的存在和消失 |
| 局部变量随着方法的调用而存在和消失 | |
| 初始值不同 | 成员变量有默认值,局部变量没有默认值 |
封装 private
介绍:对象代表什么,就封装成相应的数据,并提供数据对应的行为,将类的某些信息隐藏在内部,不允许外部程序直接访问,而是通过方法来实现隐藏信息的操作和访问
成员变量 private 提供 get 和 set 方法
private是一个修饰符,可以用来修饰成员(成员变量,成员方法)
被private修饰的成员,只能在本类进行访问,如果需要被其他类使用,提供 get 和 set 方法
- 提供“get变量名()”方法,用于获取成员变量的值,方法用public修饰
- 提供“set变量名(参数)”方法,用于设置成员变量的值,方法用public修饰
package 包
| 作用 | 就是文件夹,管理不同的类 |
|---|---|
| 书写规则 | 公司域名的反写 + 包的作用,需全部小写 见名知意 |
| 全类名 | 包名 + 类名 |
| 什么情况下导包 | 使用java . Lang的情况下不需要 |
| 使用同一个包中的类不需要 | |
| 其他情况都需要 | |
| 如果两个同名的包,需要使用全类名 | |
| 注意事项 | 在同一个包内不能创建同名的文件 |
| 在每个java文件的第一行 |
import 导入
- 导包中的每个类
- .* 导包中的所有类,所有都可以使用
- static可以直接引用每个类中公用的静态属性
final 最终的
| final | 修饰的代码,无法被二次修改 |
|---|---|
| final 修饰的量 | 无法第二次赋值 叫常量 |
| final 修饰的方法 | 不能被重写 |
| final 修饰的类 | 不能被继承 |
| final修饰的方法 | 表示最终方法,不能被重写 |
| 注意事项 | final修饰的基本数据类型值不可以修改 |
| final修饰的引用数据类型地址值不可以修改 |
权限控制
- public 公开的
- private 私有的
- protected 受保护的
- 不写 默认的
| 修饰符 | 同一个类中 | 同一个包中其他类 | 不同包下的子类 | 不同包下无关类 |
|---|---|---|---|---|
| Private | √ | |||
| 空着不写 | √ | √ | ||
| Protected | √ | √ | √ | |
| Public | √ | √ | √ | √ |
{
语句体;
}
静态代码块:只有在类加载的时候执行一次,存在多个自上而下执行
static {
语句体;
}
实例化代码块:每次创建对象的前执行,自上而下
{
语句体;
}
继承
介绍:继承可以让类与类之间产生关系,子类可以直接调用父类的方法和变量
格式:Public class 子类 extends 父类{}
细节:
1. java 只能单继承,不能多继承,可以多层继承
2. java 的所有类都直接或者间接继承Object
3. 子类不可以访问父类的私有类
4. 子类不可以访问父类的构造方法,构造方法,跟类有关系,继承过来名字不一样
细节:
画图法:从下往上画,把子类共同的特点抽取到父类中。
书写代码的时候从上往下写
super 调用父类的构造方法
可以调取父类的变量和方法,只能在继承中使用
方法重写
@override 注解:来校验重写语法是否正确
作用:重写父类方法,只是把虚拟机方法覆盖了
注意事项:
1. 重写的方法必须与父类一致
2. 返回值类型必须小于等于父类
3. 访问权限必须大于等于父类
虚拟方法表
继承过去的所有方法会产生虚拟方法表(能继承过来的才会产生)
非private非static非final
运行过程
流程:
1. 子类先访问父类的无参构造,再执行自己
2. 如果父类没有完成初始化,则无法使用父类的无参构造
3. super一定是在构造方法第一行,不写也是第一行。如果想使用有参构造,必须自己添加
4. 子类不能继承父类的构造方法,但是可以调用super
多态
多态是父类引用指向子类类型,发生在赋值的时候
缺点:丢失子类属性
前提:有继承实现的关系,有方法的重写
- 如果父类没有,不管父类有没有都报错
- 如果子类没有,父类有。调用父类的
- 如果父类有,子类也有,除了方法(因为重写),其他都是父类
优点:高内聚,低耦合
发生条件: - 直接赋值:
父类 p = new 子类(); - 形参实参方式:
public static void p(父类对象 对象名) p(子类对象); - 返回值类型:
return 子类对象 父类对象接收 - 隐式多态:子类对象调用父类的成员方法,此方法就多了一个多态环境(基本不用)
向上转型和向下转型
向上转型:多态
向下转型:instanceof
抽象类 abstract
格式:
Public abstract 返回值类型 方法名( 参数列表 )
Public abstract class 类名{}
细节:
- 抽象类不能实例化
- 有抽象方法一定是抽象类或者接口
- 可以有构造方法
- 抽象类的子类:要么重写抽象类中所有方法,要么是抽象类
- 被 abstract 修饰的方法是抽象方法
- 不能同时与其他修饰符一起修饰,public 除外
作用:抽取共性时,无法确定方法体可以使用抽象方法,强制让子类按照父类的格式重写
接口 interface
Public interface 接口名
接口的默认方法
public default 方法名(){
}
弥补了 java9 单继承的缺点
| 注意事项: | |
|---|---|
| 接口不能实例化,可以多态 | |
| 可以单实现,也可以多实现 | |
| 接口和类直接是实现关系 | |
Public class 类名 implements 接口1,接口2 | |
| 接口的子类(实现类) | 要么重写接口中所有的抽象方法,要么是抽象类 |
| 接口成员 | |
| 成员变量 | 只能是常量 |
| 默认是 public static final 静态永不改变 | |
| 构造方法 | 没有 |
| 成员方法 | 只能是抽象方法 public abstract |
| 类和接口的关系 | 可以在继承的同时实现多个接口 |
| 方法同名实现一次即可 | |
| 接口和接口的关系 | 可以多继承 |
| 如果实现类是继承多个接口的类需要全部重写 | |
| 接口默认方法 | 可以重写,可以不重写,需要接口多态实例化调用 |
| 静态方法 | 静态方法只能通过方法名字去调用 |
| 不能通过实现类对象等调用 方法不能被重写 | |
| 私有方法( java9 才有) | 普通的私有方法是给默认方法服务的 |
| 静态的私有方法是给静态方法服务的 |
总结:接口即使规则, 是行为的抽象, 要让谁拥有规则 , 就让这个接口实现
String
字符串对象,可以直接赋值
如果是new出来的对象,会存在地址值
重点:
字符串,底层就是一个字符数组
一旦长度确定,不能更改
java提供了一个常量池的概念,可以让String直接指向常量池,如果没有,则自动创建
StringBuild&StringBuffer
都是可变的字符序列(数组),长度不够会自动扩容
扩容原理:初始容量 = 16
当放满了就会自动扩容
公式:容量 = (原容量 + 1) * 2
StringBuffer:线程安全,速度慢,但是(线程)安全
StringBuilder:线程不安全,速度快,但是(线程)不安全
通用方法
| length() | 返回字符串长度 |
|---|---|
| capacity() | 返回当前最大容量 |
| append() | 向尾部添加(无需返回) |
| insert(a,b) | a是在哪个下标位置,b是添加什么(无需返回) |
| reverse() | 反转(可根据返回) |
类
| 类 | 一个java文件可以定义多个类,只能有一个类由public修饰 |
|---|---|
| 并且public修饰的类 类名必须和文件名一样 |
Object 类
所有的类都间接或者直接继承于Object类
- equals 方法
- ==
基本数据类型:比较两个值
引用数据类型:比较两个的内存地址 - equals 方法:用来比较两个对象
重写了,就按照重写的去比较
- ==
- finalize 方法
垃圾过多或者程序结束时,程序自动调用 finalize,回收垃圾
手动调用,没有意义 - toString 方法
打印自定义内容,默认打印对象地址值,需重写
实现克隆对象(浅克隆)
- 给想要克隆的对象,实现一个 Cloneable 接口,标志可以被克隆
public class User implements Cloneable{
- 重写clone方法,要 public 的,不然是无法调用的
@Override
protected Object clone() throws CloneNotSupportedException {
// 调用父类的方法,让java帮我们克隆一个对象,并把克隆的对象返回出去
return super.clone();
}
- 实现重写
// 对象克隆
// 1. 创建对象
User user = new User(1, "巧儿", "123456", "", new int[]{1, 2, 4});
// 2. 创建对象,由于clone是受保护的方法,子类肯定不能调用啊,需要重写
User clone = (User) user.clone();
System.out.println(clone);
注意内部的引用数据类型,只是拷贝的地址
实现深克隆,需要自己写逻辑
@Override
public Object clone() throws CloneNotSupportedException {
// 调用父类的方法,相当于让java帮我们克隆一个对象,并把克隆的对象返回出去
int[] data1 = this.data;
int[] ints = new int[data1.length];
// 数组copy
System.arraycopy(data1, 0, ints, 0, data1.length);
// 获取克隆出来的数组
User clone = (User) super.clone();
// 修改数据
clone.data = ints;
return clone;
}
类的关系
| 类与类之间的关系 | 继承,实现,依赖,关联,聚合,组合 |
|---|---|
| 成员内部类 | 成员变量,成员方法,构造方法,常量(不能静态) |
| 可以直接使用外部类成员变量,静态变量,常量,不管私有 | |
| 直接使用外部类成员方法,静态方法,构造方法,不管私有 | |
| 类的继承 | 可以单继承 不能多继承 可以多层继承 |
| 静态内部类 | 可以声明静态 |
| 静态内部类使用外部成员变量和方法,需要创建对象 | |
| 局部内部类 | 条件:外部是静态方法 |
| 不能定义静态变量和方法 | |
| 不能使用外部类的成员变量和方法 | |
| 条件:外部成员方法 | |
| 和成员内部类一样 |
成员内部类
| 写在一个类里面的类就是内部类,可以被修饰 | |
|---|---|
| 什么时候使用内部类 | B类事物是A类的一部分,且B类单独存在没有意义 |
内部类分类
| 成员内部类 | |
|---|---|
| 获取成员内部类的方式 | 在外提供内部类的对象 |
| 直接创建 | |
| 外部类名 . 内部类名 对象名 = 外部类名 . 内部类对象 | |
| 私有类怎么调用 | 创建方法返回该类 |
| 静态内部类 | 是一种特殊成员内部类 |
|---|---|
| 创建格式 | 外部类名 . 内部类名 对象名 = new 外部类名 . 内部对象 |
| 静态方法 | 外部类名 . 内部类名 . 方法名() |
| 成员方法 | 先创建对象,用对象调用 |
| 局部内部类 | 将内部类定义在方法里面就是局部内部类 |
|---|---|
| 外界无法直接调用 , 需要在方法内部创建对象并使用 | |
| 该类可以直接访问外部成员 , 也可以访问方法内的局部变量 |
匿名内部类
什么是匿名内部类?
隐藏了名字的内部类, 可以写在成员位置 , 也可以写在局部位置
匿名内部类的格式?
New 类名或者接口名(){
重写方法;
};
格式的细节?
包含了继承或者实现 , 方法重写 , 创建对象
整体就是一个类的子类对象或者接口的实现类对象
使用场景?
当方法的参数是接口或者类时
以接口为例 , 可以传递这个接口的实现类对象 , 如果实现类只要使用一次 , 就可以用匿名内部类简化代码
// 其中 new Ag这个包含下面就是匿名内部类
k1(new Ag(){
@Override
public void m1() {
}
});
包装类
java基本数据类型不具备对象的特征,所以java提供了包装类
| 基本类型 | 封装类型 |
|---|---|
| byte | Byte |
| char | Character |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| boolean | Boolean |
通用方法:
| . valueOf(); | 获取对象 |
|---|---|
| byte字节是自存,高于byte创建对象 | |
| 第一个值是 数值 字符串也可以 第二个是当前数值的进制位 | |
| 自动装箱子 | Integer i = 10; |
| 自动拆箱子 | int a = i; |
| . toBinaryString(10); | 整数转二进制 |
| . toHexString( 10 ); | 整数转十六进制 |
| . toOctalString(10); | 整数转八进制 |
| . parseInt(“123”); | 把字符串转为整数 |
BigDecimal 更大的数值
| 获取数值方式 | 创建对象直接输入 |
|---|---|
| 创建对象 | 输入字符串 |
| 创建对象 | 参数1 是BigInteger.valueOf(3),参数2 (整数或者负数) |
| 正数表示,缩小十的几次方,负数是扩大十的几次方 | |
| 创建对象 | 参数1 是BigInteger.valueOf(3),参数2 (进制数) |
| 正数表示,缩小十的几次方,负数是扩大十的几次方 | |
| 创建对象 | 参数1 是BigInteger.valueOf(3) |
字符串四舍五入
-RoundingMode.HALF_UP:四舍五入,前面的2表示保留两位
String string = new BigDecimal(字符串).setScale(2, RoundingMode.HALF_UP).toString();
Lambda 表达式
介绍:Lambda表达式可以用来简化匿名内部类的书写
格式:() 对应着方法形参
-> 固定格式
{} 对应着方法的方法体
// 未简化之前
method(new swim(){
@Override
public void swimming() {
}
});
// 简化之后
method(
()->{
System.out.println("ddd");
}
);
// 定义方法
public static void method(swim s) {
s.swimming();
}
// 这里是接口
interface swim{
public abstract void swimming();
}
/************/
// 错误演示
abstract class swim{ // 必须是函数式接口,这里已经不是接口了
public abstract void swimming();
}
省略写法:
- 参数的类型可以省略不写
- 如果只有一个参数,括号也可以省略
- 如果Lambda表达式的方法体只有一行,大括号分号return也可以省略,需要同时省略
Integer[] arr = {16, 5, 9, 12, 21, 18, 32, 23, 37, 26, 45, 34, 50, 48, 61, 52, 73, 66};
Arrays.sort(arr, (o1, o2) -> o2 - o1);
注意点:
1. 只能简化函数式接口的匿名内部类的写法
2. 函数式接口:有且仅有一个抽象方法的接口叫做函数式接口,上方可以加@FunctionalInterface(函数式接口标志)
3. abstract class修饰的方法不能使用Lambda 表达式
举个例子 Lambda 表达式
// lambda 排序
// 按照长度进行排序
String[] a = {"aa","aaaa","aaa","a"};
// 省略写法
Arrays.sort(a, (o1, o2) -> o1.length() - o2.length());
System.out.println(Arrays.toString(a));
集合体系(Collection)
单列集合List:添加的元素是存储有序、可重复、有索引的
双列集合Set:添加的元素是存储无序、不重复、无索引的
Collection(单列集合的接口,公共方法)
add 添加元素
// 创建实例化集合对象
Collection<String> c = new ArrayList<>();
// 向当前集合添加元素
c.add("aaa");
添加成功返回true,否则返回false
如果在单列集合添加永远为true,因为可重复
如果是在双列集合,不允许重复,返回值就可能返回false
clear 清空所有元素
// 创建实例化集合对象
Collection<String> c = new ArrayList<>();
// 清空当前集合所有元素
c.clear();
remove 删除集合当中的元素
// 创建实例化集合对象
Collection<String> c = new ArrayList<>();
// 删除当前集合aaa元素
c.remove("aaa");
删除元素成功返回true,否则返回false
因为Collection中定义的是共性的方法,所以不支持索引删除,只能通过元素的对象进行删除
| 重点 | |
|---|---|
| 删除包装类 | 数值的时候,会删除一样的 |
| 因为重写了equlas方法 |
contains 判断元素是否在集合中
// 创建实例化集合对象
Collection<String> c = new ArrayList<>();
// 判断aaa是否在当前集合中
boolean res = c.contains("aaa");
// 返回布尔值,打印一下
System.out.println(res);
细节:底层是依靠equals方法进行判断元素是否存在
所以如果集合中存储的是自定义的对象,那么在JavaBean中要重写equals对象
若没有重写equals方法,那么就按照父级equals判断,因为地址值一定不一样
isEmpty 判断集合是否为空
// 创建实例化集合对象
Collection<String> c1 = new ArrayList<>();
// 判断集合是否为空
boolean empty = c1.isEmpty();
// 打印empty
System.out.println(empty);
size 获取集合长度
// 创建实例化集合对象
Collection<String> c1 = new ArrayList<>();
// 获取集合长度
int size = c1.size();
// 打印
System.out.println(size);
Collection 遍历
因为没有索引无法使用普通for遍历
在遍历的时候,需要删除元素,使用迭代器
只是需要遍历,可以使用lambda和增强for
迭代器遍历(不依赖索引)
Collection 集合获取迭代器对象
// 创建集合
Collection< String > c1 = new ArrayList<>();
// 用当前集合添加迭代器对象
Iterator<String> iterator = c1.iterator();
方法:
hasNext ( ) 判断当前位置是否有元素,有元素返回true,没有元素返回false
next ( ) 获取当前位置的元素,并将送代器对象移向下一个位置
举个例子 迭代器遍历
// 创建集合
Collection<String> c1 = new ArrayList<>();
// 添加三个元素
c1.add("aaa");
c1.add("bbb");
c1.add("ccc");
// 用当前集合添加迭代器对象
Iterator<String> iterator = c1.iterator();
// 利用循环获得集合中的所有元素
while (iterator.hasNext()){ // hasNext判断当前元素是否为空
// 获取元素并移动指针
String s = iterator.next();
System.out.println(s);
}
细节:
1. 迭代器遍历结束后,再次移动指针会报错NoSuchElementException
2. 指针不会复位。无法回到最初的0索引,只能再次创建迭代器对象
3. 循环中的next方法只能有一个,两个可能发生获取不到元素报错
4. 迭代器遍历中,不能使用集合的方法进行增加或者删除,可以使用迭代器方法remove方式删除,添加还没有办法
增强for遍历
增强for的底层就是迭代器
所有的单列集合和数组才可以使用(双列集合不可以)
变量就是第三方变量,表示集合中的每一个数据体
for (数据类型 变量 : 要遍历的数组集合) {
语句体;
}
快速方式:集合名字 . for
Lambda表达式遍历
底层也是遍历集合,依次的到每个元素
把得到的元素交给accept方法 s表示每个数据
// 匿名方式
coll.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
// 简化方式
coll.forEach(s -> System.out.println(s));
单列集合 List
特点:
有序:存和取的顺序一致
有索引:可以通过索引操作元素
可重复:存储的元素可以重复
add 指定位置插入元素
// 创建list集合
List<String> list = new ArrayList<>();
// 在1索引位置插入元素,其他元素会往后移动包含1索引
list.add(1,"灰太狼");
细节:add是重载方法,写一个值,是 collection 的 add,两个值是 list 的,表示插入
插入之后,后面的元素依次往后移
remove 删除元素
// 创建整型集合
List<Integer> list = new ArrayList<>();
// 利用collection公共方法添加元素
list.add(1);
list.add(2);
list.add(3);
// 删除 在一索引上的元素
list.remove(1);
细节:remove是重载方法,一个传递对象,一个传递整型
删除成功会返回被删除的元素
set 修改元素
// 创建整型集合
List<Integer> list = new ArrayList<>();
// 把 0 索引的元素修改成 5
Integer set = list.set(0, 5);
// 打印返回值 返回被修改的元素
System.out.println(set);
细节:修改成功会返回被修改的元素
get 获取索引处的元素
// 创建整型集合
List<Integer> list = new ArrayList<>();
// 获取到当前索引的元素
Integer integer = list.get(0);
System.out.println(integer);
listIterator 列表迭代器
其他和普通迭代器一样
里面的指针也是默认指向 0 索引
额外添加了一个 add 方法可以插入元素
// 创建list列表迭代器
ListIterator<String> lt = list2.listIterator();
while (lt.hasNext()){
String next = lt.next();
if(next.equals("bbb")){
lt.add("qqq");
}
System.out.println(next);
}
LinkedList(集合)
内存会创建一个包含头节点和尾结点的空间
底层数据结构是双链表,查询慢,增删快,但是如果操作的是首尾元素,速度也是极快的。
| addFirst | 在列表 0 索引插入指定的元素 |
|---|---|
| addlast | 在列表最后追加元素 |
| getFirst | 返回此列表中的第一个元素 |
| getLast | 返回此列表中的最后一个元素 |
| removeFirst | 从此列表中删除并返回第一个元素 |
| removelast | 从此列表中删除并返回最后一个元素 |
总结
- 迭代器遍历:在遍历的时候可以删除元素
- 列表迭代器:在遍历的时候可以添加元素,list 集合才能使用
- 增强 for 和 lambda 表达式: 仅仅遍历可以使用
- 普通 for 遍历的时候可以操控索引
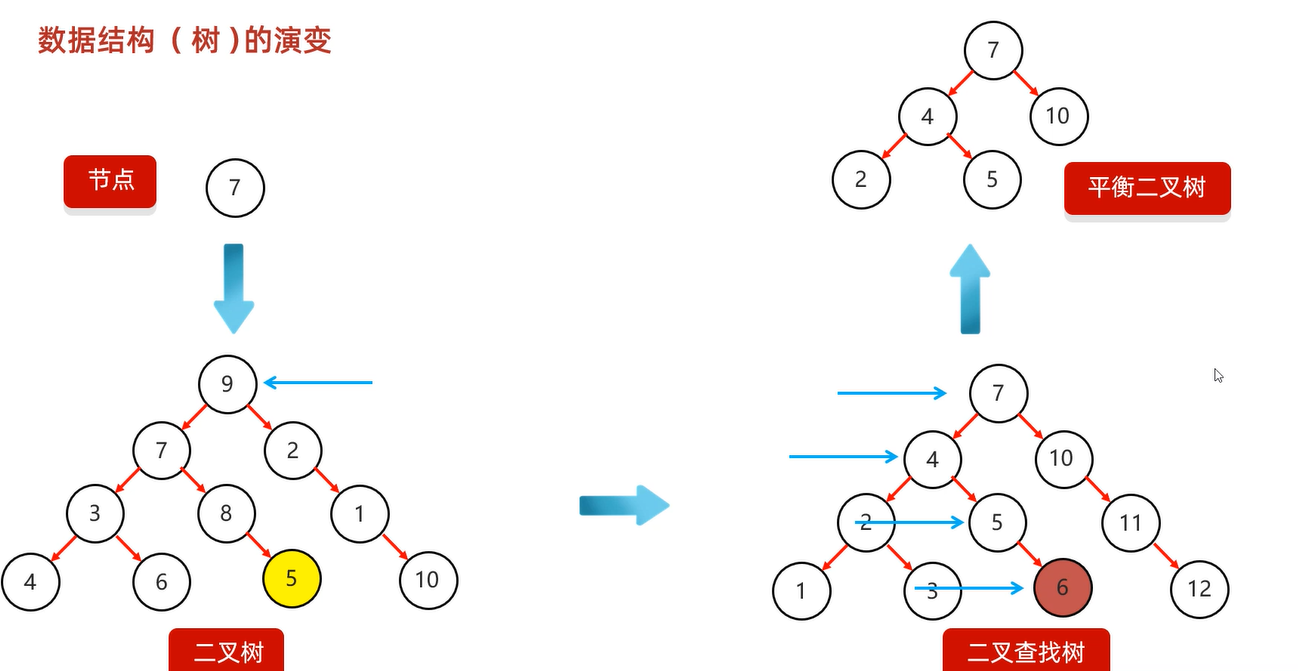
数据结构
① 栈 ② 队列 ③ 数组 ④ 链表 ⑤ 三又树 ⑥ 二叉查找树
⑦ 平衡二叉树 ⑧ 红黑树
- 每种数据结构长什么样子?
- 如何添加数据?
- 如何删除数据?
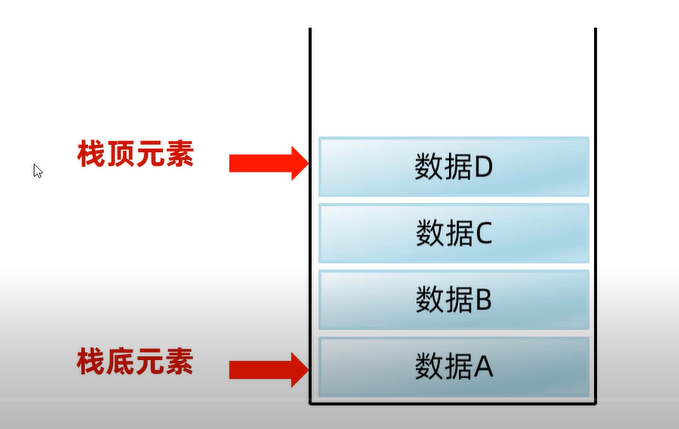
栈(后进先出,先进后出)
方法运行时使用的内存
特点:后进先出,先进后出
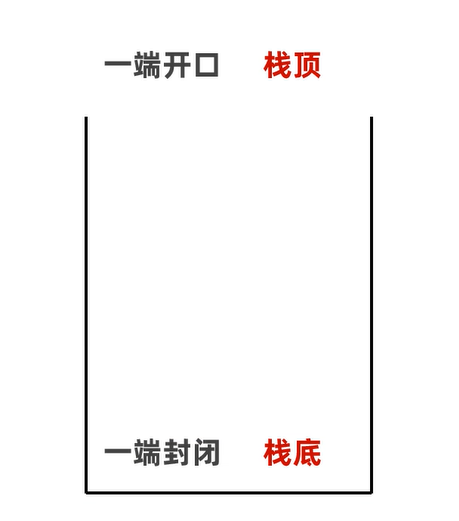
数据进入模型的过程叫做:压 / 进栈
数据离开模型的过程叫做:弹 / 出栈
在栈中,第一个元素叫栈底元素
在栈中,最后一个元素叫栈顶元素
方法都在栈里运行的
队列(先进先出,后进后出)
特点:先进先出,后进后出
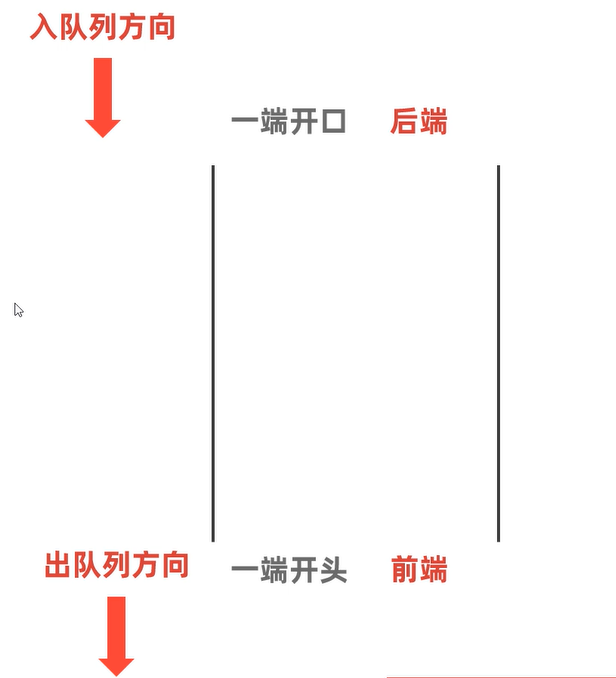
数据从后端进入队列模型的过程称为:入队列
数据从前端离开队列模型的过程称为:出队列
数组
数组是一种查询快,增删慢的模型
- 查询速度快:查询数据通过地址值和索引定位,查询任意数据,耗时间相同(元素在内存中是连续存储的)
- 删除效率低:要将原始的数据删除,同时后面的每个数据前移
- 添加效率极低:添加数据后的每个数据后移,再添加元素
堆内存
new 出来的对象都在堆里 ,存放数组,带地址的
方法区
字节码文件,存储可运行的class文件
元空间(新增)
把原来的方法进行区分,把方法区的功能进行区分,有的放在堆空间,有点放在元 空间
链表
链表中的结点是独立的对象,每个结点在内存中是不连续的,每个结点包含数据和下一个结点的地址
链表查询慢,无论查询哪个数据都要从头开始找
链表增删相对较快
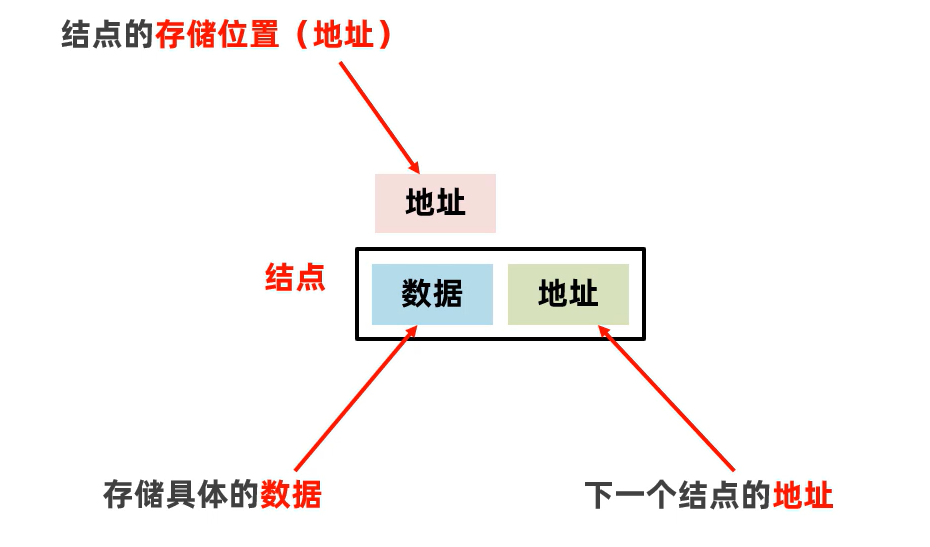
单项链表
双项链表:可以首尾判断
树
术语:
1. 度:每一个节点的子节点数量
2. 树高:树的总层数
3. 根节点:最顶层的节点
4. 左子节点:每个节点的左下方的节点
5. 右子节点:每个节点的右下方的节点
6. (每个)根节点的左子树:根节点的左边第一个下方所有
7.(每个) 根节点的右子树:根节点的右边第一个下方所有
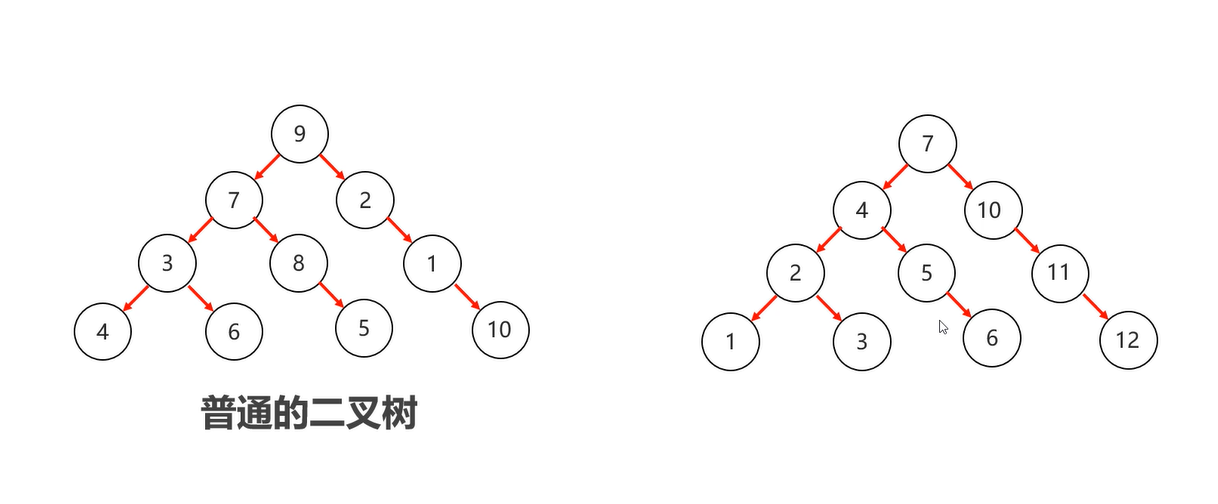
右边的二叉树是常用的
二叉树中,任意节点的度 <= 2
二叉树的弊端:
普通二叉树:对数据没有要求,没有规律,只能遍历
二叉查找树
特点:1. 每一个节点上最多有两个子节点
2. 任意节点左子树上的值都小于当前节点
3. 任意节点右子树上的值都大于当前节点
每个节点的内部结构:
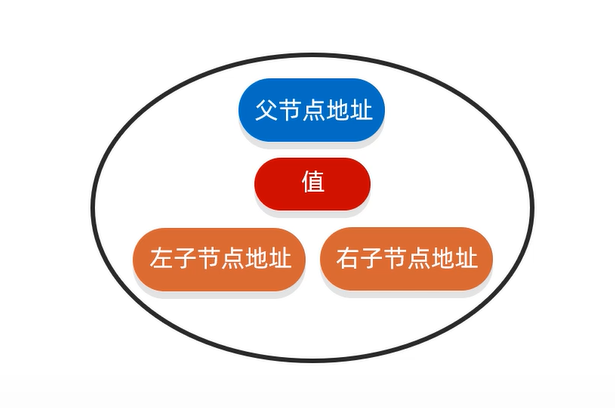
二叉查找树的弊端:
二叉查找树:如果存入的数据都比根节点大,那么左子树和右子树不对等,效率低
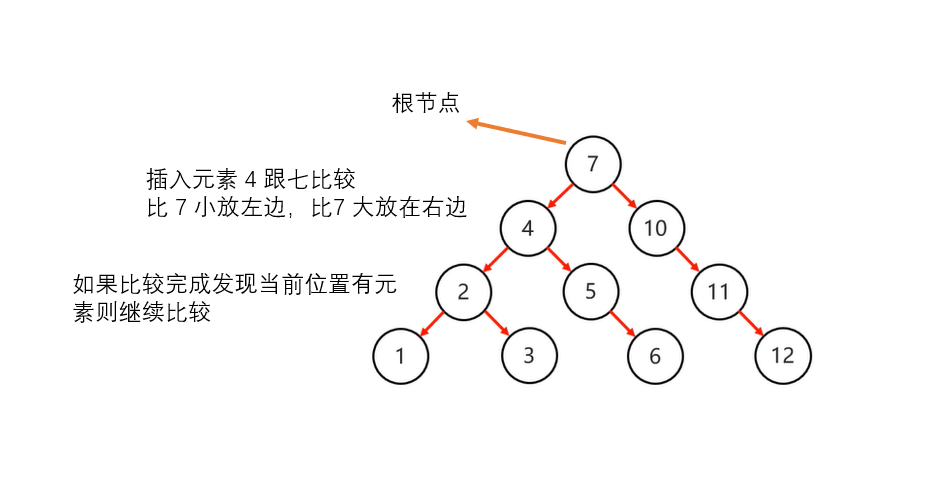
添加节点 查找元素
规则:
小的存右边,大的存左边,一样的不存
添加 、查找 同理
二叉树的遍历方式
- 前序遍历
从根节点开始,然后按照当前节点,左子节点,右子节点的顺序遍历

遍历结果
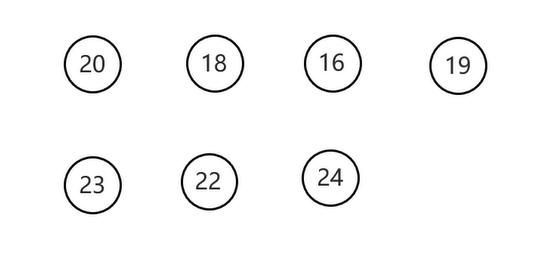
- 中序遍历
最为常见,最重要的方式,因为遍历的数据从小到大
从最左边的左子节点开始,然后按照左子节点,当前节点,右子节点的顺序遍历
遍历结果
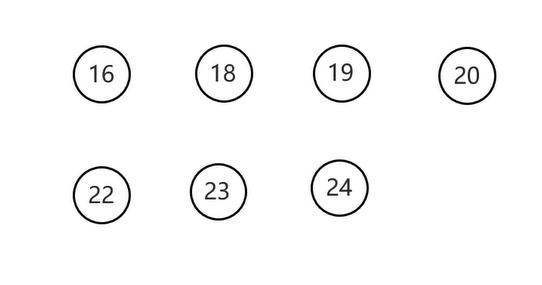
- 后序遍历
从最左边的左子节点开始,然后按照左子节点,右子节点,当前节点的顺序遍历
遍历结果
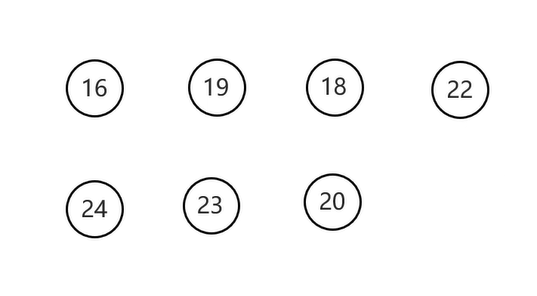
- 层序遍历
从根节点开始一层一层的遍历
遍历结果
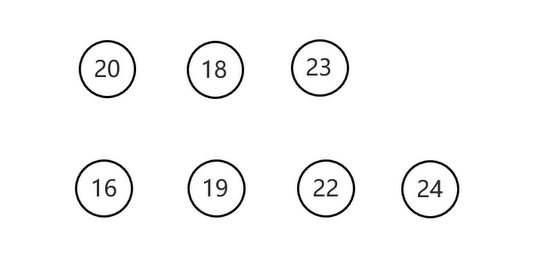
平衡查找树
规则:任意节点的左右子树高度差不超过一
旋转机制:左旋、右旋
触发时机:当添加一个节点之后。该树不再是一颗平衡二叉树
确定支点:从添加的节点开始,不断的往父节点找不平衡的节点(判断左旋还是右旋)
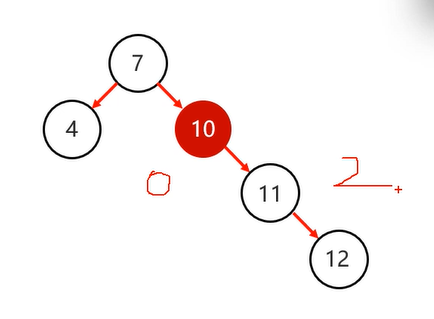
左旋:
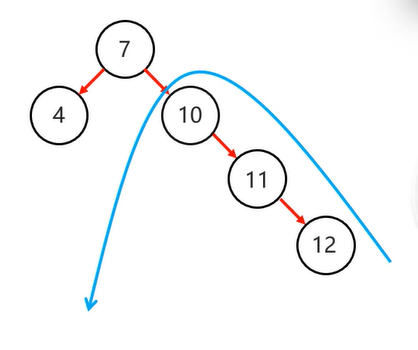
1 . 以不平衡的点作为支点
2 . 把支点左旋降级,变成左子节点
3 . 晋升原来的右子节点
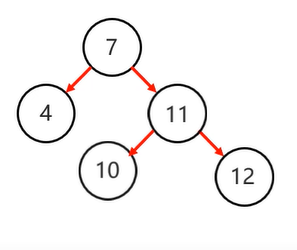
复杂情况:左子节点已经存在元素了,左 1 右 2 还是满足,继续往父节点看
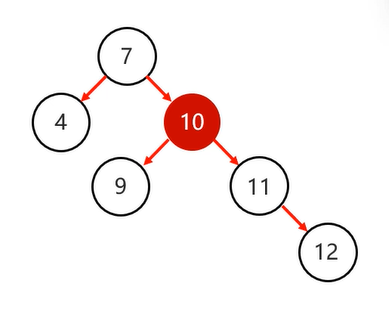
根节点,左1 右3
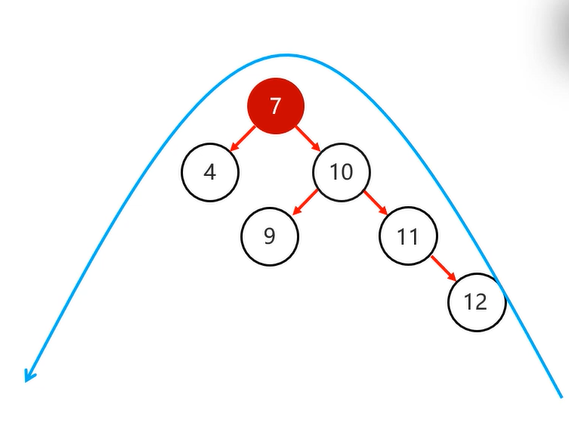
1 . 以不平衡的点作为支点
2 . 将根节点的右侧往左拉
3 . 原先的右子节点变成新的父节点,并把多余的节点左子节点出让,给已经降级的根节点当右子节点
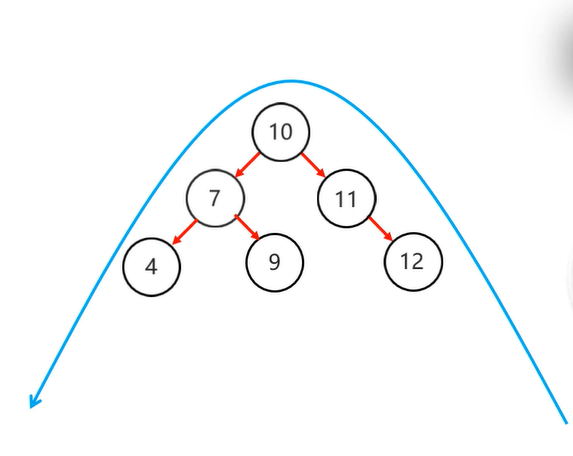
右旋同理: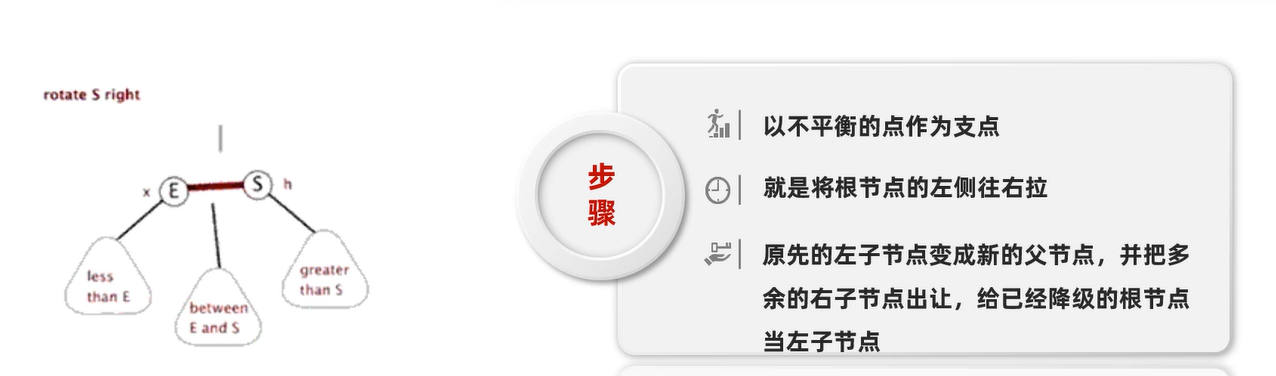
易错点:这是不平衡的,因为左3 右 1
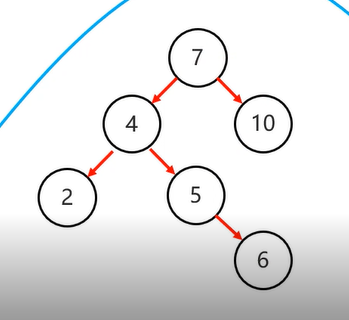
需要旋转的四种情况:
1 . 左左:当根节点左子树的左子树有节点插入,导致二叉树不平衡
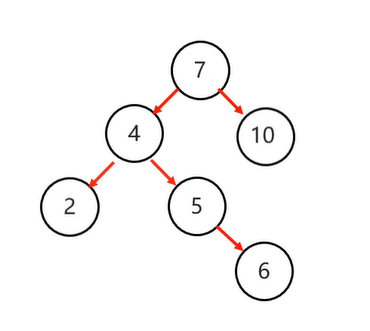
2 . 左右:当根节点左子树的右子树有节点插入,导致二叉树不平衡(左右的话仅仅一次右旋是不够的)
需要先局部旋转
初始:
先局部左旋
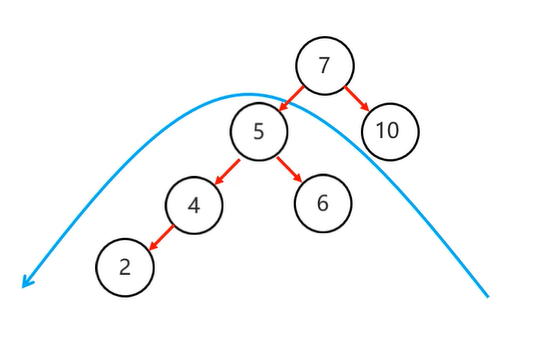
再整体右旋 这样就可以了 ok
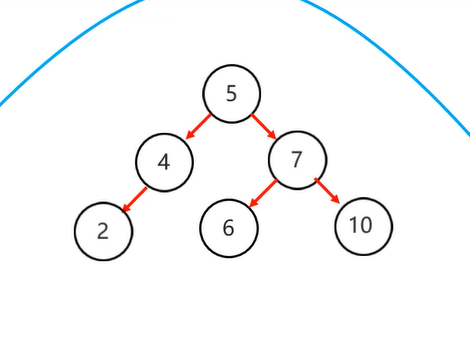
3 . 右右:当根节点右子树的右子树有节点插入,导致二叉树不平衡
4 . 右左:当根节点右子树的左子树有节点插入,导致二叉树不平衡

平衡二叉树总结
- 在平衡二叉树中,如何添加节点?
先比较:小的存左边,大的存右边,一样的不存 - 在平衡二叉树中,如何查找单个节点?
先比较:小的往左查,大的往右边查,相等结束 - 为什么要旋转?
普通的二叉树和二叉查找树不需要旋转,添加节点之后,树不平衡了,所以要旋转 - 旋转的触发时机?
当平衡二叉树添加节点成功导致树不平衡了 - 左左是什么意思?如何旋转?
左左就是,当我们把新节点添加到,根节点的左子树的左子树上破坏了平衡
旋转方式:进行一次右旋 - 左右是什么意思?如何旋转?
左右就是,当我们把新节点添加到,根节点的左子树的右子树上破坏了平衡
旋转方式:先进行局部左旋,再进行全部右旋 - 右右是什么意思? 如何旋转?
右右:就是再根节点右子树的右子树添加节点,破坏平衡
旋转方式:进行一次左旋 - 右左是什么意思?如何旋转?
右左:添加在右子树的左子树上
旋转方式:先局部右旋,然后再整体左旋
红黑树
介绍:1972年出现,它是一种特殊的二叉查找树,红黑树每一个节点都存储一个颜色
- 每一个节点可以是红色或者是黑色
- 红黑树不是高度平衡的,它的平衡是通过红黑规则实现的
红黑硬性规则:
1. 每一个节点必须是红色的,或者是黑色的
2. 根节点必须是黑色
3. 如果一个节点没有子节点或者父节点,则该节点相应的指针属性值为Nil,这些NiI视为叶节点,每个叶节点(NiL)是黑色的
4. 如果某一个节点是红色,那么它的子节点必须是黑色(不能出现两个红色节点相连的情况)
5. 对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点(就是节点左边黑色是两个,右边必须也是两个)
节点内部视图:
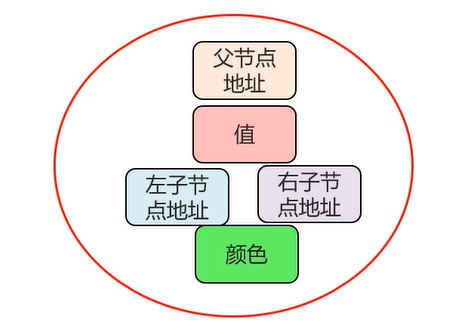
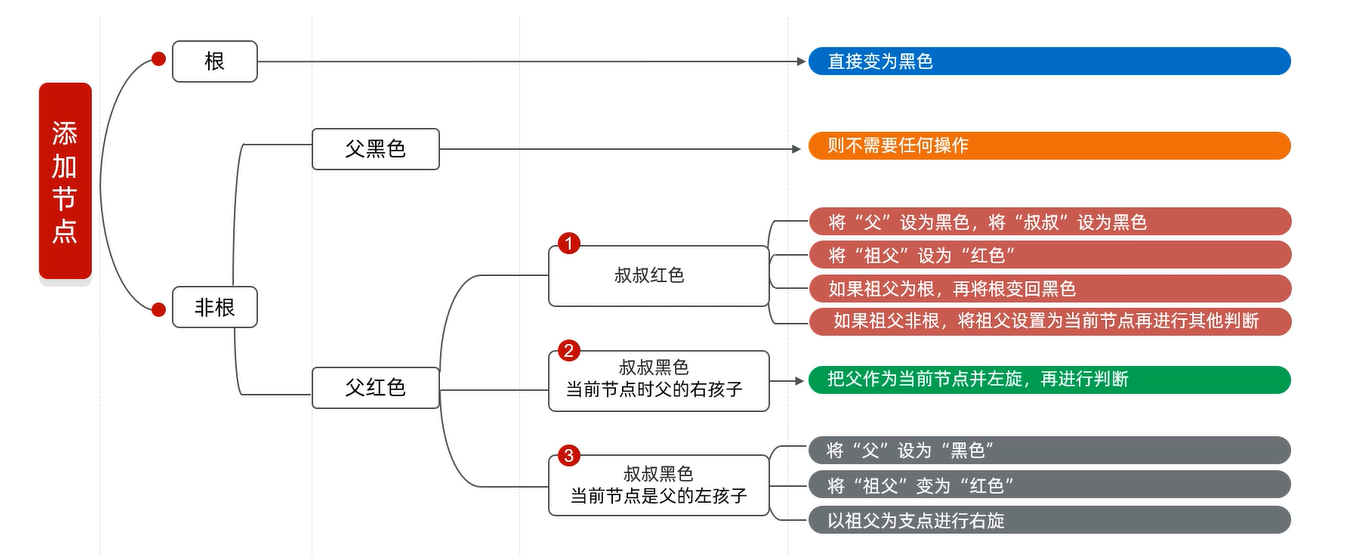
添加节点
添加节点时,添加的节点默认是红色的
红黑规则(重点)
Set 集合
复习一下:特性:无序,不重复,无索引
重点:Set 接口中的方法基本上与Collection 的API一致
- HashSet:无序、不重复、无索引
- LinkedHashSet:有序、不重复、无索引
- TreeSet:可排序、不重复、无索引
set 集合基本用法:
添加元素:
// 创建一个set集合,因为是接口,实现多态
Set<String> s = new HashSet<>();
boolean zhang = s.add("张三");
boolean z = s.add("张三");
// 返回false 是因为 set集合不重复性
System.out.println(z); // true
System.out.println(zhang); // false
哈希值
在Object类中,一般情况会重写hashCode方法,利用对象内部属性计算哈希值
哈希值:对象的正数表现形式
细节:
如果没有重写hashCode方法,不同的对象计算出
如果已经重写了hashCode方法,不同的对象只要属性值相同,计算出的哈希值就是一样的
但是小部分情况下,不同的属性值或者不同的地址值计算出的哈希值也是一样的(哈希碰撞)
// 创建两个用户
User use1 = new User();
User use2 = new User();
// 打印哈希值
System.out.println(use1.hashCode());//1096979270
System.out.println(use2.hashCode());//1078694789
HashSet 集合
特性:无序,不重复,无索引
| HashSet集合的底层数据结构是什么样子的? |
|---|
| 答:HashSet底层采取哈希表存储数据 |
| 哈希表:数组 + 链表 + 红黑树 |
| HashSet添加元素的过程? |
| 1. 根据元素的哈希值和数组长度判断应存入的位置 |
| 2. 如果当前位置为null直接存入 |
| 3. 如果当前位置有元素,就用equals和它比较 |
| 4. 一样则舍弃,否则存入形成链表,直接放在当前元素后面 |
| HashSet为什么存和取的顺序不一样? |
| HashSet会从头开始一个个遍历,如果为空跳过,但是存入的时候是根据哈希值存入的,所以顺序不一样 |
| HashSet为什么没有索引? |
| HashSet底层由数组,链表,红黑树组成的,无法决定顺序 |
| HashSet是利用什么机制保证数据去重的呢? |
| hashCode 获取哈希值,判断链表所在位置 |
| 利用equals去依次比较,保证数据唯一 |
LinkedHashSet
有序、不重复、无索引
有序:是指存和取的顺序一样
底层:数据结构依旧是哈希表,只是每个元素又额外的多了一个双链表的机制记录存储的顺序
重点:以后数据去重我们用HashSet,但是要有序就用LinkedHashSet
TreeSet (可排序)
TreeSet 默认排序是从小到大
按照字符串和字符,是根据ASCILL码中数字升序排序
细节:
- 如果存入的是自定义对象,需要重写排序规则
- hashCode 和 equals 底层和哈希表有关系
- tree不需要哈希值,不需要重写,底层是红黑树
重写规则:
自然排序:JavaBean里实现Comparable接口指定比较规则
- 需要接入接口 implements Comparable
- 排序规则
@Override
public int compareTo(Student o) {
return this.getAge() - o.getAge();
}
this 表示要添加的数字
o.getAge表示红黑树已经存在的数字
返回值是
负数:表示存在红黑树左边
整数:表示存在红黑树右边
0: 表示不存
比较器排序:创建TreeSet对象时候,传递比较器Comparator指定规则
| 总结 | |
|---|---|
| TreeSet集合的特点是什么? | 可排序,不重复,无索引 |
| 底层基于红黑树实现排序,增删改查性能较好 | |
| TreeSet集合自定义排序规则有几种方式? | |
| 方式一: | JavaBean类实现Comparable接口 |
| 方式二: | 创建集合时,自定义Comparator比较器对象 |
| 方法返回值的特点: | |
| 负数: | 表示当前要添加的元素是小的,存左边 |
| 正数: | 表示当前要添加的元素是大的,存右边 |
| 0: | 表示当前要添加的元素是已经存在的 |
单列集合总结
- 如果想要集合中的元素可重复
用ArrayList集合,基于数组的。(用的最多) - 如果想要集合中的元素可重复,而且当前的增删操作明显多于查询
用LinkedList集合,基于链表的。 - 如果想要对集合中的元素去重
用HashSet集合,基于哈希表的。(用的最多) - 如果想要对集合中的元素去重,而且保证存取顺序
用LinkedHashSet集合,基于哈希表和双链表,效率低于HashSet。 - 如果想对集合中的元素进行排序
用TreeSet集合,基于红黑树。后续也可以用List集合实现排序
双列集合
| 双列集合的特点: | 双列集合一次需要存一对数据,分别是键和值 |
|---|---|
| 键不能重复,值可以重复 | |
| 键和值是一一对应的,每个键只能找到自己对应的值 | |
| 键+值这个整体,叫键值对 / 键值对对象。Java里叫Entry对象 |
Map 常见API
添加元素(put)
// 创建map多态实例化集合
Map<String,String> m = new HashMap<>();
// 添加键值对
m.put("郭靖","黄蓉");
m.put("韦小宝","沐剑屏");
m.put("尹志平","小龙女");
细节:
1、如果添加的键不存在:会直接把键值对存入map集合中,返回null
2、如果键是存在的,那么会把原有的键值对覆盖,被覆盖的值进行返回
移除元素(remove)
// 创建map多态实例化集合
Map<String,String> m = new HashMap<>();
// 移除郭靖元素
String result = m.remove("郭靖");
// 打印返回值,返回一个被移除的值
System.out.println(result);
重点:移除键,返回值是,键的值
清空所有元素(clear)
// 创建map多态实例化集合
Map<String,String> m = new HashMap<>();
m.clear();
重点:清空所有元素,没有返回值
判断集合中是否包括该键(containsKey)
// 创建map多态实例化集合
Map<String,String> m = new HashMap<>();
// 如果集合中包括键:郭靖1,就返回true,否则false
boolean res = m.containsKey("郭靖1");
System.out.println(res);
重点:如果集合中包括这个键,就返回true,否则false
判断集合中是否包括该值(containsValue)
// 创建map多态实例化集合
Map<String,String> m = new HashMap<>();
// 如果集合中包括值:小龙女1,就返回true,否则false
boolean res = m.containsValue("小龙女1");
System.out.println(res);
重点:如果集合中包括这个值,就返回true,否则false
判断集合是否为空(isEmpty)
// 创建map多态实例化集合
Map<String,String> m = new HashMap<>();
// 如果集是空的就返回true,否则false
boolean empty = m.isEmpty();
System.out.println(enpty);
重点:如果集是空的就返回true,否则false
返回集合长度(size)
// 创建map多态实例化集合
Map<String,String> m = new HashMap<>();
// 获取集合长度
int size = m.size();
System.out.println(size);
重点:返回集合长度
遍历map集合方式
通过键找值
| 获取所有的键,放到set集合中 | keySet |
|---|---|
| 遍历单列集合,根据键找值 | get |
| keyset | map集合方法 |
| get | map集合方法 |
增强for
// 创建map多态实例化集合
Map<String,String> m = new HashMap<>();
m.put("郭靖","黄蓉");
m.put("韦小宝","沐剑屏");
m.put("尹志平","小龙女");
// 把map集合的键全部给set集合
Set<String> s = m.keySet();
// 遍历set
for (String key : s) {
String s5 = m.get(key);
System.out.println(key + " " + s5);
}
迭代器
// 创建map多态实例化集合
Map<String,String> m = new HashMap<>();
m.put("郭靖","黄蓉");
m.put("韦小宝","沐剑屏");
m.put("尹志平","小龙女");
// 把map集合的键全部给set集合
Set<String> s = m.keySet();
// 遍历set
Iterator<String> it = s.iterator();
while (it.hasNext()){
String next = it.next();
String s5 = m.get(next);
System.out.println(next + " " + s5);
}
Lambda表达式
// 创建map多态实例化集合
Map<String,String> m = new HashMap<>();
m.put("郭靖","黄蓉");
m.put("韦小宝","沐剑屏");
m.put("尹志平","小龙女");
// 把map集合的键全部给set集合
Set<String> s = m.keySet();
// 遍历set
s.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
String s5 = m.get(s);
System.out.println(s + " " + s5);
}
});
通过键值对方式遍历
| 获取所有的键值对对象 | entrySet |
|---|---|
| 获取键 | getKey |
| 获取值 | getValue |
增强for
// 创建map多态实例化集合
Map<String,String> m = new HashMap<>();
m.put("郭靖","黄蓉");
m.put("韦小宝","沐剑屏");
m.put("尹志平","小龙女");
// 这个entry 是一个内部接口,需要调取Map这个类 嵌套调用
Set<Map.Entry<String, String>> entries = m.entrySet();
// 遍历set集合
for (Map.Entry<String, String> entry : entries) {
// 利用get方式获取键和值
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + " " + value);
}
迭代器
// 创建map多态实例化集合
Map<String,String> m = new HashMap<>();
m.put("郭靖","黄蓉");
m.put("韦小宝","沐剑屏");
m.put("尹志平","小龙女");
// 这个entry 是一个内部接口,需要调取Map这个类 嵌套调用
Set<Map.Entry<String, String>> entries = m.entrySet();
// 遍历set集合
<font color=Green>增强for</font>
```java
// 创建map多态实例化集合
Map<String,String> m = new HashMap<>();
m.put("郭靖","黄蓉");
m.put("韦小宝","沐剑屏");
m.put("尹志平","小龙女");
// 这个entry 是一个内部接口,需要调取Map这个类 嵌套调用
Set<Map.Entry<String, String>> entries = m.entrySet();
// 迭代器
Iterator<Map.Entry<String, String>> it = entries.iterator();
while (it.hasNext()){
Map.Entry<String, String> next = it.next();
String key = next.getKey();
String value = next.getValue();
System.out.println(key + " " + value);
}
Lambda 表达式
// 创建map多态实例化集合
Map<String,String> m = new HashMap<>();
m.put("郭靖","黄蓉");
m.put("韦小宝","沐剑屏");
m.put("尹志平","小龙女");
// 这个entry 是一个内部接口,需要调取Map这个类 嵌套调用
Set<Map.Entry<String, String>> entries = m.entrySet();
// 遍历set集合
// 创建map多态实例化集合
Map<String,String> m = new HashMap<>();
m.put("郭靖","黄蓉");
m.put("韦小宝","沐剑屏");
m.put("尹志平","小龙女");
// 这个entry 是一个内部接口,需要调取Map这个类 嵌套调用
Set<Map.Entry<String, String>> entries = m.entrySet();
// lambda 表达式
entries.forEach(new Consumer<Map.Entry<String, String>>() {
@Override
public void accept(Map.Entry<String, String> stringStringEntry) {
String key = stringStringEntry.getKey();
String value = stringStringEntry.getValue();
System.out.println(key + " " + value);
}
});
通过Lambda直接遍历
// 创建map多态实例化集合
Map<String,String> m = new HashMap<>();
m.put("郭靖","黄蓉");
m.put("韦小宝","沐剑屏");
m.put("尹志平","小龙女");
m.forEach(new BiConsumer<String, String>() {
@Override
public void accept(String key, String value) {
System.out.println(key + " " + value);
}
});
HashMap
| HashMap的特点 | |
|---|---|
| 是map里面的一个实现类 | |
| 直接使用Map里面的方法就可以了 | |
| 特点是由键决定的: | 无序,不重复,无索引 |
| 链表数组红黑树 | HashMap跟HashSet底层一样,都是哈希表结构 |
底层原理:
比较的时候,只比较键的属性值
一样,则覆盖,不一样就挂在老元素下边形成链表
如果链表长度大于8,数组长度大于64,直接转成红黑树
如果键存的是自定义对象,需要重写hashCode和equals方法
如果值存的是自定义对象,则不需要
LinkedHashMap
由键决定:有序、不重复、无索引。
有序:是指保存存储和取出的顺序一致
原理:底层数据结构依然是哈希表,只是每个键值对元素有额外多了一个双链表的机制记录存储顺序。
TreeMap
TreeMap 跟 TreeSet底层原理一样,都是红黑树结构的
由键决定特性:不重复、无索引、可排序
可排序:对键进行排序
注意:默认按照键的从小到大排序,也可以自定义排序规则
排序的两种规则:
- 实现Comparable接口,指定比较规则。
- 创建集合时传递Comparator比较器对象,指定比较规则(优先)。
总结
- ArrayList 底层数组
- LinkedList 底层双向链表
- HashMap 底层哈希表
| 不需要排序,效率高 | HashMap |
|---|---|
| 要排序 | TreeMap |
| 增删多 | LinekedList |
| 查找修改多 | ArrayList |
泛型<类型>
此时的 < String > 泛型
ArrayList<String> list = new ArrayList<>();
如果没有泛型,集合里存入的都是Object对象,可以存取任意类型
坏处:无法使用它的特有方法
泛型的好处:添加数据的时候直接统一类型,省的强转了
把运行时期的问题提前到了编译期间,避免了强转出现的异常问题。
泛型的细节:
1. 泛型中不能写基本数据类型
2. 指定泛型具体类型后,可以传递该类型或者其子类类型
3. 如果不写泛型,类型默认是Object
泛型类
使用场景:当一个类中,某个变量的数据类型不确定时,就可以定义带有泛型的类
修饰符 class 类名<类型>{
}
// E 就是确定类型
public class ArrayList<E>{
}
此处的E可以理解为变量,但不是用来记录数据的,而是用来记录数据类型的,可以写成 T E K V
案例
public class A16Hth1<E> {
Object[] obj = new Object[10];
int size;
// 此处的 E 表示不确定的数据类型,后面的 e 表示形参名字
public boolean add(E e){
obj[size] = e;
size++;
return true;
}
泛型方法
当方法中的形参类型不确定的时候,可以在方法权限修饰符后面加泛型
方案1️⃣:使用类名后面的泛型 注意:本类中都可以使用
方案2️⃣:在方法声明上定义自己的泛型 注意:只有本方法可以使用
修饰符<类型> 返回值类型 方法名(){
}
案例
public static<E> void addAll(ArrayList<E> list) {
}
泛型接口
泛型接口的两种使用方式
- 实现类给出具体的类型
// 创建接口的时候 已经给出 List<Integer>
public class ListImplements implements List<Integer> {
}
- 实现类延续泛型,创建实现类对象时再确定类型
接口类
// 泛型要写在类名后面
public class ListImplements<E> implements List<E> {
}
测试类
// 下方泛型要写上
ListImplements<String> list = new ListImplements<>();
泛型的通配符(对类型进行限定)
泛型不具备继承性,但是数据可以
泛型的弊端:泛型可以传递任意数据
我们希望只传递 Ye Fu Zi 继承的对象
通配符: ? 也表示不确定类型 它可以对类型进行限定
? extends E:表示传递E或者E的所有子类类型
? super E:表示传递E或者E的所有父类类型
通配符是参数,写在<>里
案例
private static void method(ArrayList<? extends Ye> list) {
}
可变参数
有时候我们的需求,方法里的参数不是固定的,是可变的
| 格式: | 类型…名字 |
|---|---|
| 这个时候传递方法的实参,就可以设置多个 | |
| 在方法里,这个就是一个数组 | |
| 细节: | 只能有一个参数是可变参数 |
| 如果有其他参数,可变参数要写在最后 |
案例
public static void main(String[] args) {
int i = getsum(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
System.out.println(i);
}
private static int getsum(int...args) {
int sum = 0;
for (int arg : args) {
sum += arg;
}
return sum;
}
文件 常用 API 和 简介
目前是怎样存储数据的?弊端是什么?
在内存中存储的数据是用来处理、修改、运算的,不能长久保存
在计算机中,有没有一块硬件可以永久性存储数据?
就是文件,存储到文件中,类似于硬盘
file类不能读取文件信息
file(构造方法)
// 参数1:表示父级路径 是路径
// 参数2:表示子级路径 是文件
File file = new File("src/com","Student.java");
System.out.println(file); //src\com\Student.java
文件大小(length)
File f = new File("src/test/java/merge.txt");
System.out.println(f.length());
返回文件的字节数(文件大小)
重点:如果 file 获得的是文件夹,返回 0
反斜杠API(File.separator)
File f = new File("src" + File.separator + "test" + File.separator + "java" + File.separator + "merge.txt");
System.out.println(f.length());
优点:可以跨平台,window 和 linux 反斜杠不一样
相对路径
java里相对路径是相对于当前的工程的。
判断路径存不存在(exists)
File f = new File("src/test/java/merge.txt");
System.out.println(f.exists());
存在则返回 true 否则返回 false
小总结
| file类的作用 | 创建对象定位文件,可以删除文件 |
|---|---|
| 获取文件信息,不能读取文件 | |
| 相对路径 | 不带盘符,默认相对到工程下寻找文件 |
| 绝对路径 | 依赖当前系统,是带盘符的 |
获取绝对路径(getAbsolutePath)
File f = new File("src/test/java/merge/");
System.out.println(f.getAbsolutePath());
// D:\idea01\untitled1\untitled3\src\test\java\merge
返回绝对路径
获取当前使用的路径(getPath)
File f = new File("src/test/java/merge/");
System.out.println(f.getPath());
// src\test\java\merge
返回使用的路径
获取文件名字带后缀(getName)
File f = new File("src/test/java/merge/");
System.out.println(f.getName());
// merge
返回文件名称
获取文件最后修改时间(lastModified)
File f = new File("src/test/java/merge.txt");
long time = f.lastModified();
// 格式化时间并打印
System.out.println("最后修改时间 " + new SimpleDateFormat("yyyy/MM/dd HH:mm:ss").format(time));
// 最后修改时间 2022/10/07 16:49:08
返回毫秒数,如果格式化了,按格式化走
判断当前是文件吗(isFile)
File f = new File("src/test/java/merge.txt");
System.out.println(f.isFile());
// true
是文件返回 true 否则 false
判断当前是文件夹吗(isDirectory)
File f = new File("src/test/java/merge.txt");
System.out.println(f.isDirectory());
// false
是文件夹返回 true 否则 false
创建文件(createNewFile)
File f = new File("src/test/java/merge.txt");
System.out.println(f.createNewFile());
// false
File f1 = new File("src/test/java/me.txt");
System.out.println(f1.createNewFile());
// true
创建成返回 true 否则 false
如果当前文件存在,则不创建,只有不存在时创建
几乎不用,因为后期都是自动创建的
创建目录(一级)(mkdir)
D: /这个路径是必须存在的,创建 aaa
File file = new File("D:/aaa");
System.out.println(file.mkdir());
// true
创建成返回 true 否则 false
不支持多级目录创建
创建目录(多级)(mkdirs)
aaa 存在,bbb ccc ddd eeee 不存在,一次性创建
File file = new File("D:/aaa/bbb/ccc/ddd/eee");
System.out.println(file.mkdirs());
// true
创建成返回 true 否则 false
删除文件夹(delete)
占用也一样可以删除,不放在回收站,不能删除非空文件夹
File file = new File("D:/aaa/bbb/ccc/ddd/eee");
System.out.println(file.delete());
// true
删除成返回 true 否则 false
遍历文件夹,返回字符数组(list)
只打印当前目录下所有的文件
File file = new File("D:/360downloads");
String[] list = file.list();
for (String name : list) {
System.out.println(name);
}
// 2052119.jpg 2052120.jpg 2053786.jpg 2054002.jpg 2054085.jpg
返回一个字符数组,内容是文件名称
遍历文件夹,返回文件对象(listFiles)
获取当前目录下所有的文件的对象,只能一级
File file = new File("D:/360downloads");
File[] files = file.listFiles();
for (File f : files) {
System.out.println(f.getAbsoluteFile());
}
// D:\360downloads\2052119.jpg D:\360downloads\2052120.jpg
返回一个对象数组,操控对象使用
当路径错误,获取处理的数组是 null
或者是文件,返回null
当获取一个空的文件夹时,返回长度为 0
如果有隐藏内容,也会获取到(重点)
方法递归,算法流程
递归的形式和特点
方法自己调用自己
| 递归算法三大要素 | |
|---|---|
| 递归的公式 | f(n) = f(n-1) * n |
| 递归的终结点 | (f1) |
| 递归的方向必须走向终点 |
文件搜索
| 文件目录搜索的步骤 |
|---|
| 1. 先定位出的应该是一级文件对象 |
| 2. 遍历出一级文件对象,判断是否是文件 |
| 3. 如果是文件,判断是否是自己想要的 |
| 4. 如果是文件夹,需要继续递归进去重复上述操作 |
public static void main(String[] args) throws IOException, ClassNotFoundException {
// 2. 调用对象
fileCheck(new File("D:/"), "周杰伦 - 晴天.mp3");
}
// 1. 先创建方法
public static void fileCheck(File dir, String name) {
// 3. 判断dir是否是目录
if(dir != null && dir.isDirectory()){
// 4. 提取当前目录下的一级文件对象
File[] files = dir.listFiles();
// 刚进来的时候,这个目录不可以是 空的,或者为null
if(files != null && files.length > 0){
for (File file : files) {
// 5. 判断当前是否存在一级文件对象,存在才可以遍历
if(file.isFile()){
// 6. 如果是文件就比较一下
if(file.getName().contains(name)){
System.out.println("找到了" + file.getAbsoluteFile());
}
}else {
fileCheck(file,name);
}
}
}
}else {
System.out.println("当前搜索位置不是目录,无法查找");
}
}
非规律化递归–啤酒问题
啤酒两元一瓶,四个盖子可以换一瓶,两个空瓶可以换一瓶
论十元可以买几瓶,剩余几个瓶子和几个盖子
// 主方法,静态区域
public static int totalNumber; // 总和
public static int lastCoverNumber; // 每次剩余盖子
public static int lastBottomNumber; // 每次剩余瓶子
fileCheck(10);
// 先获得购买的啤酒数量
int buyNumber = money / 2;
totalNumber = totalNumber + buyNumber;
// 计算盖子和瓶子数量
int coverNumber = lastCoverNumber + buyNumber; // 要加上上一次的盖子数量
int bottomNumber = lastBottomNumber + buyNumber; // 要加上上一次的瓶子数量
// 换算成钱
int allMoney = 0;
// 四个瓶子等于两块
allMoney += coverNumber >= 4 ? (coverNumber / 4) * 2 : allMoney;
lastCoverNumber = coverNumber % 4;
// 两个瓶子两块
allMoney += bottomNumber >= 2 ? (bottomNumber / 2) * 2 : allMoney;
lastBottomNumber = bottomNumber % 2;
// 余额大于2 调用
if(allMoney >= 2){
fileCheck(allMoney);
}
字符集
| ASCLL字符集 | ASCLL使用 1个字节存储,一个字节是 8 位 |
|---|---|
| 总共128位,对于英文数字来说够用 | |
| 01100001 = 97 => a | |
| GBK字符集 | window系统默认的码表。兼容ASCll码表 |
| 包含几万个汉字,包括繁体字,部分日韩文字 | |
| GBK是中国的码表,一个中文以两个字节的形式存储 | |
| Unicode码表 | Unicode是万国码,以UTF-8编码后一个中文一般以三个字节存储 |
| UTF-8也要兼容ASCll编码表 | |
| 技术人员都应该使用UTF-8字符集编码 | |
| 编码前和编码后字符集需要一致,否则中文乱码 |
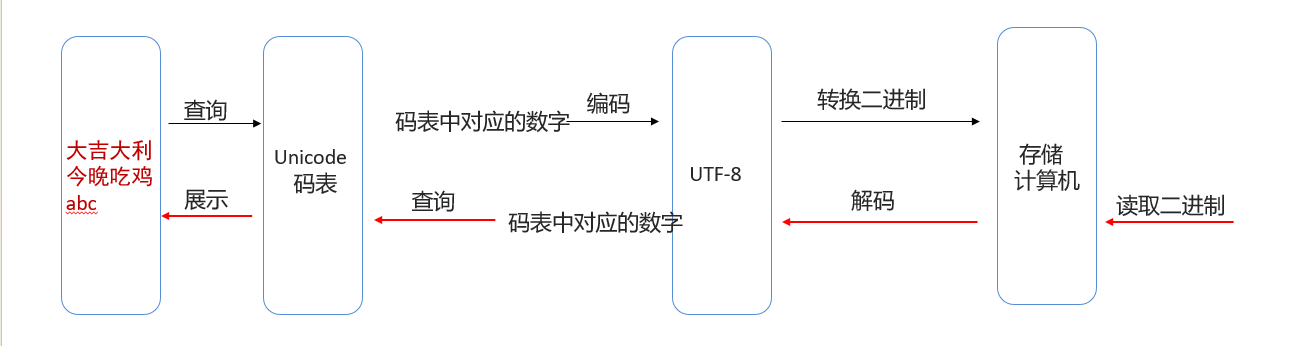
小结
| 字符串常见的字符底层组成是什么样子的? |
|---|
| 1. 英文和数字等在任何国家的字符集中都占1个字节 |
| 2. GBK字符中一个中文字符占2个字节 |
| 3. UTF-8编码中一个中文一般占3个字节 |
| 编码前的字符集和编码后的字符集有什么要求 |
| 1. 必须一致,否则会出现中文乱码 |
| 2. 英文和数字在任何国家的编码中都不会出现乱码 |
编码实现(getBytes)
编码,字符串转为字节。
默认使用UTF-8,可以指定
String s = "abc爱你爱你";
byte[] bytes = s.getBytes();
System.out.println(Arrays.toString(bytes));
// [97, 98, 99, -25, -120, -79, -28, -67, -96, -25, -120, -79, -28, -67, -96]
指定字符编码,GBK
String s = "abc爱你爱你";
byte[] bytes = s.getBytes("gbk");
System.out.println(Arrays.toString(bytes));
// [97, 98, 99, -80, -82, -60, -29, -80, -82, -60, -29]
解码实现(new String)
new String 里传递一个字节数组
String s1 = new String(bytes);
System.out.println(s1);
// abc���㰮��
bytes字节由GBK方式编码的,而解码默认UTF-8,所以这边打印的是中文乱码
指定解码的字符编码
String s1 = new String(bytes,"GBK");
System.out.println(s1);
// abc爱你爱你
IO流
| IO流 | |
|---|---|
| input,输入 | |
| output,输出 | |
| 字节流:压缩包,视频,图片等 | 以字节的形式输入 / 输出 |
| 字符流:主要用来操作纯文本 | 以字符的形式输入 / 输出 |
| 字符流只要,写入文本,读入文本 |
小结
| IO流的作用 | 读写文件数据的 |
|---|---|
| IO流是怎么划分的,分为几类,各自的作用 | |
| 字节流 | 字节输入输出流,读写字节数据的 |
| 字符流 | 字符输入输出流,读写字符数据的 |
| 每次都要关闭资源 | close关闭之后无法继续使用 |
输入流,字节流(FileInputStream)
传递一个文件的地址,不可以是文件夹
读入(read)
方法read:每次读入一个字节 / 字符,返回读取到的字节,如果读取不到返回 -1
// 创建对象
FileInputStream f = new FileInputStream(file1);
int r = 0;
while ((r = f.read()) != -1){
System.out.println((char)r);
}
这种方式,效率太慢,建议用数组,常用1024方式读入
先定义数组,每次读取字节数组长度
FileInputStream f = new FileInputStream("src/test/java/merge.txt");
byte[] bytes = new byte[1024];
int r;
while ((r = f.read(bytes)) != -1){
// 读取这个数组,从 0 到 r
System.out.println(new String(bytes, 0, r));
}
每次读取一个字节数组存在什么问题?
- 读取的性能得到了提升
- 读取中文字符输出无法避免乱码问题。
读取全部字节(readAllBytes)
FileInputStream f = new FileInputStream("src/test/java/merge.txt");
// 获取所有
int[] r = f.readAllBytes();
// 打印
System.out.println(r));
}
输出流,字节流(FileOutputStream)
如果文件不存在,会自动创建,路径不正确会报错
FileInputStream f = new FileInputStream("src/test/java/merge.txt");
写入(write)
只可以一个一个字节写入
FileOutputStream f1 = new FileOutputStream("src/test/java/merge1.txt");
f1.write('f');
f1.write('f');
f1.write('f');
f1.write('f');
刷新(flush)
FileOutputStream f1 = new FileOutputStream("src/test/java/merge1.txt");
f1.write('f');
f1.write('f');
f1.write('f');
f1.write('f');
f1.flush();
技巧
FileOutputStream f1 = new FileOutputStream("src/test/java/merge1.txt");
FileInputStream f = new FileInputStream("src/test/java/merge.txt");
byte[] bytes = new byte[1024];
int r;
while ((r = f.read(bytes)) != -1) {
// 写入一个字节数组,从 0 开始, 传递 r个数据
f1.write(bytes, 0, r);
}
换行,兼容
在每一行的后面加换行
\n是在window种换行
\r\n是兼容平台
转成字节就可以实现
如果想实现追加数据,要在构造方法第二个参数设置true
默认会覆盖上次的数据
FileOutputStream f1 = new FileOutputStream("src/test/java/merge1.txt");
FileInputStream f = new FileInputStream("src/test/java/merge.txt");
byte[] a = {'a','v','h'};
int r = f.read();
f1.write('5');
f1.write("\r\n".getBytes());
f1.write('5');
f1.write("\r\n".getBytes());
f1.write('5');
f1.write("\r\n".getBytes());
f1.write('5');
f1.write("\r\n".getBytes());
f1.write('5');
文件拷贝
文件拷贝是都支持的,所有文件都是由字节组成
FileInputStream f = new FileInputStream("C:\\Users\\坤\\1.mp4");
FileOutputStream out = new FileOutputStream("C:\\Users\0.mp4");
byte[] r = new byte[1024];
int s;
while ((s = f.read(r)) != -1) {
out.write(r, 0, s);
}
out.close();
f.close();
小结
| 字节流适合做一切文件数据的拷贝吗? |
|---|
| 任何文件的底层都是字节,拷贝是一字不漏的转移字节 |
| 只要前后文件格式、编码一致没有任何问题 |
资源释放
try-catch-finally
将资源写在try后面的括号里,程序运行结束会自动关闭流
只能放资源,如果放其他的会报错
资源:是必须实现 AutoCloseable接口的
// 将资源写在try后面的括号里,程序运行结束会自动关闭流
try (
FileInputStream f = new FileInputStream("src/test/java/octoper/A11.java");
FileOutputStream f1 = new FileOutputStream("src/test/java/octoper/A12.java");
) {
} catch (IOException e) {
throw new RuntimeException(e);
}
JDK 9 的 try新增方式,有点不好用。了解即可
输入流,字符流(FileReader)
FileReader 中 read 读 跟字节流,读取的不一样,它是读取字符,其他一致
// 创建对象
FileReader f = new FileReader("src/test/java/octoper/A22.java");
如果用数组就不是byte数组,而是char数组
写入的时候可以一个字符串
字符流的好处,每次读取一个字符存在什么问题?
读取中文不会出现乱码(编码必须一致)
性能较慢(用字符数组方式较好)
缓冲流
缓冲流的原理?
缓冲流自带了8192的缓冲池,直接在这里读取 / 写入,性能较好
| 缓冲流的作用? | 缓冲流自带缓存区 |
|---|---|
| 可以提高原始字节流,字符类的性能 | |
| 缓冲流有几种? | |
| 字节缓冲流 | 输入流 BufferedInputStream |
| 输出流 BufferedOutputStream | |
| 字符缓冲流 | 输入流 BufferedReader |
| 输出流 BufferedWriter |
缓冲流传入一个普通流的对象
缓冲流 + 数组形式,很快 1G = 1s
缓冲字符流,会自带读取一行的方法
提供readLine 和 newLine这样读取一行和换行的方法
在读取和写入的时候,会调用flush刷新缓存
转换流(输入)
当编码不一致时,打印中文会出现乱码,需要转换
| 属于字符流 | |
|---|---|
| 字符输入转换流 | InputStreamReader |
| 字符输出转换流 | OutputStreamWriter |
创建转换流,默认字符编码 UTF-8
// 创建一个普通流
FileInputStream f = new FileInputStream("src/test/java/octoper/dddddd.java");
// 转换普通流 (默认字符编码 UTF-8)
InputStreamReader input = new InputStreamReader(f);
修改默认字符编码为GBK
// 创建一个普通流
FileInputStream f = new FileInputStream("src/test/java/octoper/dddddd.java");
// 转换普通流 (默认字符编码 UTF-8)
InputStreamReader input = new InputStreamReader(f,"GBK");
转换流(输出)
同样具备一个参数的构造
以指定字符,输出文件
修改默认字符编码为GBK
// 创建一个普通流
FileOutputStream f = new FileOutputStream("src/test/dddddd.java");
// 转换普通流 (默认字符编码 UTF-8)
OutputStreamWriter o = new OutputStreamWriter(f, "GBK");
字符输出转换流的作用?
可以指定编码把字节输出流转换成字符输出流,从而指定字符编码!
对象序列化
作用:以内存为基准,把内存中的对象存储到磁盘文件中去
对象序列化必须要实现 Serializable
public class Student implements Serializable {
实现步骤:
使用 writeObject 写入
// 创建学生对象
Student s = new Student("001","张三","18","河北");
// 创建序列化对象
ObjectOutputStream obj = new ObjectOutputStream(new FileOutputStream("src/test/java/merge1.txt"));
// 直接调用序列化方法
obj.writeObject(s);
// 释放
obj.close();
对象反序列化
作用:以内存为基准,把存储到磁盘文件中的对象数据恢复成内存中的对象
实现步骤:使用readObject 获取
// 创建序列化对象
ObjectInputStream obj = new ObjectInputStream(new FileInputStream("src/test/java/merge1.txt"));
// 直接调用序列化方法
Object o = obj.readObject();
System.out.println(o);
// 释放
obj.close();
细节:写在对象类里标准JavaBean
有些属性,不想参加序列化,添加 transient
private transient String name;
申明序列化的版本号码
序列化的版本号和反序列化的版本号,必须一致
private static final long serialVersionUID = 2;
打印流
作用:打印流可以实现方便、高效的打印数据到文件中去
// 创建打印流对象
PrintStream print = new PrintStream("src/test/java/merge1.txt");
// 直接调用打印方法
print.println(55);
print.write(55);
// 释放
print.close();
重点:打印流可以打印任何类型,构造方法可以传递对象和路径
print带Ln就是换行
细节:如果要追加数据,一定要在普通流里面加 true
| 打印流分为两种 | |
|---|---|
| PrintStream | PrintWriter |
| 打印功能两个一样 | 打印功能两个一样 |
| PrintStream 继承字节流 | 写入字节 |
| PrintWriter 继承字符流 | 写入字符 |
重定向(System.setOut)
// 创建打印流对象
PrintStream print = new PrintStream("src/test/java/merge1.txt");
// 修改打印位置(重定向)
System.setOut(print);
System.out.println("1111111111111");
// 释放
print.close();
属性集对象(properties)
其实就是一个Map集合
properties代表一个属性文件,可以把自己一个键值对信息存入到文件中
属性文件:后缀是.properties结尾的文件,里面的内容都是key=value,后续做系统配置信息的。
创建对象
Properties p = new Properties();
添加数据(setProperty)
// 创建对象
Properties p = new Properties();
// 添加数据
p.setProperty("key","value");
是键值对
输出到文件(store)
第一个参数:是一个输出流,第二个参数:是注释
// 创建对象
Properties p = new Properties();
// 添加数据
p.setProperty("key","value");
// 输出到 文件里
p.store(new FileWriter("src/test/java/merge1.properties"), "这里是心得");
读取数据(load)
第一个参数:是一个输入流
// 创建对象
Properties p = new Properties();
// 读取数据
p.load(new FileReader("src/test/java/merge1.properties"));
传入键获取值(getProperty)
// 创建对象
Properties p = new Properties();
// 读取数据
p.load(new FileReader("src/test/java/merge1.properties"));
// 根据键获取值
String key = p.getProperty("key");
System.out.println(key);
返回当前键的值
IO 框架
commons-io
复制文件
IOUtils.copy(new FileInputStream("需要复制的文件路径"),
new FileOutputStream("复制到哪里"));
复制文件,路径不存在也没关系
FileUtils.copyFileToDirectory(newFile("D:\\360downloads\\2052119.jpg"),
new File("D:\\B1aiduNetdiskDownload\\dada"));
复制文件夹到文件夹
FileUtils.copyDirectoryToDirectory(new File("D:\\360downloads"),
new File("D:\\dddd\\dda\\dc"));
删除文件夹,里面有文件也删除
FileUtils.deleteDirectory(new File("D:\\dddd\\dda\\dc"));
java自带的删除功能
复制文件到指定路径
Files.copy(Path.of("D:/"),Path.of("D:/aaa"));
删除文件,只可以删除空白的
Files.delete(new File("D:/"));
读取大数据框架
File file = new File("C:/Users/tb_sku1.sql");
try (LineIterator lineIterator = FileUtils.lineIterator(file, "UTF-8")) {
while (lineIterator.hasNext()) {
// 获取行数据
String line = lineIterator.next();
// 处理每一行的逻辑
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}














 14万+
14万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









