







HTK学习笔记(一)
一、HTK软件体系结构
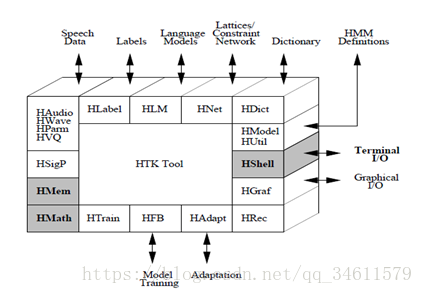
HTK的软件体系结构
HTKTool各部分的功能:
所有的语音输入和输出都是通过HWAVE或HPARM
HAudio:用于从音频设备输入波形
HWave:用于从文件中读取波形
HSLab:波形显示工具,可以用于采集语音数据并且进行手动标注
HSigP:用于语音处理的数据流输出,支持语音分析中使用到的信号处理操作
HVQ:用于语音处理的数据流输出
参数化编码由HParm使用HSigP中定义的信号处理操作进行。HParm的输出是observation形式的参数向量,observation是HTK训练和识别工具数据处理的基本单元
HShell:用户的输入输出以及与操作系统的接口
HMem:内存管理
HMath:数学支持
HLabel:标签文件的HTK接口由模块HLabel提供,它实现了MLF(主标签文件)设施,并支持许多外部标签格式
HLM:对应语言模型文件
HNet:对应网络和词图文件
HDict:对应词典文件, 加载和操作字典的工具
HParse: 允许从包含扩展的BNF格式语法规则的源文本生成网络
HBuild: 直接在SLF级别工作,以提供这种详细的控制, 主要功能是使一个大的单词网络被分解成一组小的自包含的子网络,并将其作为输入扩展的SLF格式
HBuild还可以用于执行一些特殊用途的功能。首先,它可以自动构造单词循环和单词对语法。其次,它可以将统计双字母语言模型合并到网络中。这些可以通过使用HLStats的标签转录产生.
HDMan: 允许从不同来源自动构造字典, 可以用来编辑和合并不同的源字典,从而形成统一的统一字典
HSGen: 该工具将使用随机抽样从SLF网络生成示例单词序列, 能够检查最后的单词网络定义的语言是否与预期的一样是有用的, 还将通过记录每个句子产生的概率来估计经验熵
HGraf:支持简单的交互图形
HUtil:支持一些utility routines,用于操控HMMs,HTRAIN和HFB支持各种HTK训练工具。
HModel:对应HMM模型文件
HAdapt:支持各种HTK调整工具
HRec:包含主要的识别处理函数, 解码器模块
HLed:简单的批处理编辑
HList:用于检查和调试数据转换参数的配置是否有效,检查音频数据格式的最简单的方法,检查音频输入转换是否正确的进行。
可用于显示音频文件的内容,一般它会显示三种文件信息:
1,源文件头信息:需要使用-h选项
2,目标文件头信息:需要使用-t选项
3,目标文件数据:默认显示的信息,可使用-s和-e选项显示指定位置段的采样数据。
HCopy:用于拷贝和操作语音数据的通用工具;可以通过语音输入输出子系统读入各种格式的语音文件,然后通过合适的配置参数文件,就可以进行语音数据参数化编码
HTK提供了用于参数估计的基本工具:HCompV、HInit、HRest、HERest和HMMIRest(Version 3.4中的新功能)。HCompV和HInit用于初始化。HCompV将会将每个高斯分量的均值和方差设为一个HMM,以等于语音训练数据的全局平均值和方差
HRest和HERest是使用Baum-Welch重新估计的现有HMMs的参数。与HInit一样,HRest执行隔离单元训练,而HERest则操作完整的模型集,并执行嵌入单元训练。一般来说,全词HMMs都是使用HInit和HRest构建的,并且基于HCompV或HInit和HRest初始化的HERest构建了连续语音子系统
HERest:用于调用嵌入式训练工具
HERest:执行离线的托管自适应,它使用不同形式的线性变换和(或)最大A-posteriori(MAP)算法
HVite:执行非托管自适应,它只使用线性变换,这时HVite不只进行识别,同时也在处理待识别数据时进行自使用训练. 它是一个简单的shell程序,它允许HRec从命令行驱动。
应使用HERest执行基于线性变换的,托管的,增量的自适应训练
HResults: 计算单词的准确性和各种相关的统计信息,较了HVite的转录输出与原始的参考转录,然后输出各种统计数据,通过动态编程执行最优的字符串匹配,匹配每个被识别和引用的标签序列
HLSTATS:可以获得标注文本的统计信息
HQUANT:可以构建VQ codebook, 为构建离散概率HMM系统作准备。
二、语言模型
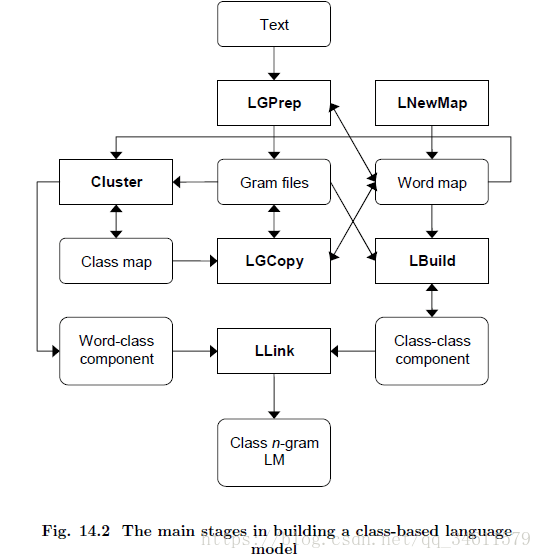
2.1 n-Gram的建造过程
使用HTK工具构建n-gram语言模型的整个过程。
给定一些输入文本,工具LGPrep扫描输入字序列并计算n-g;当遇到新的n-gram时,这些n-gram计数存储在一个缓冲区中。当这个缓冲区满时,它内部的n-g被分类并存储在一个gram文件中。所有的单词(和符号一般)都由一个唯一的整数id在HTK中表示,从单词到id的映射被记录在一个单词映射中。在启动时,在现有的单词映射中使用LGPrep加载,然后在输入文本中遇到的每个新单词都被分配一个新的id并添加到映射中。完成后,LGPrep输出新的更新后的word映射。如果输入更多的文本,这个过程就会重复,因此随着越来越多的数据被处理,单词map将会扩展。
虽然LGPrep的每一个gram文件的输出都是有序的,但是单个文件中n克的范围将会重叠。要构建一个语言模型,所有n-gram计数必须按排序顺序输入,以便能够将具有相同历史的单词分组。为了适应这种情况,所有HTK语言建模工具都可以读取多个gram文件并对它们进行实时排序。但是,这可能是低效的,因此,使用HLM工具LGCopy首先复制一组新生成的gram文件是很有用的。这就产生了一组被排序的gram文件,即每个gram文件中n-g的范围不重叠,因此可以在单个流中读取。此外,由于不同文件中相同的n-gram的计数将被合并,因此序列文件将占用更少的磁盘空间。
一组(可能有顺序的)gram文件及其相关的word地图提供了构建n-gram LM的原始数据。构建过程的下一个阶段是定义LM的词汇表,并转换所有包含OOV(不含词汇)单词的n-g,以便每个OOV单词被一个表示未知类的单个符号所取代。把OOV词赋给一类不知名的词是一个更通用的机制的具体例子。在HTK中,任何单词都可以通过在类映射文件中列出来与指定的类关联。可以通过列出类成员或列出所有非成员来定义类。为了定义未知类,将使用后者,因此将提供所有词汇表词的纯文本列表,并将所有其他单词映射到OOV类。工具LGCopy可以使用类图来复制一套克文件中列出的所有单词类地图取而代之的是类名,并输出一个字地图这只包含所需的词汇和他们的id +任何类和id。
如图所示,LM本身是使用工具LBuild构建的。这需要输入gram文件和word map,并生成所需的LM。语言模型可以在步骤中构建(首先是一个unigram,然后是一个bigram,然后是一个trigram,等等),或者如果需要的话,可以在一个通道中创建。

2.2 基于类的语言模型
在类中有相关的单词计数或概率,允许对wordgivenclass概率bigram p(wkjck)进行评估。这些文件可能会被链接到一个单一的复合文件中,或者第三个“链接”文件被创建来指向这两个单独的文件——这两个操作都可以使用LLink工具来执行。
给定一组在类映射文件中定义的单词类和一组单词级别的gram文件,使用HTK工具构建基于类的模型只需要对上面描述的基本过程进行一些简单的修改,就可以构建一个单词n-gram:
l Cluster集群使用从源文本派生的word map和word level gram文件来构造一个类映射,它定义了每个单词所在的类。然后使用相同的工具生成上面提到的单词类组件文件。注意,集群还可以用于从现有的或手动生成的类映射生成此文件。
l LGCopy与类映射一起使用,将从源文本派生的单词level gram文件转换为类gram文件。然后,LBuild可以直接使用类级别的gram文件来构建上面提到的类序列n-gram语言模型。
l 然后运行LLink来创建一个语言模型脚本,指向两个单独的语言模型文件或单个复合文件。最终的语言模型就可以使用了。
这个过程的主要步骤如图:
三、HTK语音模型工具
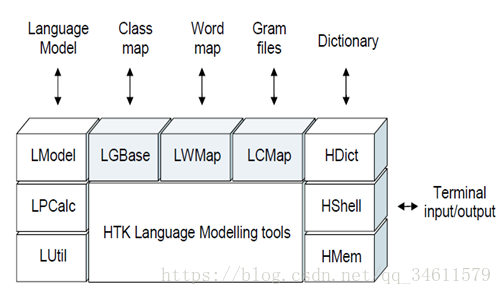
三种基本类型的数据文件:gram文件、word地图文件和类映射文件。如图所示,每个文件类型都由一个特定的HTK模块支持,该模块提供所需的输入和输出以及其他相关操作。
语言模型跟踪:每一个HTK语言建模工具都提供了自己的跟踪工具,如第17章中的相关工具所记录。标准库还提供了自己的跟踪设置,可以在已通过的配置文件中设置。每个受支持的跟踪级别都被记录在下面,并有必要的八进制值来启用它。
LCMap:
0001 Toplevel tracing
0002 Classmap loading
LGBase:
0001 Top level tracing
0002 Trace n-gram squashing
0004 Trace n-gram buffersorting
0010 Display n-gram input settree
0020 Display maximum parallelinput streams
0040 Trace parallel inputstreaming
0100 Display information onFoF input/output
LModel:
0001 Top level tracing
0002 Trace loading of languagemodels
0004 Trace saving of languagemodels
0010 Trace word mappings
0020 Trace n-gram lookup
LPCalc:
0001 Top level tracing
0002 FoF table tracing
LPMerge:
0001 Top level tracing
LUtil:
0001 Top level tracing
0002 Show header processing
0004 Hash table tracing
LWMap:
0001 Top level tracing
0002 Trace word map loading
0004 Trace word map sorting

















 1569
1569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









