







Iptables模式
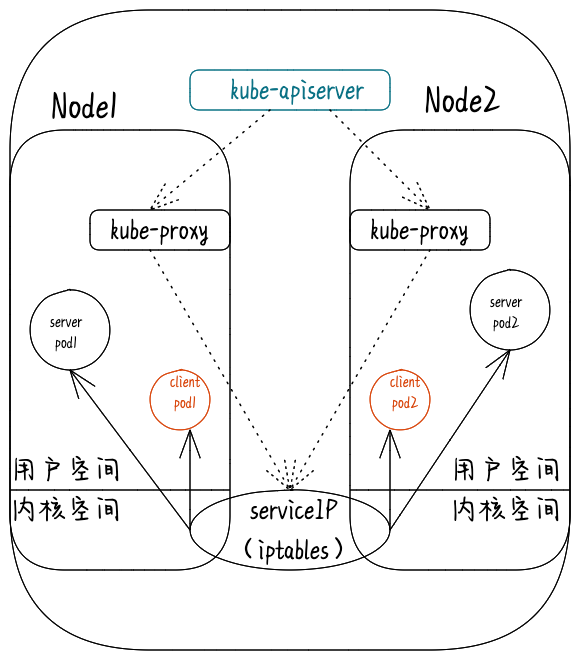
kube-proxy 就可以通过 Service 的 Informer 感知到API Server中service和endpoint的变化情况。而作为对这个事件的响应,它就会在宿主机上创建这样一条 iptables 规则(你可以通过 iptables-save 看到它)。这些规则捕获到service的clusterIP和port的流量,并将这些流量随机重定向到service后端Pod。对于每个endpoint对象,它生成选择后端Pod的iptables规则。
如果选择的第一个Pod没有响应,kube-proxy将检测到到第一个Pod的连接失败,并将自动重试另一个后端Pod,拓扑图:

iptables 是一个 Linux 内核功能,是一个高效的防火墙,并提供了大量的数据包处理和过滤方面的能力。它可以在核心数据包处理管线上用 Hook 挂接一系列的规则。iptables 模式中 kube-proxy 在 NAT pre-routing Hook 中实现它的 NAT 和负载均衡功能。这种方法简单有效,依赖于成熟的内核功能,并且能够和其它跟 iptables 协作的应用融洽相处。
因为它纯粹是为防火墙而设计且基于内核规则列表,kube-proxy 使用的是一种 O(n) 算法,其中的 n 随集群规模同步增长,所以这里的集群规模越大,更明确的说就是服务和后端 Pod 的数量越大,查询的时间就会越长。
一个例子是,在5000节点集群中使用 NodePort 服务,如果我们有2000个服务并且每个服务有10个 pod,这将在每个工作节点上至少产生20000个 iptable 记录,这会使内核非常繁忙。
结论:
kube-proxy 通过 iptables 处理 Service 的过程,其实需要在宿主机上设置相当多的 iptables 规则。而且,kube-proxy 还需要在控制循环里不断地刷新这些规则来确保它们始终是正确的。不难想到,当你的宿主机上有大量 Pod 的时候,成百上千条 iptables 规则不断地被刷新,会大量占用该宿主机的 CPU 资源,甚至会让宿主机“卡”在这个过程中。所以说,一直以来,基于 iptables 的 Service 实现,都是制约 Kubernetes 项目承载更多量级的 Pod 的主要障碍。
ipvs模式
在 IPVS 模式下,kube-proxy监视Kubernetes服务和端点,调用 netlink 接口创建 IPVS 规则, 并定期将 IPVS 规则与 Kubernetes 服务和端点同步。访问服务时,IPVS 将流量定向到后端Pod之一。
IPVS代理模式基于类似于 iptables 模式的 netfilter 挂钩函数, 但是使用哈希表作为基础数据结构,并且在内核空间中工作。这意味着,与 iptables 模式下的 kube-proxy 相比,IPVS 模式下的 kube-proxy 重定向通信的延迟要短,并且在同步代理规则时具有更好的性能。与其他代理模式相比,IPVS 模式还支持更高的网络流量吞吐量。
10: kube-ipvs0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default
link/ether 96:7e:09:cd:6a:ac brd ff:ff:ff:ff:ff:ff
inet 10.96.0.10/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
inet 10.96.0.1/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
inet 10.104.8.77/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
[root@k8s-node1 ~]# ping 10.96.0.10
PING 10.96.0.10 (10.96.0.10) 56(84) bytes of data.
64 bytes from 10.96.0.10: icmp_seq=1 ttl=64 time=29.5 ms
64 bytes from 10.96.0.10: icmp_seq=2 ttl=64 time=0.048 ms
[root@k8s-node2 ~]# ifconfig kube-ipvs0
kube-ipvs0: flags=130<BROADCAST,NOARP> mtu 1500
inet 10.96.0.10 netmask 255.255.255.255 broadcast 0.0.0.0
ether 02:e3:af:f9:dc:10 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0[root@k8s-node1 ~]# ifconfig kube-ipvs0
kube-ipvs0: flags=130<BROADCAST,NOARP> mtu 1500
inet 10.104.8.77 netmask 255.255.255.255 broadcast 0.0.0.0
ether 76:59:81:85:9d:6c txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0[root@k8s-master ~]# ifconfig kube-ipvs0
kube-ipvs0: flags=130<BROADCAST,NOARP> mtu 1500
inet 10.96.0.10 netmask 255.255.255.255 broadcast 0.0.0.0
ether 96:7e:09:cd:6a:ac txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
IPVS 模式的工作原理,其实跟 iptables 模式类似。当我们创建了前面的 Service 之后,kube-proxy 首先会在宿主机上创建一个虚拟网卡(叫作:kube-ipvs0),并为它分配 Service VIP 作为 IP 地址。接下来,kube-proxy 就会通过 Linux 的 IPVS 模块,为这个 IP 地址设置三个 IPVS 虚拟主机,并设置这三个虚拟主机之间使用轮询模式 (rr) 来作为负载均衡策略。拓扑图如下所示拓扑图:

IPVS 是一个用于负载均衡的 Linux 内核功能。IPVS 模式下,kube-proxy 使用 IPVS 负载均衡代替了 iptable。这种模式同样有效,IPVS 的设计就是用来为大量服务进行负载均衡的,它有一套优化过的 API,使用优化的查找算法,而不是简单的从列表中查找规则。
这样一来,kube-proxy 在 IPVS 模式下,其连接过程的复杂度为 O(1)。换句话说,多数情况下,他的连接处理效率是和集群规模无关的。
另外作为一个独立的负载均衡器,IPVS 包含了多种不同的负载均衡算法,例如轮询、最短期望延迟、最少连接以及各种哈希方法等。而 iptables 就只有一种随机平等的选择算法。IPVS一个潜在缺点是,与正常情况下的数据包相比,由IPVS处理的数据包通过iptables筛选器hook的路径不同。如果打算将IPVS与其他使用iptables的程序一起使用,则需要研究它们是否可以一起正常工作。不过Ipvs代理模式已经推出很久了,很多组件已经适配的很好了,比如Calico。

结论:
IPVS是专门设计用来做内核四层负载均衡的,由于使用了hash表的数据结构,因此相比iptables来说性能会更好。基于IPVS实现Service转发,Kubernetes几乎能够具备无限的水平扩展能力。随着Kubernetes的部署规模越来越大,应用越来越广泛,IPVS必然会取代iptables成为Kubernetes Service的默认实现后端。
总结
IPVS (IP Virtual Server,IP虚拟服务器)是基于Netfilter的、作为linux内核的一部分实现传输层负载均衡的技术,通常称为第4层LAN交换。IPVS集成在LVS(Linux Virtual Server)中,它在主机中运行,并在真实服务器集群前充当负载均衡器。IPVS可以将对TCP/UDP服务的请求转发给后端的真实服务器,并使真实服务器的服务在单个IP地址上显示为虚拟服务。因此IPVS天然支持Kubernetes Service。
- 随着kubernetes使用量的增长,其资源的可扩展性变得越来越重要。特别是对于使用kubernetes运行大型工作负载的开发人员或者公司来说,service的可扩展性至关重要。kube-proxy是为service构建路由规则的模块,之前依赖iptables来实现主要service类型的支持,比如(ClusterIP和NodePort)。但是iptables很难支持上万级的service,因为iptables纯粹是为防火墙而设计的,并且底层数据结构是内核规则的列表。
- 而相比于 iptables,IPVS 在内核中的实现其实也是基于 Netfilter 的 NAT 模式,所以在转发这一层上,理论上 IPVS 并没有显著的性能提升。但是,IPVS 并不需要在宿主机上为每个 Pod 设置 iptables 规则,而是把对这些“规则”的处理放到了内核态,从而极大地降低了维护这些规则的代价。
- kubernetes早在1.6版本就已经有能力支持5000多节点,这样基于iptables的kube-proxy就成为集群扩容到5000节点的瓶颈。举例来说,如果在一个5000节点的集群,我们创建2000个service,并且每个service有10个pod,那么我们就会在每个节点上有至少20000条iptables规则,这会导致内核非常繁忙。基于IPVS的集群内负载均衡就可以完美的解决这个问题。IPVS是专门为负载均衡设计的,并且底层使用哈希表这种非常高效的数据结构,几乎可以允许无限扩容。不过需要注意的是,IPVS 模块只负责上述的负载均衡和代理功能。而一个完整的 Service 流程正常工作所需要的包过滤、SNAT 等操作,还是要靠 iptables 来实现。只不过,这些辅助性的 iptables 规则数量有限,也不会随着 Pod 数量的增加而增加。
IPVS模式在Kubernetes v1.8中引入,并在v1.9中进入了beta。1.11中实现了GA(General Availability)。IPTABLES模式在v1.1中添加,并成为自v1.2以来的默认操作模式。IPVS和IPTABLES都基于netfilter。IPVS模式和IPTABLES模式之间的差异如下:
- IPVS为大型集群提供了更好的可扩展性和性能。(规则的存储方式使用的数据结构更高效)
- IPVS支持比iptables更复杂的负载平衡算法(rr:循环,lc:最少连接,dh:目标散列,sh:源哈希,sed:最短的预期延迟,nq:从不排队)。
- IPVS支持服务器健康检查和连接重试等。
在集群中不超过1000个服务的时候,iptables 和 ipvs 并无太大的差异。而且由于iptables 与网络策略实现的良好兼容性,iptables 是个非常好的选择。当你的集群服务超过1000个时,而且服务之间链接大多没有开启keepalive,IPVS模式可能是一个不错的选择。
参考文章:
https://kubernetes.io/blog/2018/07/09/ipvs-based-in-cluster-load-balancing-deep-dive/
https://cloud.tencent.com/developer/article/1470033
https://blog.csdn.net/qq_36807862/article/details/106068871















 6984
6984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









