






# -*- coding: utf-8 -*-
# @Time : 2023-5-12 14:15
# @Author : shenzh
# @FileName: chat_bot_v1.py
# @Software: PyCharm
"""
Description:一期智能机器人设计完成,支持自定义问题和答案随时增加功能
"""
import json
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
import pysparnn.cluster_index as ci
import pickle
import pandas as pd
def increase_other_qa(txt_path):
dict_list = []
txt_qa = pd.read_csv(txt_path)
ques_list = txt_qa['question']
answer_list = txt_qa['answer']
for index in range(len(ques_list)):
txt_dict = {}
txt_dict['q'] = ques_list[index]
txt_dict['a'] = answer_list[index]
dict_list.append(txt_dict)
return dict_list
def get_tfidf_index(qa_path, txt_path, tv_path, cp_path):
# 数据保存路径
qa = json.load(open(qa_path, encoding='utf-8'))
dict_list = increase_other_qa(txt_path)
for dict_res in dict_list:
json_str = dict(dict_res)
# print(json_str)
qa.append(json_str)
corpus = []
for id, item in enumerate(qa):
tmp = item['q'] + item['a']
# print(tmp)
tmp = jieba.cut(tmp)
tmp = ' '.join(tmp)
corpus.append(tmp)
# print(corpus)
# Generate bag of word
# TfidfVectorizer is a combination of CountVectorizer and TfidfTransformer
# Here we use TfidfVectorizer
tv = TfidfVectorizer()
# deal with corpus
tv.fit(corpus)
# get all words
# 词典
tv.get_feature_names()
# get feature
# 获取每对 QA 的TF-IDF
tfidf = tv.transform(corpus)
# build index
# 创建索引
cp = ci.MultiClusterIndex(tfidf, range(len(corpus)))
# save
pickle.dump(tv, open(tv_path, 'wb'))
pickle.dump(cp, open(cp_path, 'wb'))
return qa, tv_path, cp_path
def predict_ans(question, qa, tv_path, cp_path, answer_num, distance_flag):
# 分词
cutted_qustion = jieba.cut(question)
cutted_qustion = ' '.join(cutted_qustion)
# retrieve qa, tv and cp built in gen.pysparnn
# 加载之前保存的数据
# qa = json.load(open(qa_path))
tv = pickle.load(open(tv_path, 'rb'))
cp = pickle.load(open(cp_path, 'rb'))
# construct search data
# 构造搜索数据
search_data = [cutted_qustion]
search_tfidf = tv.transform(search_data)
# search from cp, k is the number of matched qa that you need
# 搜索数据,会获取到前 k 个匹配的 QA
result_array = cp.search(search_tfidf, k=int(answer_num), k_clusters=2, return_distance=distance_flag)
# print(result_array)
result = result_array[0]
# print(result)
# print("Top matched QA:")
# print('====================='
'''
[{
"que": "空气净化器pro噪音大吗",
"ans": "您好,可以开启睡眠模式,几乎没有噪音",
"sim_value": 1
}]
'''
faq_list = []
if distance_flag:
for distance_value, id in result:
faq_dict = {}
distance_value2 = 1 - round(distance_value, 2)
# print('ORI_Q:' + question)
# print('Q:' + qa[int(id)]['q'])
# print('A:' + qa[int(id)]['a'])
# print('DV:' + str(distance_value2))
# print('=====================')
faq_dict['que'] = qa[int(id)]['q']
faq_dict['ans'] = qa[int(id)]['a']
faq_dict['sim_value'] = str(distance_value2)
faq_list.append(faq_dict)
else:
for id in result:
faq_dict = {}
# print('ORI_Q:' + question)
# print('Q:' + qa[int(id)]['q'])
# print('A:' + qa[int(id)]['a'])
# print('=====================')
faq_dict['que'] = qa[int(id)]['q']
faq_dict['ans'] = qa[int(id)]['a']
faq_dict['sim_value'] = ""
faq_list.append(faq_dict)
return faq_list
if __name__ == '__main__':
qa_path = '../data/qa.json' ##通用型的问题和答案
txt_path = '../data/qa_.csv' ##外加指定的问题和答案
tv_path = '../data/tv.pkl'
cp_path = '../data/cp.pkl'
qa, tv_path, cp_path = get_tfidf_index(qa_path, txt_path, tv_path, cp_path)
question = '需要配备电源插座吗?' ##问题
answer_num = 2 ##返回推荐结果的个数
distance_flag = True ##结果的相似度的值
predict_ans(question, qa, tv_path, cp_path, answer_num, distance_flag)
qa.json样例数据
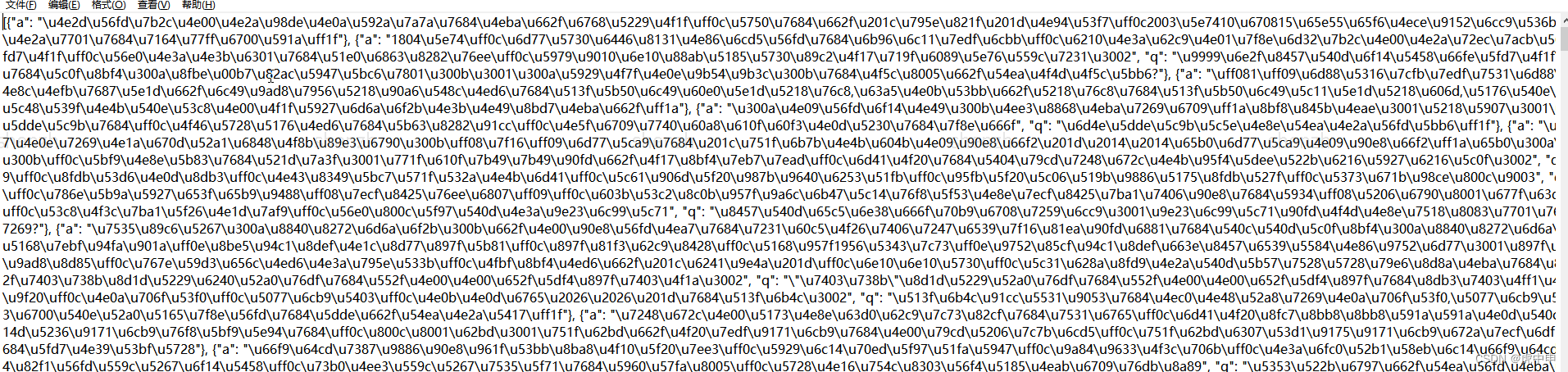
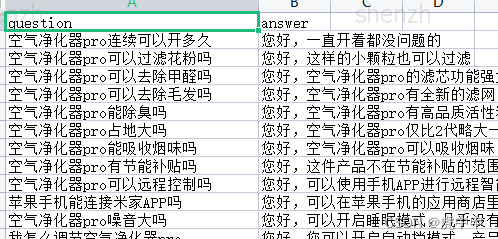
qa_.csv














 5413
5413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









