







 本文详细介绍了Kubernetes网络插件Calico中IPIP与BGP两种模式的区别及配置过程。IPIP模式通过封装原始数据包利用宿主机网络进行传输,适合跨网段与VLAN;而BGP模式则适用于二层网络可达的情况,减少了数据包封装带来的性能损耗。
本文详细介绍了Kubernetes网络插件Calico中IPIP与BGP两种模式的区别及配置过程。IPIP模式通过封装原始数据包利用宿主机网络进行传输,适合跨网段与VLAN;而BGP模式则适用于二层网络可达的情况,减少了数据包封装带来的性能损耗。
IpIp模式是通过宿主机的网络去传输的,这个模式和flannel的vxlan工作模式差不多是一样的,都是一种复杂的网络方案,IPIP和vxlan模式的性能基本上接近,所以在性能方面要相对于路由方面损失10-20%。
Calio和flannel一样也支持路由方案,在calio里面使用了BGP路由方案去实现的,BGP就是基于路由去转发的,每个节点通过BGP协议同步路由表,将每个节点作为路由器转发。
现在要将IPIP模式改为BGP模式。
[root@k8s-master ~]# calicoctl get ippool -o wide
NAME CIDR NAT IPIPMODE VXLANMODE DISABLED SELECTOR
default-ipv4-ippool 10.244.0.0/16 true Always Never false all()
[root@k8s-master calico]# calicoctl get ippool -o yaml > ippool.yaml
[root@k8s-master calico]# vim ippool.yml
ipipMode: Always这里是启用了ipip模式,设置为never就是关闭了ipip模式就会采用BGP模式
ipipMode: Never[root@k8s-master calico]# calicoctl apply -f ippool.yaml
Successfully applied 1 'IPPool' resource(s)
[root@k8s-master ~]# calicoctl get ippool -o wide
NAME CIDR NAT IPIPMODE VXLANMODE DISABLED SELECTOR
default-ipv4-ippool 10.244.0.0/16 true Never Never false all() IPIPMODE:Never 这样ipip模式关闭使用bgp,现在没有配置IP了,通过这个可以判断有没有成功
[root@k8s-master calico]# ip addr
4: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 1440 qdisc noqueue state UNKNOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
inet 10.244.235.192/32 brd 10.244.235.192 scope global tunl0
valid_lft forever preferred_lft forever这里tul0网卡就没用了,因为不需要封包,所以容器内部的数据到达到宿主机直接从网卡出去了,BGP模式相对于ipip模式少了tul0设备的介入,数据的封装
[root@k8s-master ~]# ip route
default via 192.168.179.2 dev ens32 proto static metric 100
10.244.36.64/26 via 192.168.179.103 dev ens32 proto bird
10.244.169.128/26 via 192.168.179.104 dev ens32 proto bird 这里没有tul0的路由了,数据包到达宿主机上面了,根据这个路由表去转发。这个和flannel的hgw是一样的。

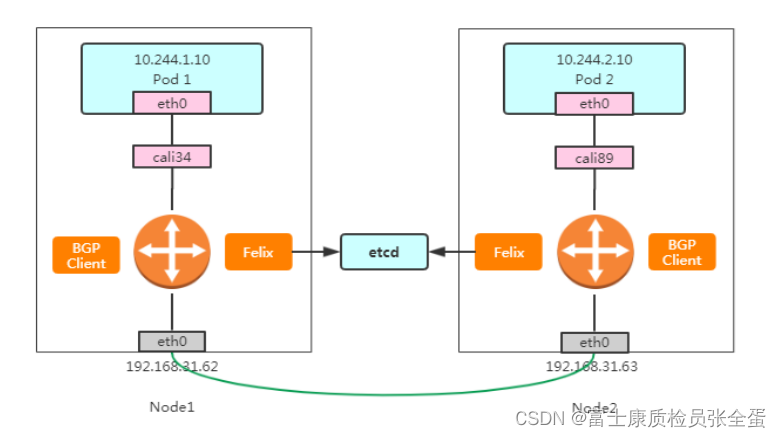
K8s网络组件之Calico:Route Reflector 模式(RR)
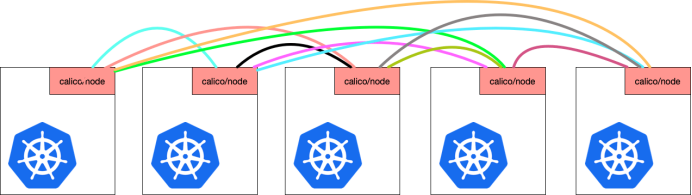
Calico 维护的网络在默认是(Node-to-Node Mesh)全互联模式,Calico集群中的节点之间都会相互建立连接,用于路由交换。但是随着集群规模的扩大,mesh模式将形成一个巨大服务网格,连接数成倍增加,就会产生性能问题。这时就需要使用 Route Reflector(路由器反射)模式解决这个问题。
[root@k8s-master calico]# calicoctl node status
Calico process is running.
IPv4 BGP status
+-----------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+-----------------+-------------------+-------+----------+-------------+
| 192.168.179.103 | node-to-node mesh | up | 06:49:37 | Established |
| 192.168.179.104 | node-to-node mesh | up | 06:48:39 | Established |
+-----------------+-------------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.三个节点之间都建立了互连的关系,也就是一个节点要和其他节点建立TCP连接,这个就是BGP之间互联通信,要是节点好多的话连接就会好多。
这个就是BGP client里面有个进程叫bird,这个bird就是负责BGP协议的通信完成路由表学习,随着连接的增多,下面这两个也会增多,使用的端口是179。
[root@k8s-master ~]# ss -antp | grep ESTAB | grep bird
ESTAB 0 0 192.168.179.102:179 192.168.179.104:36323 users:(("bird",pid=3517,fd=8))
ESTAB 0 0 192.168.179.102:179 192.168.179.103:33128 users:(("bird",pid=3517,fd=9))
[root@k8s-node1 ~]# ss -antp | grep ESTAB | grep bird
ESTAB 0 0 192.168.179.103:179 192.168.179.104:41043 users:(("bird",pid=3098,fd=8))
ESTAB 0 0 192.168.179.103:33128 192.168.179.102:179 users:(("bird",pid=3098,fd=9))
[root@k8s-node2 ~]# ss -antp | grep ESTAB | grep bird
ESTAB 0 0 192.168.179.104:36323 192.168.179.102:179 users:(("bird",pid=2320,fd=8))
ESTAB 0 0 192.168.179.104:41043 192.168.179.103:179 users:(("bird",pid=2320,fd=9))在每个节点启动的BGP pod 这里面就包含了bgp client和flex
[root@k8s-master calico]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-node-6hgrq 1/1 Running 2 81d
calico-node-jxh4t 1/1 Running 2 81d
calico-node-xjklb
[root@k8s-master calico]# netstat -tpln | grep 179
tcp 0 0 0.0.0.0:179 0.0.0.0:* LISTEN 3147/bird K8s网络组件之Calico:BGP工作模式
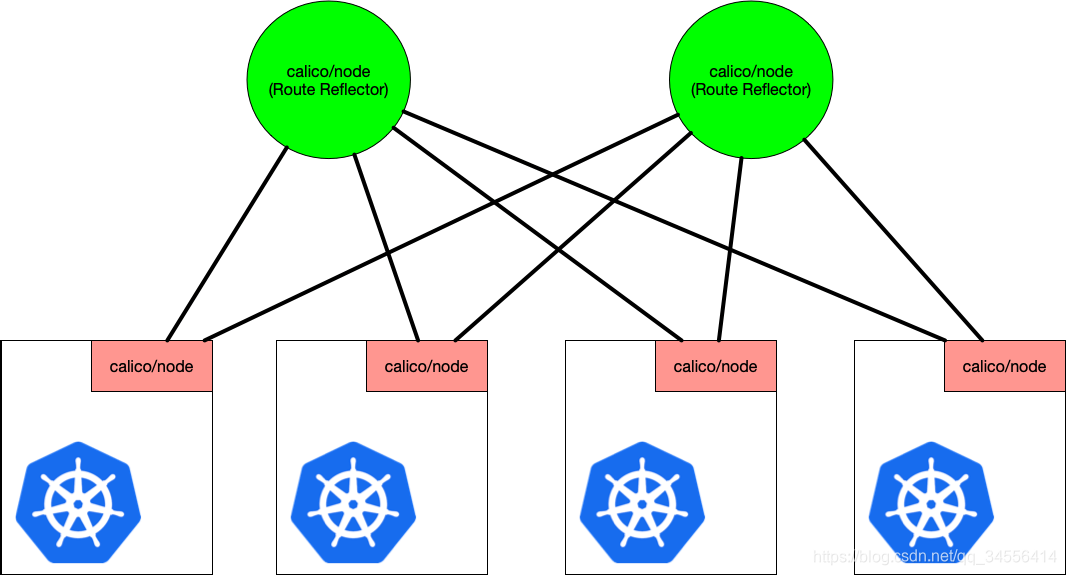
为了解决上面问题,使用路由反射,从集群当中找出两个节点,这两个节点是自己选择的,将这两个节点当作路由反射器,让其他的BGP client通过这两个节点获取路由表的信息,这两个路由反射器相对于代理的角色,其他人都是从这获取路由表的学习,那么压力就集中在这两台,做路由的集中下发,BGP client就是从这里面获取所有的路由表。所以每个节点只要和路由反射器建立关系就行,有两个路由反射器就建立两个连接。
关闭node to node模式就代表网络不通了,当完整切换了,网络就可以使用了
[root@k8s-master calico]# calicoctl get bgpconfig
NAME LOGSEVERITY MESHENABLED ASNUMBER
[root@k8s-master ~]# calicoctl get node -o wide
NAME ASN IPV4 IPV6
k8s-master (64512) 192.168.179.102/24
k8s-node1 (64512) 192.168.179.103/24
k8s-node2 (64512) 192.168.179.104/24 调整as的编号
[root@k8s-master calico]# vim bgpconfig.yaml
[root@k8s-master calico]# cat bgpconfig.yaml
apiVersion: projectcalico.org/v3
kind: BGPConfiguration
metadata:
name: default
spec:
logSeverityScreen: Info
nodeToNodeMeshEnabled: false
asNumber: 64512
[root@k8s-master calico]# calicoctl apply -f bgpconfig.yaml
Successfully applied 1 'BGPConfiguration' resource(s)
[root@k8s-master calico]# calicoctl get bgpconfig
NAME LOGSEVERITY MESHENABLED ASNUMBER
default Info false 64512 在其他节点访问不了Pod了
[root@k8s-master ~]# ping 10.244.169.138
PING 10.244.169.138 (10.244.169.138) 56(84) bytes of data.
[root@k8s-master ~]# calicoctl node status
Calico process is running.
IPv4 BGP status
No IPv4 peers found.
IPv6 BGP status
No IPv6 peers found.kubectl label node k8s-node2 route-reflector=true给选定的节点指定路由反射器ID: routeReflectorClusterID这个可以写任意集群当中
没有使用的ip
[root@k8s-master ~]# calicoctl get node k8s-node2 -o yaml > rr-node.yaml
[root@k8s-master ~]# vim rr-node.yaml
bgp:
ipv4Address: 192.168.179.104/24
routeReflectorClusterID: 244.0.0.1
[root@k8s-master ~]# calicoctl apply -f rr-node.yaml
Successfully applied 1 'Node' resource(s)3、使用标签选择器将路由反射器节点与其他非路由反射器节点配置为对等
匹配所有节点带有这个标签的作为路由反射器,这就是非路由反射器和路由反射器建立关系
[root@k8s-master calico]# vi bgppeer.yaml
[root@k8s-master calico]# calicoctl apply -f bgppeer.yaml
Successfully applied 1 'BGPPeer' resource(s)
[root@k8s-master calico]# cat bgppeer.yaml
apiVersion: projectcalico.org/v3
kind: BGPPeer
metadata:
name: peer-with-route-reflectors
spec:
nodeSelector: all()
peerSelector: route-reflector == 'true'
[root@k8s-master calico]# calicoctl get bgppeer
NAME PEERIP NODE ASN
peer-with-route-reflectors all() 0 现在网络就可以通了
[root@k8s-master ~]# ping 10.244.169.163
PING 10.244.169.163 (10.244.169.163) 56(84) bytes of data.
64 bytes from 10.244.169.163: icmp_seq=1 ttl=63 time=4.57 ms
64 bytes from 10.244.169.163: icmp_seq=2 ttl=63 time=0.306 ms
64 bytes from 10.244.169.163: icmp_seq=3 ttl=63 time=0.722 ms
[root@k8s-master calico]# ss -antp | grep ESTAB | grep 179 | grep bird
ESTAB 0 0 192.168.179.102:179 192.168.179.104:57580 users:(("bird",pid=3147,fd=8))
[root@k8s-node2 ~]# ss -antp | grep ESTA | grep bird
ESTAB 0 0 192.168.179.104:179 192.168.179.103:49411 users:(("bird",pid=2320,fd=8))
ESTAB 0 0 192.168.179.104:47748 192.168.179.102:179 users:(("bird",pid=2320,fd=9))
[root@k8s-master calico]# calicoctl node status
Calico process is running.
IPv4 BGP status
+-----------------+---------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+-----------------+---------------+-------+----------+-------------+
| 192.168.179.104 | node specific | up | 08:18:00 | Established |
+-----------------+---------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.最好两个路由反射节点,有个节点down了 还可以另外有个,这样节点就可以获取到路由表。
总结ipip模式和BGP模式
IPIP模式先进行原始数据包的封装,然后通过宿主机网络去封装,解封装是一样的,但是这种封装拆解是有性能的消耗
这种可以跨网段跨vlan只要两个网络可以Ping通就行,不管是同一个机房还是不同的机房,只要三层可达就行。
BGP模式对宿主机的要求是二层网络可达,如果节点是跨vlan的网络,那么就需要在该节点的路由器上面做相关的配置

















 2736
2736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









