







 文章提出了一种名为LAND的新框架,利用知识图谱嵌入和多模态信息处理学术数据中的作者姓名消歧义问题。通过在两个新创建的数据集上进行实验,表明LAND在F1得分上优于基线方法,并在具有挑战性的基准上表现出竞争力。这种方法强调了结构信息和文字特征的结合,以提高消歧性能。
文章提出了一种名为LAND的新框架,利用知识图谱嵌入和多模态信息处理学术数据中的作者姓名消歧义问题。通过在两个新创建的数据集上进行实验,表明LAND在F1得分上优于基线方法,并在具有挑战性的基准上表现出竞争力。这种方法强调了结构信息和文字特征的结合,以提高消歧性能。
A knowledge graph embeddings based approach for author name disambiguation using literals - Scientometrics (2022)
摘要
学术数据不断增长,其中包含来自会议、期刊等众多场所的文章信息。已经采取了许多举措,以知识图(KGs)的形式提供学术数据。这些标准化这些数据并使其可访问的努力也带来了许多挑战,如学术文章的探索、模棱两可的作者等。
作者的方法:
这项研究更具体地针对学术KGs上的作者姓名消歧(AND)问题,并提出了一个新的框架,即字面作者姓名消歧义(LAND,Literally Author Name Disambiguation ),其利用知识图嵌入(KGE),该知识图嵌入使用从这些KGs生成的多模式文字信息。该框架基于三个组成部分:(1)多模态知识图谱嵌入(KGEs)(2)阻塞过程(3)分层聚合聚类。
实验结果:
对两个新创建的KG进行了广泛的实验:
(1)包含1978年以后《科学计量学杂志》(OC-782K)信息的KG,
(2)从AMiner提供的著名AND基准中提取的KG(AMiner-534K)。
结果表明,我们提出的架构在F1得分方面优于我们8-14%的基线,并在具有挑战性的基准(如AMiner)上显示出有竞争力的性能。
代码和数据集可通过Github(https://github.com/sntcristian/and-kge)和Zenodo(https://doi.org/10.5281/zenodo.6309855)获得。
1.介绍
学术知识图(SKG)中可用的数据——即“旨在积累和传达现实世界知识的数据图,其节点代表感兴趣的实体,其边缘代表这些实体之间潜在的不同关系”(Hogan等人,2021)——每天都在不断增长,导致了大量挑战,例如,Liu等人(2018)的文章探索与可视化,Beel等人(2016)的文章推荐,Faörber和Jatowt(2020)的引文推荐,以及作者姓名消歧(and)(调查见Sanyal等人(2021)),这与本文的目的相关。特别是,AND是指实体解析的特定任务,旨在解析书目引用中作者对现实世界人物的提及。
作者持久标识符,如ORCID和VIAF,简化了AND活动,因为这样的标识符可以用于协调被定义为不同对象并代表同一现实世界中的人的实体。然而,在开放引文(OC)(Peroni&Shotton,2020)、AMiner(Wan et al.,2019)和微软学术知识图谱(MAKG)(Faber,2019)等SKG中,此类持久标识符的可用性的特点是覆盖率非常低,因此,必须采用额外的面向计算的技术来将不同的作者识别为同一个人。
在过去,已经开发了许多方法,通过使用出版物元数据(例如,标题、摘要、关键词、地点、隶属关系等)来提取可以在消歧任务中使用的特征,来自动处理AND。这些方法差异很大,从监督学习方法到无监督学习,包括最近开发的基于深度神经网络的架构。然而,现有的SKG并没有提供有效和高效地重用这些方法所需的所有相关上下文信息,这些方法通常依赖于纯文本数据。——即现有方法的缺点:没有重视上下文信息,只依赖于纯文本数据
这一问题的表现是,只有少数书目数据库提供了对完整书目元数据的广泛访问,包括摘要、关键词和唯一标识的附属关系(例如ROR IDs1),而许多当前的AND方法都严重依赖于这些元数据。正如倡议4开放摘要(I4OA 2)等开放获取倡议的兴起所见证的那样,**许多机器学习方法用于文献计量学研究(包括AND)的文本元数据(如摘要)的可用性是有限的。——即数据集中的标题,摘要等信息可能不全。**例如,2020年6月,在非营利的内政部注册机构Crossref上,只有8%的期刊文章有摘要。Crossref公开提供大多数国际出版商的高质量元数据。当然,这是SKG提供所涉及的基础设施带来的挑战,例如OpenCitation,它通常从异构和公开可用的书目数据库中收集这些元数据。
与目前的许多方法相比,本研究的重点是对表示为链接数据或包含在学术知识图中的学术数据进行作者名消歧,考虑这些集合中可用的多模态信息,即由实体及其之间的关系组成的结构信息,以及以文字形式定义的与作者和出版物相关的文本或数值。为了考虑到有歧义/区别的特征,如摘要和关键字。 我们提出了一种新的方法,该方法对SKG中编码的结构信息进行建模,并利用潜在字面量传达的语义来细化结构表示。
解决这一任务的拟议框架被命名为字面作者姓名歧义消除(LAND),其重点是解决以下研究问题:
- 知识图谱嵌入技术是否可以有效地用于集群的下游任务,更具体地说,用于作者姓名消歧?
- 在现有的学术知识图谱中,以属性三元组形式出现的信息是否增强了上述作者姓名消歧的表示?——属性三元组信息是否有助于消歧?
本文的目标是提供一种从不需要任何标记训练数据的skg中提取实体特征的表示学习方法。为此,LAND使用包含文字信息的语义匹配模型,即LiteralE (Kristiadi et al., 2019)来提取与作者相关的特征,这些特征可以适应skg中元数据的稀疏性。LAND进一步使用KGEs以及分层凝聚聚类(HAC)和阻塞[关于调查,请参阅Backes(2018)],以便从直接从skg学习的密集表示中获得最终的作者簇。
2.相关工作
知识图嵌入和学术数据
最近很少有关于KGE的使用以及在学术关联数据上的应用的研究。在Mai等人(2018)中,提出了一个学术领域的实体检索系统,将来自文本嵌入的信息和从KG IOS Press LD Connect训练的结构嵌入相结合。在本文中,作者通过提取两个基准数据集来评估论文和实体(即作者、组织等)的低维表示的质量:(1)从Semantic Scholar收集的基准数据集,用于评估论文的语义相似性,(2)从DBLP提取的第二基准数据集,用于评估基于KGE的合著推荐。作者通过使用Doc2Vec提取用于表示论文内容的段落向量,并训练TransE(Bordes et al.,2013)来提取IOS LD Connect的SKG中实体的嵌入。为了建立实体检索模型,一个以段落向量和结构嵌入为输入特征的逻辑回归模型。它是在语义学者自动收集的类似论文数据集上训练的。报道的结果表明,无论单独的文本嵌入是否能获得稳健的结果,KGE对论文相似性分类都没有显著影响。作为第二步,通过使用从DBLP中提取的基准数据集来进行合著者推断评估,以证明TransE基于观察到的三元组预测合著者链接的能力。
在Nayyeri等人(2020)中,嵌入已被用于生成关于skg的合著推荐。这项工作的目的之一是提出一种新的方法,用于在1-to-N, N-to-1和N-to-N关系频繁的skg上训练KGE模型(即作者关系或引用链接)。为了解决这个问题,作者通过使用新提出的针对多对多关系优化的损失函数,即软边际(SM)损失,重新实现了TransE (Bordes et al., 2013)和RotatE (Sun et al., 2019)。他们的研究结果表明,配备了SM损失的模型优于原始模型。本研究的新颖之处在于提出了一个损失函数,以减轻假阴性抽样的不利影响,并调查了KGEs在合著建议中的使用。
Creation of the scholarly KGs(OC‑782K)
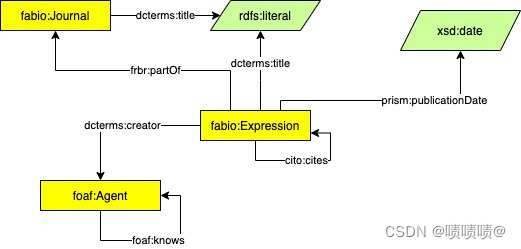
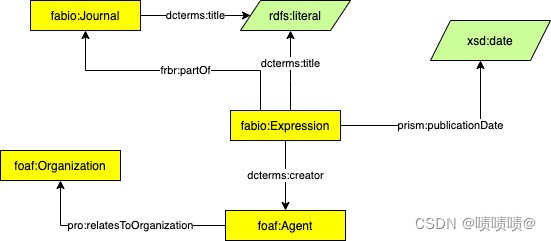
该数据模型(OC-782K数据集)包含三种类型的实体:
-
Fabio:Expression,表示文章、书籍、会议论文和其他学术作品;
-
Fabio:Journal,表示期刊场所(如果相关的Fabio:Expression是期刊文章);
-
foaf:Agent,表示作者;
OC-782K 是通过首先收集有关至少有标题和作者的书目资源的信息来从 Scientmetrics-OC 中提取的。然后,收集这些作品的出版日期和期刊场所(如果有的话)。
1.foaf:knows,在两个共同撰写了同一作品的作者之间添加了关系;
2.cito: quotes,两个书目资源之间的关系,一个引用表达式和一个被引用表达式,用cito: quotes关系表示。
Creation of the scholarly KGs(AMiner-534K)

3.方法论
在本节中,详细描述了所提出的框架的不同组成部分,即字面作者姓名消歧(LAND)。下图显示了该方法的总体架构,该架构基于三个主要组件:
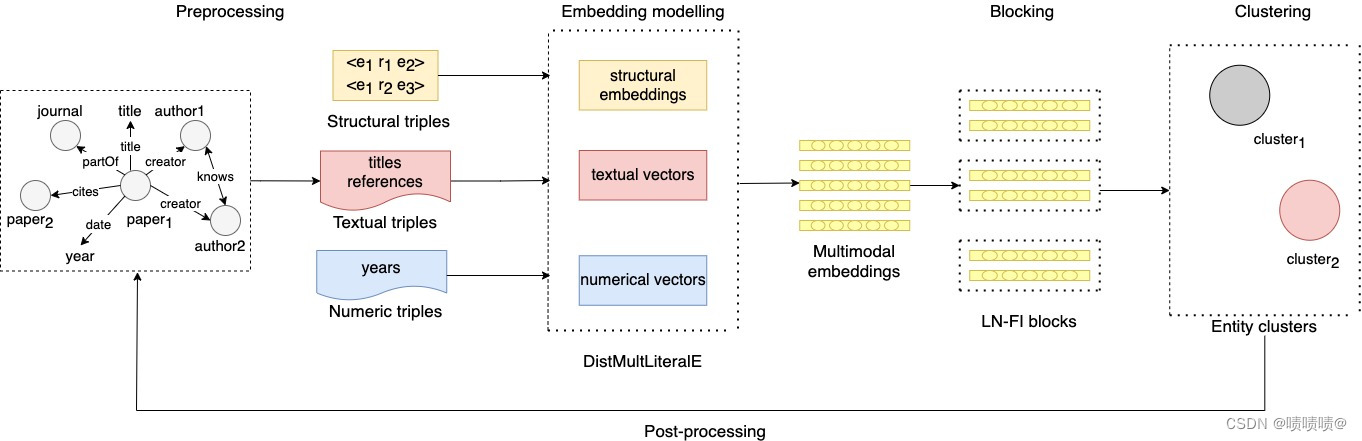
- Multimodal KG embeddings:该策略的目的是通过考虑图本身的结构以及关于这些实体的文字中包含的语义(例如,学术著作的标题或出版日期)来学习KG中实体和关系的代表性特征。
- Blocking:此策略用于减少AND任务所需的成对比较的数量,方法是最初将作者分组为以名称相似为特征的块,以便在每个块中进行歧义消除。LAND 使用一种相当简单但有效的阻塞策略,称为 LN-FI 阻塞。
- Clustering:分层凝聚聚类(HAC)用于通过使用基于向量的相似性度量(例如余弦)和距离阈值将与要消除歧义的每个作者相关联的嵌入分组到k-clusters中。
3.1 Multimodal KG embeddings
LAND框架的第一步是学习kg的潜在表征,包括作者的表征。为此,LAND的Multimodal KGEs组件旨在通过组合结构信息和与实体相关联的文字(如字符串或日期值)来学习实体和关系在KG中的嵌入。LAND在该组件中采用LiteralE(Kristiadi等人,2019年)嵌入模型来学习KGE。它通过使用可学习的映射函数将文字信息合并到实体表示中,其中文字信息可以是数字或文本。更具体地说,LiteralE是学习KGEs的语义匹配模型的多模态扩展,例如DistMult(Yang et al., 2015)。DistMult用一个简单的双线性变换 f ( h , r , t ) = h T diag ( r ) t f(h, r, t)=\mathbf{h}^{\mathrm{T}} \operatorname{diag}(\mathbf{r}) \mathbf{t} f(h,r,t)=hTdiag(r)t . 对KG中的每个三元组进行评分。然后在训练阶段学习这些表示,其目的是最大化KG中现有三元组的得分,并最小化不存在三元组(即负例)的得分。同时,LiteralE的目的是修改评分函数f,通过使用每个三重混合表示的头h和尾t实体来修改评分函数 f,该三重混合表示将来自实体关系的信息与来自其文字值(literal)的信息相结合。该方法的核心是映射函数 g : R h × R d → R h g: R^{h} \times R^{d} \rightarrow R^{h} g:Rh×Rd→Rh,将实体嵌入 e ∈ R h \mathbf{e} \in R^{h} e∈Rh和文字向量 I ∈ R d \mathbf{I} \in R^{d} I∈Rd作为输入,并将它们映射到与实体嵌入相同维数的新嵌入。
LAND使用SPECTER(Cohan等人,2020),这是一种用于科学文档的预先训练的Bert(Devlin等人,2019)语言模型,以便在将实体(例如出版物标题)合并到具有g函数的实体向量之前对向量空间 R d R^{d} Rd中的实体的文本属性进行编码。
通过使用该模型,我们将学术KG中的每个标题映射到一个768维的句子嵌入。同时,如LiteralE中所述,数字数据类型(如xsd:gYear)被转换为文本向量。
在本研究中,使用了以下两种类型的DistMultLiteralE模型,并将其与相应的基础(unimodal)模型DistMult进行了比较。
-
L A N D − g l i n \mathbf{LAND-g_{lin}} LAND−glin:该体系结构通过定义如下的线性转换,将从实体(学术文章)的标题中提取的文本嵌入合并到它们的表示中:
g l i n ( e , l ) = W ( e , l ) \mathbf{g_{lin}(e,l)} = W(e,l) glin(e,l)=W(e,l)
其中 e ∈ R h \mathbf{e} \in R^{h} e∈Rh是与KG中第i个实体相关联的向量,是标题嵌入, w ∈ R ( h , d + h ) \mathbf{w} \in R^{(h,d+h)} w∈R(h,d+h)是一个线性变换矩阵, [ e , l ] ∈ R ( h + d ) \mathbf{[e, l]} \in R^{(h+d)} [e,l]∈R(h+d)是实体嵌入e和文字嵌入l的拼接向量。通过该操作,实体向量与SPECTER编码的文本向量结合成与原始实体表示e具有相同维数的多模态表示。 -
L A N D − g g r u \mathbf{LAND-g_{gru}} LAND−ggru:这里的目标是同时利用文本(标题)和数字文字(出版日期)。该体系结构通过门控循环单元(Gated Recurrent Unit,GRU)将来自数字和文本文字的信息组合到实体表示中,定义如下:

其中*是逐元素乘法,𝜎(⋅) 是 sigmoid 函数, W z e ∈ R ( h , h ) \mathbf{W_ze} \in R^{(h,h)} Wze∈R(h,h), W z l ∈ R ( h , h + d ) \mathbf{W_zl} \in R^{(h,h+d)} Wzl∈R(h,h+d), W z n ∈ R h \mathbf{W_zn} \in R^{h} Wzn∈Rh, W h ∈ R ( h , h + d + 1 ) \mathbf{W_h} \in R^{(h,h+d+1)} Wh∈R(h,h+d+1)是线性变换矩阵,b 是偏置向量,h(⋅)是分量非线性(例如双曲正切),[e,l,n]是实体向量、文本向量和数字文字值的串联。通过此操作,实体向量与文本向量和与发布日期相关的数字文字组合成一个原始实体向量 e 相同维度的多模态表示。
最后,在每个模型在给定KG上训练之后,每个作者A的嵌入E通过将其与与作者A相关联的文档D(即学术文章)的嵌入D串联来修改,以获得特征F,其中 F = E + D F=E+D F=E+D。这是为了在作者的嵌入中反映两个实体(作者和文档)的结构信息和文档属性中存在的文字信息(即标题和出版日期)。
3.2 Blocking
阻塞是AND系统中广泛使用的一种策略。其思想是将与作者相关的特征集F分割为单独的组,也称为块,用 F b 1 , F b 2 , . . . . . . F b n F_{b_1},F_{b_2}, ...... F_{bn} Fb1,Fb2,......Fbn表示,每个都与一个模糊的名称相关联,因此,AND是在这些块内独立执行的。 LAND使用常见的LN-FI块,通过查看每个作者的全名和名字的首字母,将作者特征集划分为块。之所以选择这种阻塞技术,是因为它比其他基于距离度量或字符串规范化的阻塞方法计算成本更低,而且它还符合出版商经常在出版物的元数据中提到作者名称的方式。
3.3 Clustering
LAND中的聚类算法帮助将每个块FB中的作者特征分组到k-簇{ C 1 , . . . , C k {C_1,...,C_k} C1,...,Ck}中,其中所有特征都在 C j C_j Cj中,其中j=1,…,k,理想情况下,属于同一真实世界的作者。
使用HAC(Ward,1963),它以自下而上的方式构建特征集群。该方法将块中的每个嵌入作为一个单独的簇,并通过迭代合并两个最相似的簇来工作,直到所有特征都被合并到一个最终簇中。
尽管On等人已经研究过HAC存在可伸缩性问题,我们依旧决定采用这种聚类方法,主要有两个原因:(1)简单;(2)它是图嵌入方法解决作者名称消歧问题(见第2.1节)使用的最常见的聚类方法,并使我们能够将LAND与在AMiner基准上测试的其他方法进行比较,如Zhang和Al Hasan(2017),Zhang等人.。
在我们的HAC实现中,簇之间的相似度是通过一种单一的链接策略来计算的,在每一步,该策略基于余弦相似度来合并距离最近的两个成员的簇。为了得到最终的簇,定义了一个关于最大距离的阈值,超过这个阈值的簇被认为对应于不同的作者。通过在评估块上测试不同的值,在所有块上全局定义阈值,更多细节在第5.3节中提供。
4.实验
本节讨论 LAND 框架的实证评估。它首先展示了如何为 AND 的任务生成基本事实,然后它展示了 LAND 在新生成的数据集 OC-782K 和从广泛使用的 AND 基准中提取的 KG 上的实验结果,即 AMiner-534K(更多细节参见第 3 节)。此外,对 OC-782K 的结果进行了错误分析。
4.1 生成ground truth数据集
为了获得在 OC-782K 上测试 LAND 的基本事实,提取了(作者、ORCIDiD)对列表。这样做是为了有一个学术文章的评估数据集,该数据集标有与其现实世界作者相关的唯一标识符。为了处理数据集中的不平衡,只考虑姓氏和第一个初始与至少两个不同的 ORCID iD 相关联的作者。最终评估数据集包含 630 个书目工作,分为 184 个块和 497 个不同的 ORCID iD。该地面实况中最大块的大小报告在表 6 中。
为了衡量所提出方法的普遍性,使用了另一个手动标记的基准数据集,即 AMiner-534K。该评估数据集大于为 OC-782K 提取的数据集,有 35,023 篇学术文章和 6,395 位独特作者。与之前的数据集一样,每个歧义名称都被视为一个块,并在每个块内执行消歧。该评估数据集包含 35,129 条记录,分为 100 个模棱两可的亚洲名称。在这个数据集中,消歧是针对每个歧义名称独立执行的。该地面实况中最大块的大小报告在表 7 中。
4.2 实验设置
实验环境
多模态KGE模型的实现与PyKEEN (v1.4.0)(Ali等人,2021)兼容。
如前所述,不同变体的源代码可以在https://github.com/sntcristian/and-kge链接上找到。
KGE模型使用Colab Pro笔记本进行训练和评估,使用约为24GB的RAM和Nvidia Tesla T4/K80 GPU。
实验评估的模型
LAND 的性能基于 KGE 模型的三个变体进行评估:LAND、LAND-glin 和 LAND-gru。
- 第一个变体由一个unimodal KGE 模型组成,即仅考虑 KG 中实体之间的结构关系的 DistMult,不考虑文字(例如,文本或发布日期)。
- 第二个变体 L A N D − g l i n \mathbf{LAND-g_{lin}} LAND−glin通过学习线性变换的参数将论文的标题合并到 DistMult 建模的嵌入中。
- 第三个变体 L A N D − g g r u \mathbf{LAND-g_{gru}} LAND−ggru使用节点的数字属性(例如,发布日期)和标题,并使用 GRU 函数 ( Cho 等人,2014)将它们合并到实体表示中。
实验结果评估方法
这些实验涉及两个主要任务:
- 对 LAND 的评估与与 OC-782K 中的 ORCID iD 相关的候选集
- AMiner 在 Zhang 等人(2018年)提供的基准数据集上对 LAND 的泛化分析。 其中 LAND 与 Sect. 2. 调查的 SOTA 模型进行比较。
受 Zhang 等人(2018年)的启发,使用了 p a i r w i s e P r e c i s i o n , R e c a l l , F 1 pairwise Precision,Recall,F1 pairwisePrecision,Recall,F1。为了研究 LAND 的普遍性,这些指标在所有 100 个测试名称中都是宏观平均的。
此外,我们必须指出,由于其他图嵌入模型使用了更多的特征,因此泛化性研究是不公平的,因为AMiner-534K不包括摘要和关键字。我们希望在提取的KG上测试我们的模型,并将结果与在更大的基准上获得的结果进行比较的原因是为了测试这样一个假设,即我们的体系结构即使在更具有挑战性的基准上(作者数量相应更高)也能保持具有竞争力的性能。
模型选择与阈值分析
这些模型使用二元交叉熵 (BCE) 损失函数、Adam 优化器、随机局部封闭世界假设 (SLCWA) 训练方法和标签平滑作为正则化技术进行训练。
请注意,对于训练,每个 KG 以 64% 的训练、16% 的验证和 20% 的测试的比例拆分。使用随机搜索在表8中给出的值范围内执行超参数优化。每个模型都训练了最多 1000 个 epoch,并应用提前停止来加速优化过程并避免过度拟合。

注意到由于资源的限制,我们只在两个数据集上对unimodel模型(即,DistMult)进行了优化研究,并选择了给出最好结果的最佳超参数值集,然后决定也将它们应用于训练多模模型。
最佳超参数如下:
OC-782K:
embedding dimension: 512,
learning rate: 0.0003,
number of negatives: 12,
batch size: 512,
smoothing coefficient: 0.001,
epochs: 120;
AMiner-534K:
embedding dimension: 128,
learning rate: 0.0001,
number of negatives: 32,
batch size: 512,
smoothing coefficient: 0.1,
epochs: 300.
对于HAC,我们通过实验定义了最终聚类的距离阈值,试图通过找到给出最佳F1分数的阈值来在精确度和召回率之间找到一个折衷。然而,由于高召回率系统倾向于将不同的作者组合在一起,这对AND的性能产生了负面影响,我们决定更倾向于高准确率而不是召回率。
对于OC-782K,得到的最佳阈值是0.6,而对于AMiner-534K,它是0.26。
4.3 对比方法
为了更好地评估LAND框架的性能,实施了两种基线方法:
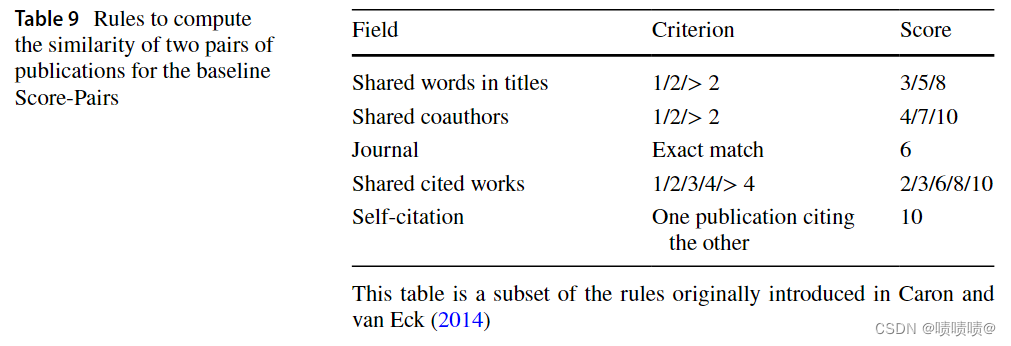
- 最初在Caron和van Eck(2014)中提出的基于规则的方法,根据几个规则为两个出版物分配成对的相似度得分;
- 基于从标题中提取的句子嵌入的分块和聚类的简单消歧算法。
我们选择受Caron和van Eck(2014年)启发的基于规则的方法,在此称为分数对,主要有三个原因:(I)它的简单性和可扩展性;(Ii)它最近在Färber和ao(2022年)的SKG上有效使用;iii)因为它在GitHub8上有一个开放的实现。此外,第2节调查的其他方法在可重复性方面存在问题,因为它们中的大多数没有开放源码的实现,其中一些受到监督,或者它们依赖于许多需要针对OC-782k进行调整的隐藏参数
Score-Pairs 通过查看几个特征(例如,标题中的共享词、合著者、引文等)来对两个出版物是否属于同一作者进行分类并基于标准列表计算这些特征中的每一个的亲和度分数,所述标准列表即,精确串匹配或同现次数。表9列出了比较的功能列表,以及各自的比较标准和分数。然后,选择亲和度分数(affinity scores)总和的阈值,以确定给定其属性的相似性的出版物是否属于同一作者。在我们的实验中,阈值的值是10。
选择第二个基线标题相似度(Title-Similarity)来估计文本嵌入对于AND任务的代表性。该基线对Cohan等人(2020)提出的SPIRTER语言模型编码的标题嵌入执行HAC。可以被视为我们的架构的一个变体,它只使用标题嵌入。报告这一基线的结果是为了测试使用KG的结构信息对文本信息的影响;在标题的情况下,文本信息可能不会有太多歧视。
实现了标题相似度的聚类算法:以单链接为链接方式,以余弦相似度为亲和度(affinity),阈值为0.18。对于使用KGE的体系结构,集群的阈值是通过最大化F1分数来选择的,同时更看重精确度而不是召回率。
在概括性研究中,我们的体系结构与在AMiner基准上测试的几个基线(Zhang等人,2018年)进行了比较,包括基于图的模型(Fan等人,2011)、监督学习模型(Louppe等人,2016)和图嵌入模型(Zhang&Al Hasan,2017;Zhang等人,2018;Wang等人,2020;Pooja等人,2021;Chen等人,2021)。这些模式中的每一种都在第2节的各个小节中提供了说明。
4.4 结果
OC-782K的性能评价
本节将在OC-782k上的不同LAND变体,即 D i s t M u l t + H A C DistMult+HAC DistMult+HAC, D i s t M u l t L i t e r a l E − g l i n + H A C DistMultLiteralE-g_{lin}+HAC DistMultLiteralE−glin+HAC, D i s t M u l t L i t e r a l E − g g r u + H A C DistMultLiteralE-g_{gru}+HAC DistMultLiteralE−ggru+HAC与前面描述的两个基线模型的结果进行比较。
表10显示了实验结果。除了
L
A
N
D
−
g
g
r
u
LAND-g_{gru}
LAND−ggru的精度外,基于嵌入的模型的性能优于两种基线方法。更准确地说,表现最好的LAND的成对F1分数有一个增量,即分别比基线分数对和标题相似度增加了14%和8%。LAND的精度最高,为91.71,F1评分最高,为77.50。最好的召回率是
L
A
N
D
−
g
g
r
u
LAND-g_{gru}
LAND−ggru获得的67.59。然而,与LADN相比,召回的差异微乎其微。
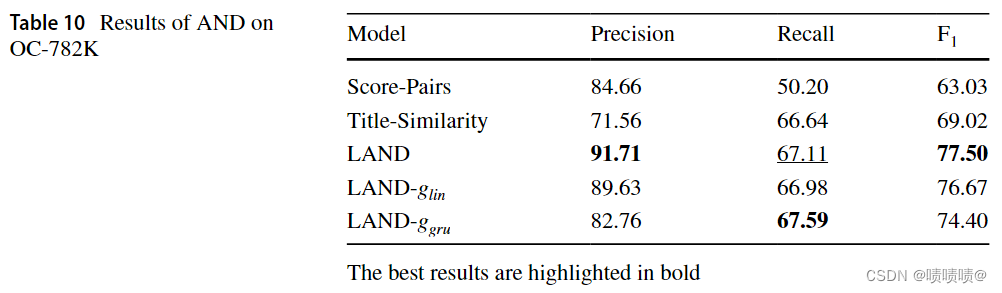
对基线得分对(Score-Pairs)的改进表明,与基于规则的方法相比,KGE嵌入能够建模非常有区别性的表示(Caron&Vaneck,2014;Farber&ao,2022)。事实上,在给定相同数量的信息,即标题、合著者、引文、地点和出版日期的情况下,通过获得更有效的特征来聚类的事实,补偿了使用需要对未标记数据进行培训的表示学习体系的成本。
此外,与我们的LAND变量相比,标题相似度的低精度表明了考虑来自KG的整个信息是多么有益,与我们最精确的模型相比,精度增加了28.16%。
于多模态模型 L A N D − g g r u LAND-g_{gru} LAND−ggru和 L A N D − g l i n LAND-g_{lin} LAND−glin,结果中没有改进是令人惊讶的,它们表明,对于属于一个特定领域(即科学计量学)的数据集,文字信息并没有为嵌入添加太多信息,而是引入了一些噪声。
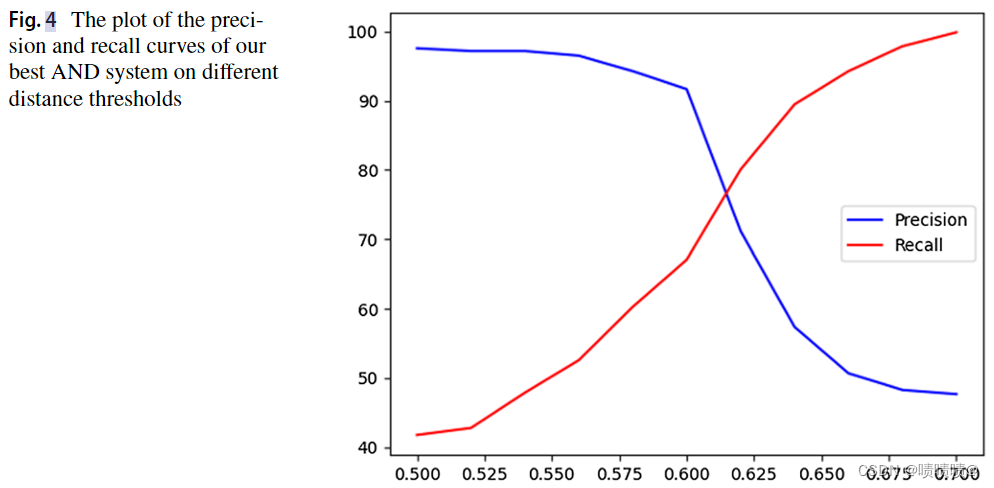
从表11中可以看出,LAND在召回率方面的表现远远不是最优的,因为我们的模型忽略了评估数据集中相关数量的匹配作者(>平均30%)。然而,我们决定避免更高的阈值,以减少我们的聚类算法产生的假阳性数量,从而避免将不同人写的论文归因于同一作者。OC-782K的精密度和召回率曲线如图4所示。

通过将LAND应用于OC-782K中具有高精度设置的整个作者集,我们能够将作者实体从188,565减少到135,325(减少超过28%)。这说明了kge如何与skg上的AND相关,以及它们如何有效地删除重复项。
AMiner数据集的性能评价
我们在从AMiner基准数据集中提取的新收集的KG上测试了我们方法的泛化能力(Zhang等人,2018年)。LAND的结果与基准研究(Zhang等人,2018)中报告的SOTA和模型的性能进行了比较,并与在AMiner基准上测试的其他图嵌入模型进行了比较(表1提供了对这些模型的描述)。然而,我们指出,这种比较并不完全公平,因为AMiner-534K中缺乏某些信息,例如摘要和关键字。
L A N D − g l i n LAND-g_{lin} LAND−glin的性能优于其他不使用嵌入方法的SOTA模型,如Fan等人(2011)和Louppe等人(2016)。这表明,即使我们不使用摘要和关键字,使用知识图嵌入来编码来自关联数据的结构信息也比监督方法或预定义的启发式方法更有效。此外,有趣的是看到 L A N D − g l i n LAND-g_{lin} LAND−glin的表现也优于(Zhang&Al Hasan,2017),这是一种基于合著信息的图形嵌入方法,表明我们的体系结构的优势,它还模拟了出版物和场所之间的关系,以及作者和从属关系之间的关系。
然而,作为负面的结果,我们看到我们的方法的性能优于其他图嵌入技术,如Zhang et al. (2018), Chen et al. (2021), Pooja et al. (2021) and Wang et al. (2020)在F1方面。尽管如此,在图嵌入模型中,我们没有使用文字的LAND 获得了第二好的精度分数,而召回率却大大低于其他模型。然而,该模型的召回率较低是由我们的 LAND 架构是在不包含摘要和关键字信息的 KG 上训练的这一事实来解释的。
此外,我们声称,与Zhang et al. (2018), Chen et al. (2021), Pooja et al. (2021) and Wang et al. (2020) 的架构相比,我们的模型的相对较低的性能被我们的体系结构的以下优势所平衡:
- Zhang 等人提出的方法。)要求在训练过程中使用人工注释数据,以便从数据集中学习基于结构的特征。取而代之的是,我们的LAND学习SKG的区别性特征,而不需要人类的监督。
- Zhang et al. (2018), Pooja et al. (2021) and Chen et al. (2021) 利用复杂的要素工程方法,从书目元数据创建学术网络。这些特征工程方法包括通过Doc2Vec进行文档编码、文档相似度估计和合著者相似度估计,以便从目录元数据创建内容或合著者关系图。这一过程不仅耗时,而且需要为每个数据集调整许多参数,这阻碍了他们方法的重复性。相反,我们的方法不需要特征工程,直接从KG中显式表达的关系学习节点嵌入。
- Wang et al. (2020)是与我们的架构最相似的架构。该模型惊人的性能表明了使用GANS将内容信息整合到来自异构图的关系信息中的优势。然而,该体系结构使用了两个不同的模块,一个区分模块和一个生成模块,以对抗的方式改进节点嵌入。此外,由于缺乏可用的源代码,这种复杂的体系结构很难重用。相反,我们的模型只在一个模型中整合了内容信息和关系信息,即DistMultLiteralE(Kristiadi等人,2019年),我们提供了一个开源实现。
误差分析
我们从消除歧义的OC-782k中随机抽样了50个错误匹配对(即假阳性)的子集,以分析我们的和系统产生的最频繁的错误。我们发现,大多数错误的配对都与亚洲作家有常见的姓氏和首字母有关,如“Chen B”、“Kim S”、“Li Y”、“Wang J”、“Li J”、“Hu Z”和“Chen J”。这可能是因为LN-FI屏蔽往往会为非常频繁的姓氏创建巨大的区块,这会导致错误的作者滑入最终的集群,特别是当他们共享一些特征时(如references or publishing venue)。然而,我们发现,在合并两个作者之前,可以通过使用后阻塞策略来消除所有这些错误,该策略提出了 fullname i = fullname j 的条件。事实上,我们发现,在我们的样本中,所有错误匹配的具有相同全名的对都是同一个人,由于他们在不同的学术著作中使用了多个ORCID这一事实,他们的实体被错误地标记。然而,这一后阻塞策略没有包括在我们的框架中,因为只对少数假阳性进行了测试,而且它仅限于提供每个作者参考文献的至少一个姓氏和一个全名,情况并不总是如此,特别是对于旧的出版物。
5 总结
本文介绍了一个名为LAND的框架,通过基于实体之间的关系和与其相关的文字信息建立KGE模型,对表示为关联数据或包含在SKG中的学术数据执行作者姓名消歧(AND)。我们已经证明,这些模型可以有效地用于下游的聚类任务。在定义了符合开放引用数据模型(OCDM)的SKG(名为OC-782K)的新创建的基准数据集以及使用现有基准数据集(即AMiner)创建的另一个SKG(名为AMiner-534K)上,该框架的性能优于现有的基准数据集。我们的方法即使在处理更复杂的模型时也能够保持具有竞争力的精确度、召回率和F1水平。此外,LAND被设计用于处理知识图中的数据。
在未来,我们计划将我们的方法扩展到包括作者合作网络信息以及通过深度学习方法处理作者的出版物而提取的感兴趣的主题/专业领域。拥有这样的额外数据将使我们能够测试它们是否可以改善作者姓名歧义消除任务的结果。
部分参考文献
Mai,G., Janowicz,K.,& Yan, B.(2018).Combining text embedding and knowledge graph embedding techniques for academic search engines.
注意:博客中的我们指的是这篇论文的原作者
网址:https://link.springer.com/article/10.1007/s11192-022-04426-2
这里是这篇论文引用格式:Santini, C., Gesese, G.A., Peroni, S. et al. A knowledge graph embeddings based approach for author name disambiguation using literals. Scientometrics 127, 4887–4912 (2022). https://doi.org/10.1007/s11192-022-04426-2


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









