









APIServer
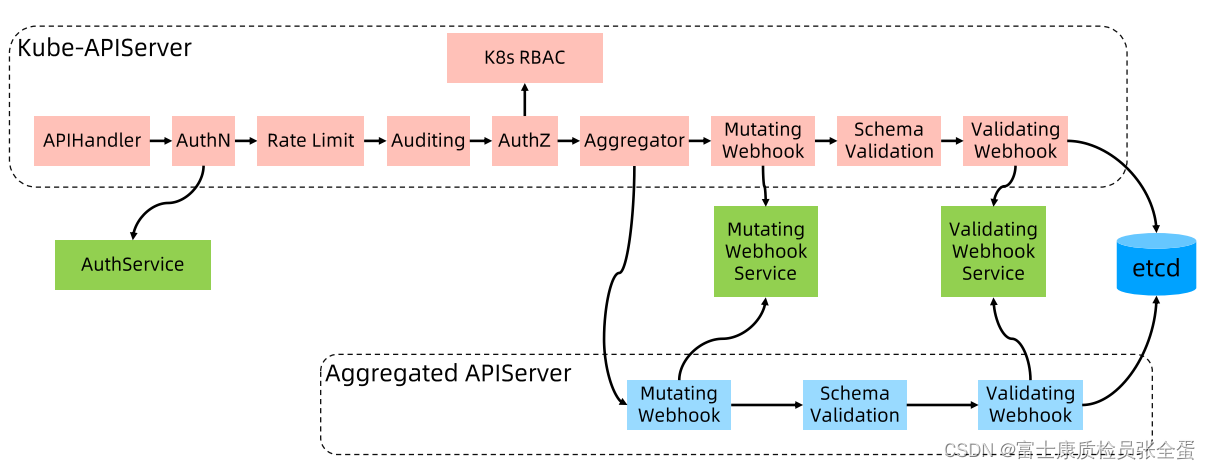
apiserver是一个rest server,他要去注册每个对象的handler,所以有个api handler的过程,接下来会去做认证,做完认证之后要去做限流,限流就是自我保护,每个apiserver节点都有承受上线的,如果不做限流那么很可能并发就将其打死了,之后来到audit做审计,任何的对象操作会记录log,为了日后的安全审查,在之后authz就是做鉴权的,k8s自己支持RBAC的,另外你也可以编写自己的webhook去做鉴权。
Aggregator:因为本身apiserver作为一个rest api,它其实是有能力和nginx反向代理软件一样来做一些路由配置,比如你是标准的k8s对象,那么你就走默认的k8s apiserver,那么muta valid就继续往下走了,所有路走完了就到etcd了,但是如果我有额外的扩展对象,这些额外的对象我不想在k8s本身实例里面去实现,我希望有自己的逻辑,那么就需要自己去写aggregated apiserver,aggregate会去看你这个对象在另外一个apiserver里面那么就会将请求转到这个aggregated apiserver,在之后的逻辑和上面是一样的,只不过是独立部署的apiserver。
-------------------------------------------------------------------------------------------------------------------------------
第三种 Metrics,是 Kubernetes 相关的监控数据。这部分数据,一般叫作 Kubernetes 核心监控数据(core metrics)。这其中包括了 Pod、Node、容器、Service 等主要 Kubernetes 核心概念的 Metrics。
其中,容器相关的 Metrics 主要来自于 kubelet 内置的 cAdvisor 服务。在 kubelet 启动后,cAdvisor 服务也随之启动,而它能够提供的信息,可以细化到每一个容器的 CPU 、文件系统、内存、网络等资源的使用情况。
需要注意的是,这里提到的 Kubernetes 核心监控数据,其实使用的是 Kubernetes 的一个非常重要的扩展能力,叫作 Metrics Server。
Metrics Server 在 Kubernetes 社区的定位,其实是用来取代 Heapster 这个项目的。在 Kubernetes 项目发展的初期,Heapster 是用户获取 Kubernetes 监控数据(比如 Pod 和 Node 的资源使用情况) 的主要渠道。而后面提出来的 Metrics Server,则把这些信息,通过标准的 Kubernetes API 暴露了出来。这样,Metrics 信息就跟 Heapster 完成了解耦,允许 Heapster 项目慢慢退出舞台。
而有了 Metrics Server 之后,用户就可以通过标准的 Kubernetes API 来访问到这些监控数据了。比如,下面这个 URL:
http://127.0.0.1:8001/apis/metrics.k8s.io/v1beta1/namespaces/<namespace-name>/pods/<pod-name>当你访问这个 Metrics API 时,它就会为你返回一个 Pod 的监控数据,而这些数据,其实是从 kubelet 的 Summary API (即 <kubelet_ip>:<kubelet_port>/stats/summary)采集而来的。Summary API 返回的信息,既包括了 cAdVisor 的监控数据,也包括了 kubelet 本身汇总的信息。
需要指出的是, Metrics Server 并不是 kube-apiserver 的一部分,而是通过 Aggregator 这种插件机制,在独立部署的情况下同 kube-apiserver 一起统一对外服务的。
这里,Aggregator APIServer 的工作原理,可以用如下所示的一幅示意图来表示清楚:
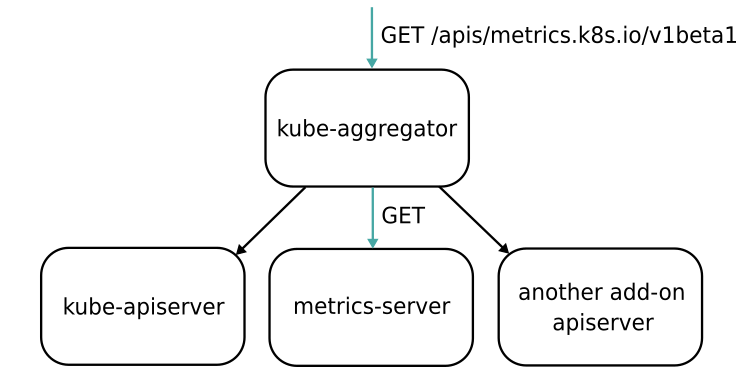
可以看到,当 Kubernetes 的 API Server 开启了 Aggregator 模式之后,你再访问 apis/metrics.k8s.io/v1beta1 的时候,实际上访问到的是一个叫作 kube-aggregator 的代理。而 kube-apiserver,正是这个代理的一个后端,而 Metrics Server,则是另一个后端。
而且,在这个机制下,你还可以添加更多的后端给这个 kube-aggregator。所以 kube-aggregator 其实就是一个根据 URL 选择具体的 API 后端的代理服务器。通过这种方式,我们就可以很方便地扩展 Kubernetes 的 API 了。
而 Aggregator 模式的开启也非常简单:
- 如果你是使用 kubeadm 或者官方的 kube-up.sh 脚本部署 Kubernetes 集群的话,Aggregator 模式就是默认开启的
- 如果是手动 DIY 搭建的话,你就需要在 kube-apiserver 的启动参数里加上如下所示的配置:
--requestheader-client-ca-file=<path to aggregator CA cert>
--requestheader-allowed-names=front-proxy-client
--requestheader-extra-headers-prefix=X-Remote-Extra
---requestheader-group-headers=X-Remote-Group
--requestheader-username-headers=X-Remote-User
--proxy-client-cert-file=<path to aggregator proxy cert>
--proxy-client-key-file=<path to aggregator proxy key>而这些配置的作用,主要就是为 Aggregator 这一层设置对应的 Key 和 Cert 文件。而这些文件的生成,就需要你自己手动完成了,具体流程请参考这篇官方文档。
Aggregator 功能开启之后,你只需要将 Metrics Server 的 YAML 文件部署起来,如下所示:
$ git clone https://github.com/kubernetes-incubator/metrics-server
$ cd metrics-server
$ kubectl create -f deploy/1.8+/接下来,你就会看到 metrics.k8s.io 这个 API 出现在了你的 Kubernetes API 列表当中。
pod的横向自动伸缩
横向pod自动伸缩是指由控制器管理 的pod副本数量的自动伸 缩。 它由Horizontal控制器执行, 我们通过创建 一个Horizontal pod Autoscaler HPA)资源来启用和配置Horizontal控制器。 该控制器周期性检查pod度量, 计算满足HPA 资源所配置的目标数值所需的副本数量, 进而调整目标资源(如Deployment、ReplicaSet、 ReplicationController、 StatefulSet等)的replicas字段。
了解自动伸缩过程
自动伸缩 的过程可以分为三个步骤:
- 获取被伸缩资源对象所管理的所有pod度量。
- 计算使度量数值到达(或接近)所指定目标数值所需的pod数量。
- 更新被伸缩资源的replicas字段。
获取pod度量

这样的数据流意味着在集群中必须运行Heapster才能实现自动伸缩。
核心API服务 器本身并不会向外界暴露度量数 据。 从1.7版本开始, Kubemetes允许注册多个API服务器并使它们对外呈现为单个API服务器。 这允许Kubemetes通过这些底层API服务器之一 来对外暴露度量数据。集群管理员负责选择集群中使用何种度量采集器。 我们通常需要 一 层简单的转换组件将度量数据以正确的格式暴露在正确的API路径下。
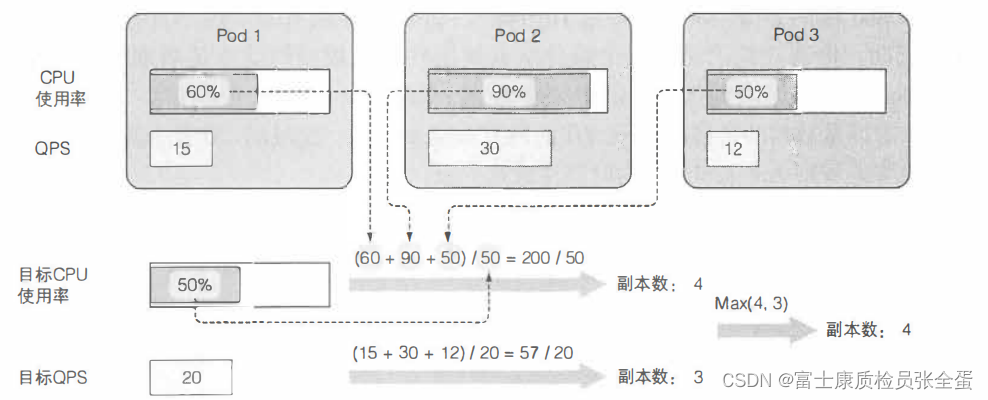
更新被伸缩资源的副本数

Pod自动扩容/缩容:HPA介绍

Pod自动扩容/缩容:HPA基本工作原理
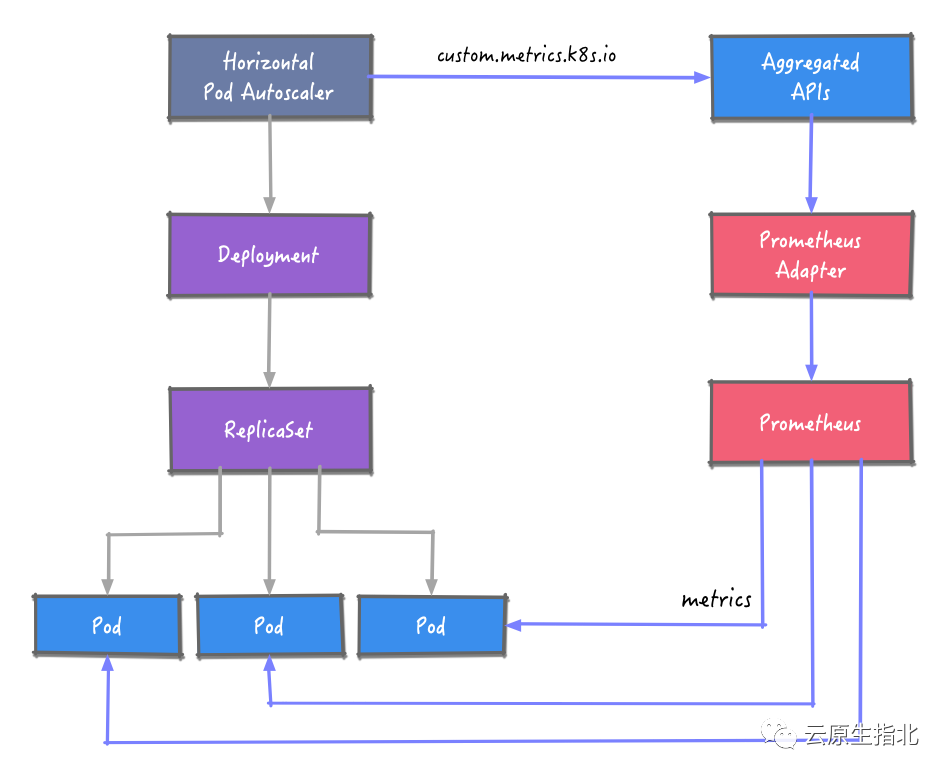
Kubernetes 中的 Metrics Server 持续采集所有 Pod 副本的指标数据(资源使用率由kubelet暴露出来,通过metrics server进行汇总,有了这个汇总的数据,HAP控制器就可以获取到pod资源的利用率,这样就可以基于资源利用率和HPA的阈值做对比,最后判断是否需要对pod做扩容/缩容)。
HPA 控制器通过 Metrics Server 的 API(聚合 API)获取这些数据,基于用户定义的扩缩容规则进行计算,得到目标 Pod 副本数量。当目标 Pod 副本数量与当前副本数量不同时,HPA 控制器就向 Pod 的Deployment控制器发起scale 操作,调整 Pod 的副本数量,完成扩缩容操作。

Pod自动扩容/缩容:使用HPA前提条件
使用HPA,确保满足以下条件:

聚合层就像nginx一样代理多个应用,并且可以根据在浏览器输入的uri转发到后端的不同应用,聚合层就是代理的作用,有了代理就可以让第三方应用注册到该api上面,访问这个api就可以访问这个代理。
HPA控制器会获取指标,这个指标从pod这里获取的,然后hpa对比这个指标和阈值,如果与阈值相同就去扩容
HPA-->apiserver-->获取指标-->pod
可以看到聚合层就扩展了api,部署metrics-server会注册到聚合层,访问该地址的时候就会转发到metrics-server上面,HPA控制器根据该指标做扩容的条件。
[root@master pki]# kubectl autoscale deployment nginx --min=2 --max=10 --cpu-percent=30
horizontalpodautoscaler.autoscaling/nginx autoscaled
[root@master pki]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx Deployment/nginx <unknown>/30% 2 10 1 22s根据不同的url访问不同的api帮你转发到后面不同的服务,只要你的服务可以注册到该聚合层就行
注册的接口名字也不一样
- 访问metrics.k8s.io API 资源接口会代理到metrics-server
- 访问 custom.metrics.k8s.io API 会代理到适配器上面
启用聚合层
- --proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.crt
- --proxy-client-key-file=/etc/kubernetes/pki/front-proxy-client.key
- --requestheader-allowed-names=front-proxy-client
- --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt
- --requestheader-extra-headers-prefix=X-Remote-Extra-
- --requestheader-group-headers=X-Remote-Group
- --requestheader-username-headers=X-Remote-User[root@k8s-master ~]# vim /opt/kubernetes/cfg/kube-apiserver.conf
...
--requestheader-client-ca-file=/opt/kubernetes/ssl/ca.pem \
--proxy-client-cert-file=/opt/kubernetes/ssl/server.pem \
--proxy-client-key-file=/opt/kubernetes/ssl/server-key.pem \
--requestheader-allowed-names=kubernetes \
--requestheader-extra-headers-prefix=X-Remote-Extra- \
--requestheader-group-headers=X-Remote-Group \
--requestheader-username-headers=X-Remote-User \
--enable-aggregator-routing=true \
...这个启用了就可以去做hpa了,所以这是前提条件
基于资源的指标,需要部署server-metrics组件
[root@master ~]# kubectl get apiservice
NAME SERVICE AVAILABLE AGE
v1. Local True 225d
v1.admissionregistration.k8s.io Local True 225d
v1.apiextensions.k8s.io Local True 225d
v1.apps Local True 225d
v1.authentication.k8s.io Local True 225d
v1.authorization.k8s.io Local True 225d
v1.autoscaling Local True 225d
v1.batch Local True 225d
v1.certificates.k8s.io Local True 225d
v1.coordination.k8s.io Local True 225d
v1.crd.projectcalico.org Local True 24d
v1.events.k8s.io Local True 225d
v1.monitoring.coreos.com Local True 4m43s
v1.networking.k8s.io Local True 225d
v1.radondb.com Local True 24d
v1.rbac.authorization.k8s.io Local True 225d
v1.scheduling.k8s.io Local True 225d
v1.storage.k8s.io Local True 225d
v1alpha1.monitoring.coreos.com Local True 24d
v1beta1.admissionregistration.k8s.io Local True 225d
v1beta1.apiextensions.k8s.io Local True 225d
v1beta1.authentication.k8s.io Local True 225d
v1beta1.authorization.k8s.io Local True 225d
v1beta1.batch Local True 225d
v1beta1.certificates.k8s.io Local True 225d
v1beta1.coordination.k8s.io Local True 225d
v1beta1.discovery.k8s.io Local True 225d
v1beta1.events.k8s.io Local True 225d
v1beta1.extensions Local True 225d
v1beta1.networking.k8s.io Local True 225d
v1beta1.node.k8s.io Local True 225d
v1beta1.policy Local True 225d
v1beta1.rbac.authorization.k8s.io Local True 225d
v1beta1.scheduling.k8s.io Local True 225d
v1beta1.storage.k8s.io Local True 225d
v2beta1.autoscaling Local True 225d
v2beta2.autoscaling Local True 225d
[root@master ~]# kubectl top node
error: Metrics API not available
[root@master ~]# kubectl top pod
error: Metrics API not availableMetrics Server:是一个数据聚合器,从kubelet收集资源指标,并通过Metrics API在Kubernetes apiserver暴露,以供HPA使用。(只做数据的收集,不做处理和存储)
这个就是让自己注册到apiserver里面的资源
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
k8s-app: metrics-server
name: v1beta1.metrics.k8s.io
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: metrics-server
namespace: kube-system
version: v1beta1
versionPriority: 100指定访问kubelet地址的类型,以逗号分隔,越靠前越以这种方式访问kubelet,最先使用的是使用内部IP去访问的
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
[root@k8s-master ~]# kubectl get node -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-master Ready master 94d v1.19.0 192.168.179.102 <none> CentOS Linux 7 (Core) 3.10.0-1160.2.2.el7.x86_64 docker://19.3.13优先使用这个ip去访问kubelet,因为上面列出的就是kubelet的信息 192.168.179.102
部署metrics-server
# wget https://github.com/kubernetes-sigs/metricsserver/releases/download/v0.3.7/components.yaml
# vi components.yaml
...
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --kubelet-insecure-tls
image: lizhenliang/metrics-server:v0.4.1
...
[root@k8s-master ~]# kubectl apply -f metrics-server.yaml
[root@k8s-master ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
metrics-server-b66888848-gdnrq 1/1 Running 0 74s
kubelet-insecure-tls∶不验证kubelet提供的https证书
查看聚合层API注册的状态
[root@k8s-master ~]# kubectl get apiservice
NAME SERVICE AVAILABLE AGE
v1beta1.metrics.k8s.io kube-system/metrics-server True <invalid>False (MissingEndpoints) 这个状态是没有关联到后端的pod,这就相对于代理的配置,如果关联到Pod这里时true的状态
测试api原始接口的地址,可以看到返回了json的字符串就说明正常工作的,可以看到节点cpu使用率
[root@k8s-master ~]# kubectl get --raw /apis/metrics.k8s.io/v1beta1/nodes
{"kind":"NodeMetricsList","apiVersion":"metrics.k8s.io/v1beta1","metadata":{"selfLink":"/apis/metrics.k8s.io/v1beta1/nodes"},"items":[{"metadata":{"name":"k8s-master","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/k8s-master","creationTimestamp":"2021-02-18T07:20:44Z"},"timestamp":"2021-02-18T07:19:43Z","window":"30s","usage":{"cpu":"300304738n","memory":"942972Ki"}},{"metadata":{"name":"k8s-node1","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/k8s-node1","creationTimestamp":"2021-02-18T07:20:44Z"},"timestamp":"2021-02-18T07:19:50Z","window":"30s","usage":{"cpu":"234243064n","memory":"646960Ki"}},{"metadata":{"name":"k8s-node2","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/k8s-node2","creationTimestamp":"2021-02-18T07:20:44Z"},"timestamp":"2021-02-18T07:19:52Z","window":"30s","usage":{"cpu":"313624781n","memory":"612420Ki"}}]}获取所有pod资源的消耗了
[root@k8s-master ~]# kubectl get --raw /apis/metrics.k8s.io/v1beta1/pods
{"kind":"PodMetricsList","apiVersion":"metrics.k8s.io/v1beta1","metadata":{"selfLink":"/apis/metrics.k8s.io/v1beta1/pods"},"items":[{"metadata":{"name":"nginx-6799fc88d8-drb2s","namespace":"default","selfLink":"/apis/metrics.k8s.io/v1beta1/namespaces/default/pods/nginx-6799fc88d8-drb2s","creationTimestamp":"2021-02-18T07:25:03Z"},"timestamp":"2021-02-18T07:24:46Z","window":"30s","containers":[{"name":"nginx","usage":{"cpu":"0","memory":"1892Ki"}}]},{"metadata":{"name":"calico-kube-controllers-5c6f6b67db-q5qb6","namespace":"ku上面说明直接请求uri是没有问题的
[root@k8s-master ~]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master 415m 41% 929Mi 72%
k8s-node1 269m 26% 632Mi 52%
k8s-node2 366m 36% 601Mi 46%
[root@k8s-master ~]# kubectl top node
Error from server (ServiceUnavailable): the server is currently unable to handle the request (get nodes.metrics.k8s.io)
[root@k8s-master ~]# kubectl top pod
NAME CPU(cores) MEMORY(bytes)
nginx-6799fc88d8-drb2s 0m 1Mi
[root@k8s-master ~]# kubectl top pod
Error from server (ServiceUnavailable): the server is currently unable to handle the request (get pods.metrics.k8s.io)Kubectl top <-apiserver<-metrics server<- kubelet(cadvisor)<-pod 现在就可以根据指标做弹性伸缩了
Pod自动扩容/缩容:基于资源指标
这里要配置resource,因为HPA的阈值的比对参考resource里面定义的
[root@k8s-master ~]# kubectl apply -f deployment.yaml
deployment.apps/web created
spec:
containers:
- image: nginx
name: nginx
resources:
requests:
cpu: 0.5
[root@k8s-master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
web-67bbbf48fc-9gpqh 1/1 Running 0 21s
[root@k8s-master ~]# kubectl expose deployment web --port=80 --target-port=80 --dry-run=client -o yaml > service.yaml
[root@k8s-master ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 95d
web ClusterIP 10.107.190.232 <none> 80/TCP 2s
[root@k8s-master ~]# curl 10.107.190.232:80
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>现在创建hap,这里只支持cpu指标
[root@k8s-master ~]# kubectl autoscale deployment web --min=2 --max=10 --cpu-percent=30
horizontalpodautoscaler.autoscaling/web autoscaled
[root@k8s-master ~]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
web Deployment/web 0%/30% 2 10 2 5m3syum install httpd-tools
ab -n 200000 -c 1000 http:/10.107.190.232/index.html # 总20w请求,并发1000[root@k8s-master ~]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
web Deployment/web 42%/30% 2 10 2 2m28s
[root@k8s-master ~]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
web Deployment/web 42%/30% 2 10 3 2m50s
[root@k8s-master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
web-67bbbf48fc-9gpqh 1/1 Running 0 25m
web-67bbbf48fc-cpfrz 1/1 Runing 0 2m1s
web-67bbbf48fc-zfth7 1/1 Running 0 14m可以看到扩容了副本数
Pod自动扩容/缩容:冷却周期
在弹性伸缩中,冷却周期是不能逃避的一个话题, 由于评估的度量标准是动态特性,副本的数量可能会不断波动,造成丢失流量,所以不应该在任意时间扩容和缩容。
不断的扩容缩容会造成流量的丢失,因为在不断的增加pod和删除pod
如果负载下去了,也不是马上帮你缩放到原来的个数,这个是有一个等待周期的
在 HPA 中,为缓解该问题,默认有一定控制:
--horizontal-pod-autoscaler-downscale-delay :当前操作完成后等待多次时间才能执行缩容操作,默认5分钟
- --horizontal-pod-autoscaler-upscale-delay :当前操作完成后等待多长时间才能执行扩容操作,默认3分钟
这两个参数是在control-manager当中配置的:
如果冷却时间太长的情况下,可能应对的负载不是很及时,给你增加pod扩容操作就不会很及时,设置太短,副本数就会出现抖动。















 436
436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









