






一、Kubernetes 介绍
Kubernetes(简称 K8s)是一个开源的容器编排平台,用于自动化部署、扩展和管理容器化应用。它由 Google 设计并开源,现由云原生计算基金会(CNCF)维护,已成为容器编排领域的事实标准。Kubernetes 旨在解决大规模容器化应用程序的复杂性问题,提供高效、灵活和可靠的运行环境。
1. Kubernetes 的核心目标
-
自动化运维:自动部署、扩缩容、故障恢复。
-
资源高效利用:优化计算、存储和网络资源。
-
跨环境一致性:支持混合云、多云和本地数据中心的无缝迁移。
-
声明式配置:通过 YAML/JSON 文件定义应用状态,系统自动实现目标状态。
https://zhuanlan.zhihu.com/p/46341911
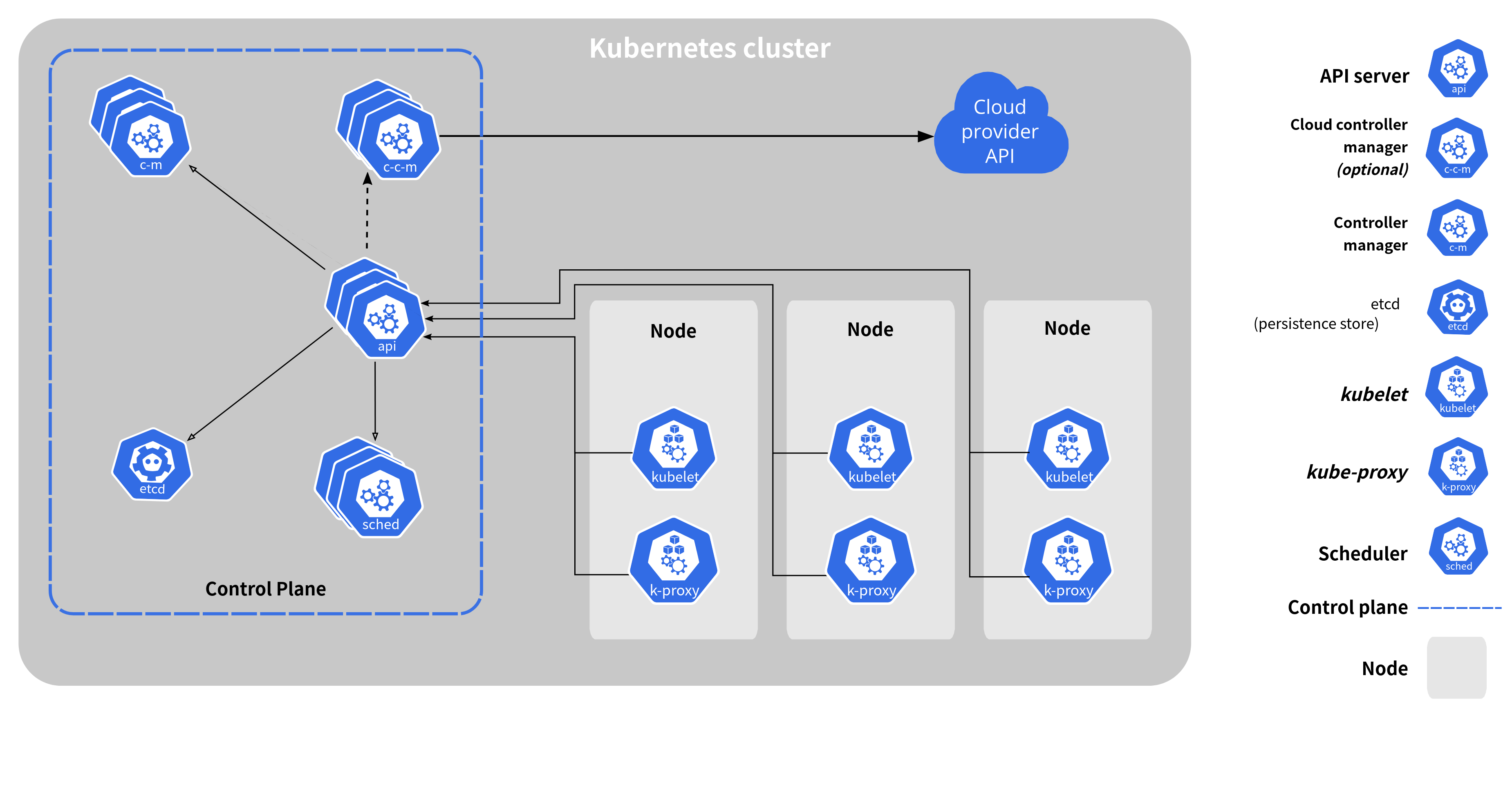
2. Kubernetes 架构
控制平面是逻辑上的管理核心,而主节点是控制平面的物理载体。
控制平面(Control Plane)的定义与功能
控制平面是逻辑概念:作为Kubernetes集群的“大脑”,负责全局管理和调度,包括资源分配、状态维护、故障恢复等核心功能。它由以下核心组件组成:
- API Server
- 作为控制平面的前端,提供REST API接口,供用户、工作节点及其他组件与集群交互。
- 处理所有资源操作(如Pod、Service、Deployment的增删改查)。
- etcd
- 分布式键值存储,保存集群所有配置和状态信息(如Pod定义、节点状态)。
- 通过Raft算法确保数据一致性和高可用性。
- Scheduler
- 负责将Pod调度到合适的工作节点,基于资源可用性、约束条件(如节点标签、亲和性规则)进行决策。
- Controller Manager
Controller Manager是Kubernetes控制平面的后台进程,内置多个控制器(Controller),每个控制器专注于一种资源类型的状态管理。其核心职责包括:
- 状态监控:持续观察集群资源(如Pod、Node、Service)的实际状态。
- 状态修复:当实际状态偏离期望值时,自动触发修复操作(如重启Pod、迁移节点)。
- 自动化编排:实现声明式API的核心逻辑,用户只需定义目标状态,Controller Manager负责实现并保持。
主节点(Master Node)的组成与角色
主节点是控制平面的物理或虚拟载体,其核心组件与控制平面完全一致:
- 控制平面组件:主节点必须运行API Server、etcd、Scheduler、Controller Manager。
- 高可用扩展:在生产环境中,主节点可能部署多个控制平面实例(如多API Server副本)以实现高可用。
- 其他辅助组件:如云控制器管理器(与云服务商集成,管理负载均衡器、存储等资源)。
控制平面与主节点的关系
- 控制平面运行在主节点上:控制平面的所有组件均部署在主节点,主节点是控制平面的物理基础。
- 主节点可能包含其他组件:例如,在高可用架构中,主节点可能部署负载均衡器或额外的etcd实例,但这些仍属于控制平面的扩展部分。
- 逻辑与物理的区分:控制平面是逻辑概念,描述管理集群的功能集合;主节点是物理或虚拟节点,承载控制平面的具体实现。
Worker是逻辑上的工作节点角色,而Worker Node(工作节点)是Worker的物理或虚拟载体。
Worker的定义与功能
逻辑角色:Worker是Kubernetes集群中的从节点(Slave),负责执行控制平面(Control Plane)的指令,运行容器化应用。
- 核心职责:
- 运行容器:提供计算资源和环境,支持容器化应用程序的运行和扩展。
- 接收指令:与控制平面通信,接收并执行调度、管理、监控等指令。
- 资源隔离:通过资源限制和隔离机制,确保应用程序之间的资源不会相互干扰。
- 弹性扩展:根据负载需求动态调整Worker节点的数量,实现集群的弹性扩展。
Worker Node的组成与角色
- 物理/虚拟载体:Worker Node是Worker的具体实现,可以是物理机、虚拟机或云实例。
- 核心组件:
- kubelet:
- 角色:节点代理,负责管理Pod的生命周期和健康状态。
- 功能:
- 注册节点到API Server,定期发送心跳信息。
- 监控Pod状态,确保Pod达到期望状态(如启动、重启、终止容器)。
- 上报节点和Pod状态信息给控制平面。
- kube-proxy:
- 角色:网络代理,负责维护节点上的网络规则。
- 功能:
- 实现Service的负载均衡,将流量转发到后端Pod。
- 动态更新网络规则,响应Service和Endpoints的变更。
- 容器运行时(如Docker、containerd):
- 角色:负责容器的实际运行。
- 功能:
- 拉取镜像、创建容器、启动和停止容器。
- 与kubelet交互,执行容器生命周期管理操作。
Worker与Worker Node的关系
- 逻辑与物理的区分:
- Worker:逻辑概念,描述从节点的角色,强调其执行控制平面指令、运行容器化应用的职责。
- Worker Node:物理或虚拟节点,承载Worker的具体实现,运行kubelet、kube-proxy和容器运行时等组件。
Worker Node的工作流程
- kubelet:
- 注册节点:启动后向API Server注册当前节点,定期发送心跳信息。
- 管理Pod生命周期:根据API Server下发的Pod配置,启动、监控、重启或终止容器。
- 监控资源使用:通过内嵌工具(如cAdvisor)收集节点和容器的资源使用情况。
- 上报状态信息:定期向API Server上报节点和Pod的状态信息。
- kube-proxy:
- 监听变更:实时监听API Server中Service和Endpoints的变更。
- 动态更新规则:根据变更信息,生成或更新iptables/ipvs规则,确保流量路由的准确性。
- 流量转发:将到达Service IP的流量转发到后端Pod,实现负载均衡。
- 容器运行时:
- 拉取镜像:根据kubelet的指令,从镜像仓库下载应用所需的镜像。
- 创建容器:基于镜像创建容器实例,并根据配置启动容器。
- 管理容器生命周期:监控容器的运行状态,执行启动、停止、删除等操作。
Worker Node的重要性
- 提供计算资源:支持容器化应用程序的运行和扩展,是集群的工作负载执行单元。
- 执行控制平面指令:确保集群状态与期望状态一致,实现自动化的管理和调度。
- 实现弹性扩展:通过增加或减少Worker Node的数量,可以根据负载需求动态调整集群的容量。
| 组件 | 角色 | 核心功能 |
|---|---|---|
| 控制平面(主节点) | 管理者 | - API Server:处理集群内外的通信请求。 - etcd:存储集群配置和状态。 - Scheduler:调度Pod到工作节点。 - Controller Manager:维护集群状态和资源。 |
| 工作节点(从节点) | 执行者 | - kubelet:接收并执行主节点的任务(如创建Pod)。 - kube-proxy:处理网络代理和负载均衡。 - 容器运行时:实际运行容器。 |
3. Kubernetes 核心概念
容器(Container)
容器是一种轻量级、可移植的软件运行环境,能够将应用程序及其依赖打包在一起,确保在不同环境中的一致性运行。
容器是承载应用的核心单元,其设计和运行方式深度整合了 k8s 的编排能力。
k8s 不直接管理单个容器,而是将容器封装在 Pod 中。Pod 是 k8s 的最小调度单位,可包含 1 个或多个紧密协作的容器(如主容器 + 日志收集侧容器)。
同一 Pod 内的容器共享网络命名空间(IP/端口)、存储卷(Volume)和进程命名空间,便于高效通信。
容器技术(如 Docker)是 Kubernetes 的基础。
Namespace
Namespace 是 Kubernetes 中用于将集群资源划分为多个虚拟组的机制。每个 Namespace 可以包含独立的资源(如 Pod、Service、Deployment 等),实现逻辑隔离。这种隔离确保了不同团队、项目或环境的资源在命名和使用上的独立性。
- 资源隔离:Namespace 将集群资源(如 Pod、Service、Deployment 等)划分为逻辑组,实现不同团队、项目或环境的资源隔离。
- 命名唯一性:同一 Namespace 内的资源名称必须唯一,但不同 Namespace 可以使用相同的资源名称。
- 权限控制:通过 RBAC(基于角色的访问控制),可以限制用户或组对特定 Namespace 的访问权限。
机制 Namespace Cgroup 物理集群 功能 逻辑隔离(资源、权限) 资源限制(CPU、内存) 完全物理隔离 隔离级别 逻辑分组 进程级资源限制 物理硬件隔离 使用场景 多租户、多环境 容器资源限制 强隔离需求(如安全合规) 成本 低(共享集群资源) 低(共享节点资源) 高(独立硬件成本)
Namespace常用操作命令
命令 说明 kubectl create namespace <namespace-name>创建 Namespace kubectl get namespaces列出所有 Namespace kubectl describe namespace <namespace-name>查看 Namespace 详细信息 kubectl delete namespace <namespace-name>删除 Namespace(谨慎操作!) kubectl config set-context --current --namespace=<namespace-name>切换当前 kubectl 上下文到指定 Namespace
Namespace 的完整操作命令示例
创建 Namespace
kubectl create namespace dev # 创建名为 dev 的 Namespace kubectl create namespace prod # 创建名为 prod 的 Namespace查看 Namespace
kubectl get namespaces # 列出所有 Namespace kubectl describe namespace dev # 查看 dev Namespace 的详细信息(资源配额、标签等)删除 Namespace
kubectl delete namespace dev # 删除 dev Namespace(谨慎操作!此操作会删除 Namespace 内所有资源)切换 kubectl 上下文到指定 Namespace
kubectl config set-context --current --namespace=dev # 后续操作默认在 dev Namespace 下执行 kubectl config set-context --current --namespace=default # 切回默认 Namespace
创建资源配额 YAML 文件
1、使用任何文本编辑器(如 Vim、Nano、VS Code、Notepad++ 等)创建 YAML 文件
Linux/macOS(使用 Vim):
vim quota.yaml2. 编写 YAML 内容
在文件中粘贴以下内容(以设置
devNamespace 的资源配额为例):apiVersion: v1 kind: ResourceQuota metadata: name: dev-quota # 配额名称 namespace: dev # 应用到的 Namespace spec: hard: pods: "10" # 最大 Pod 数量 requests.cpu: "4" # 总 CPU 请求量(核心数) requests.memory: "8Gi" # 总内存请求量 limits.cpu: "8" # 总 CPU 限制量 limits.memory: "16Gi" # 总内存限制量 persistentvolumeclaims: "5" # 最大 PVC 数量3. 保存文件
Vim:按
Esc键,输入:wq保存并退出。二、应用资源配额
1. 通过 kubectl 应用配置
kubectl apply -f quota.yaml # 将配额应用到 dev Namespace2. 验证配置是否生效
kubectl describe resourcequota dev-quota -n dev # 查看配额详情及使用状态输出示例:
Name: dev-quota Namespace: dev Resource Used Hard -------- ---- ---- limits.cpu 2 8 limits.memory 4Gi 16Gi pods 2 10 persistentvolumeclaims 1 5 requests.cpu 1 4 requests.memory 2Gi 8Gi三、修改现有资源配额
1. 编辑 YAML 文件
直接修改
quota.yaml文件中的spec.hard部分,例如将内存限制调整为32Gi:spec: hard: limits.memory: "32Gi" # 修改后的值2. 重新应用配置
kubectl apply -f quota.yaml # 更新配额配置四、查看所有资源配额
kubectl get resourcequota -n dev # 列出 dev Namespace 下的所有配额五、删除资源配额
kubectl delete resourcequota dev-quota -n dev # 删除配额(不影响已存在的资源)注意事项
- YAML 语法:确保缩进正确(使用空格,非 Tab),键值对间用冒号
:分隔。- 资源单位:CPU 以核心数为单位(如
1表示 1 个核心),内存使用Mi(MebiBytes)或Gi(GibiBytes)。- 配额作用范围:配额限制的是 Namespace 内所有资源的总和,而非单个 Pod。
在指定 Namespace 中部署资源
在 dev Namespace 中部署 Deployment
apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment namespace: dev # 明确指定 Namespace spec: replicas: 2 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.21 resources: requests: memory: "128Mi" cpu: "250m" limits: memory: "256Mi" cpu: "500m"应用部署
kubectl apply -f nginx-deployment.yaml # 部署到 dev Namespace kubectl get pods -n dev # 查看 dev Namespace 中的 Pod
Pod
Pod 是 Kubernetes 的最小部署单元,是一个或多个共享网络和存储的容器集合。Pod 中的容器共享相同的网络命名空间、存储卷等资源,它们之间的通信非常高效。Pod 的生命周期由 Kubernetes 管理,例如创建、调度、重启和销毁。每个 Pod 有唯一 IP,容器通过
localhost通信。Pod 的 IP 是动态的,当 Pod 被删除或重建时,IP 会发生变化。
pod常用操作命令
命令 说明 kubectl describe pod <pod-name>查看 Pod 详细信息(事件、状态) kubectl logs <pod-name> -c <container-name>查看容器日志 kubectl exec -it <pod-name> -- /bin/bash进入容器终端 kubectl delete pod <pod-name>删除 Pod
部署一个简单的 Nginx Web 服务器。
kubectl apply -f nginx-pod.yaml # 创建 Pod kubectl get pods # 查看 Pod 状态 kubectl port-forward nginx-pod 8080:80 # 本地访问测试apiVersion: v1 kind: Pod metadata: name: nginx-pod spec: containers: - name: nginx image: nginx:1.21 ports: - containerPort: 80 # 容器暴露的端口
主应用容器 + 日志收集容器(如 Filebeat)
apiVersion: v1 kind: Pod metadata: name: multi-container-pod spec: containers: - name: app image: my-app:v1 env: - name: LOG_LEVEL value: "debug" - name: filebeat image: elastic/filebeat:8.0.0 volumeMounts: - name: app-logs mountPath: /var/log/app volumes: - name: app-logs emptyDir: {} # 共享临时存储卷
Service
Service 是 Kubernetes 中用于定义一组 Pod 的逻辑集合和访问策略的抽象。它提供了一个稳定的虚拟 IP 地址和负载均衡功能,使得应用程序可以通过 Service 的 IP 地址访问 Pod,而无需关心 Pod 的实际位置。Service 支持多种类型,例如
ClusterIP(集群内部)、NodePort(节点端口)、LoadBalancer(云厂商负载均衡器)。Service 隐藏了 Pod 的实际 IP,用户只需与 Service 的稳定 IP 交互,无需关心 Pod 的动态变化。当请求发送到 Service 的 Cluster IP 时,Service 会根据配置的负载均衡策略(默认是轮询)将流量分配给后端的 Pod。
Deployment
Deployment 是一个核心的控制器(Controller),用于管理无状态应用(如 Web 服务、API 等)的部署、扩展和更新。它的核心设计理念是声明式管理,即用户只需定义应用的期望状态(如副本数、镜像版本等),Deployment 会自动确保集群的实际状态与期望一致。
- 确保指定数量的 Pod 副本始终运行。若 Pod 崩溃或被删除,Deployment 会自动创建新 Pod 替代。
- 示例:定义
replicas: 3,则始终有 3 个 Pod 运行。
- 控制策略:通过
maxUnavailable(最大不可用 Pod 数)和maxSurge(最大超额 Pod 数)控制更新速度。- 示例:设置
maxUnavailable: 1和maxSurge: 1,则更新时最多有 1 个旧 Pod 不可用,同时最多新增 1 个新 Pod。无状态应用(Stateless Application)是一种设计范式,其核心特点是不保存客户端请求之间的状态。每个请求都是独立处理的,服务器不会因之前请求的历史记录而影响当前请求的处理。
StatefulSet
StatefulSet是Kubernetes中用于管理有状态应用(如数据库、消息队列)的控制器。它通过为每个Pod提供稳定的、唯一的标识符,确保Pod的创建、销毁和更新有序进行。主要功能包括:
- 稳定网络标识:每个Pod拥有唯一的主机名和网络标识,便于服务发现和通信。
- 持久化存储:支持将持久化存储卷(Persistent Volume)与Pod绑定,确保数据在Pod重启或迁移后保留。
- 有序部署与扩展:确保Pod按指定顺序部署和扩展,保证有序启动和关闭。
- 滚动更新:支持有序的滚动更新,确保更新过程中应用的高可用性。
DaemonSet
DaemonSet是Kubernetes中用于管理节点级Pod的控制器,确保每个节点(或符合标签选择器的节点)运行一个Pod副本。它通常用于运行集群存储、日志收集、监控等系统级服务,这些服务需要在每个节点上运行以提供全局功能。主要功能包括:
- 节点覆盖:在每个节点或特定节点上运行一个Pod,适用于日志收集、监控代理等全局服务。
- 自动扩缩:当新节点加入集群时,自动创建Pod;节点移除时,自动删除Pod。
- 更新策略:支持滚动更新,确保更新过程中服务不中断。
- 节点亲和性:通过节点选择器或亲和性规则控制Pod的调度。
- 容忍度:允许Pod调度到带有污点的节点,如Master节点。
ConfigMap & Secret
ConfigMap 是 Kubernetes 中用于存储非敏感配置数据的对象。它可以保存键值对(如环境变量、配置文件、命令行参数等),并在运行时动态注入到 Pod 中。
- 解耦配置与代码:将配置存储在 ConfigMap 中,而非硬编码在镜像或代码中。
- 动态更新:更新 ConfigMap 后,所有关联的 Pod 会自动获取最新配置(需应用支持热更新)。
- 注入方式:
- 环境变量:将 ConfigMap 的键值对作为环境变量注入 Pod。
- 卷挂载:将 ConfigMap 挂载为 Pod 内的文件或目录。
Secret 是 Kubernetes 中用于存储敏感信息的对象,如密码、API 密钥、TLS 证书等。Secret 的数据经过 Base64 编码,且支持更严格的访问控制。
- 安全存储:敏感数据以编码形式存储,避免明文暴露。
- 注入方式:
- 环境变量:将 Secret 的键值对作为环境变量注入 Pod。
- 卷挂载:将 Secret 挂载为 Pod 内的文件(如 TLS 证书)。
- 访问控制:结合 RBAC(基于角色的访问控制),限制对 Secret 的访问权限。
Volume
Kubernetes Volume 是一种抽象概念,用于在 Pod 内的容器之间共享数据以及为容器提供存储。Volume 的生命周期与 Pod 相同,但独立于容器的生命周期,即使容器重启,Volume 中的数据也不会丢失。常见 Volume 类型:
emptyDir:Pod 被分配到节点时创建的空目录,Pod 删除时数据会被清除。适用于临时存储
hostPath:将宿主机上的路径挂载到 Pod 中,用于访问宿主机文件系统。
PersistentVolume (PV) 和 PersistentVolumeClaim (PVC):PV 是集群中的持久化存储资源,PVC 是用户对 PV 的请求声明,Pod 可以通过 PVC 访问持久化存储。
Network Attached Storage (NAS):如 NFS、GlusterFS、CephFS 等,支持跨节点共享。
Cloud Provider Volumes:如 AWS EBS、GCP Persistent Disk、Azure Disk 等,与云提供商的存储服务集成。
Ingress
Ingress 是 Kubernetes 中用于管理外部访问集群内服务的 API 对象,通常用于 HTTP 和 HTTPS 流量。它提供了负载均衡、SSL 终结和基于名称的虚拟托管等功能。主要功能:
流量路由:通过定义的规则将外部流量映射到集群内的服务。
负载均衡:对进入的流量进行负载均衡。
SSL 终结:支持 SSL/TLS 证书管理。
基于名称的虚拟托管:支持多个域名访问不同的服务。
4. Kubernetes 主要功能
容器编排
Kubernetes 提供了强大的容器编排能力,能够自动管理容器的生命周期,包括创建、启动、停止、重启和销毁容器。用户可以通过定义 YAML 文件来描述应用程序的部署需求,Kubernetes 会根据这些定义自动完成容器的编排和管理。
自动扩缩容
Kubernetes 支持根据预设的规则自动调整应用程序的副本数量。例如,当应用程序的负载增加时,Kubernetes 可以自动增加 Pod 的副本数量以应对高负载;当负载降低时,又可以自动减少副本数量以节省资源。这种自动扩缩容功能使得应用程序能够动态适应不同的流量需求,提高资源利用率。
自我修复
Kubernetes 具有自我修复机制,能够自动检测并处理故障。如果某个 Pod 失败了,Kubernetes 会自动重新启动它;如果某个节点不可用,Kubernetes 会将该节点上的 Pod 调度到其他健康的节点上运行。这种自我修复功能大大提高了集群的可靠性和稳定性,减少了人工干预。
服务发现和负载均衡
Kubernetes 提供了内置的服务发现和负载均衡功能。通过 Service,应用程序可以轻松地发现和访问其他服务,而无需关心服务的具体位置和实例数量。Kube-Proxy 会根据预设的负载均衡策略,将请求分发到后端的 Pod 上,确保应用程序的高可用性和性能。
存储编排
Kubernetes 支持多种存储解决方案,能够将持久化存储卷动态地挂载到 Pod 上。用户可以通过定义 PersistentVolume(PV)和 PersistentVolumeClaim(PVC)来管理存储资源,Kubernetes 会根据 PVC 的请求自动分配和挂载 PV,实现存储的动态编排和管理。
配置管理
Kubernetes 提供了 ConfigMap 和 Secret 等机制,用于管理应用程序的配置和敏感信息。用户可以将配置数据和敏感信息存储在 ConfigMap 和 Secret 中,然后通过环境变量、挂载卷等方式将它们注入到 Pod 中。这种配置管理方式使得应用程序的配置和代码分离,便于管理和更新。
版本控制和回滚
Kubernetes 支持对应用程序的版本进行管理,用户可以通过 Deployment 等控制器来更新应用程序的镜像版本。在更新过程中,Kubernetes 会自动进行滚动更新,逐步替换旧版本的 Pod 为新版本的 Pod,确保应用程序的可用性。如果更新过程中出现问题,用户可以随时回滚到之前的版本,恢复应用程序的正常运行。
5. Kubernetes 使用场景
微服务架构
Kubernetes 是微服务架构的理想选择。它能够轻松地管理大量的微服务容器,实现服务发现、负载均衡、自动扩缩容等功能,使得微服务架构的应用程序能够高效、灵活地运行。通过 Kubernetes,开发人员可以专注于微服务的开发,而无需担心底层的基础设施管理。
云原生应用
云原生应用是指为云环境设计和优化的应用程序,它们通常采用容器化、微服务化等技术,具有弹性伸缩、高可用性、可移植性等特点。Kubernetes 作为云原生计算的核心平台,为云原生应用提供了强大的支持,使得应用程序能够在云环境中高效运行,并充分利用云资源的弹性特性。
大数据和机器学习
Kubernetes 也适用于大数据和机器学习场景。它能够管理大规模的数据处理任务和模型训练任务,通过自动扩缩容和资源管理功能,确保任务的高效运行。同时,Kubernetes 还支持多种存储解决方案,能够满足大数据和机器学习对存储的高要求。
持续集成和持续部署(CI/CD)
Kubernetes 可以与 CI/CD 工具(如 Jenkins、GitLab CI 等)集成,实现自动化的持续集成和持续部署流程。通过 Kubernetes,开发人员可以快速地将代码变更部署到生产环境中,提高开发效率和软件交付速度。
多租户环境
Kubernetes 的 Namespace 机制使得它能够支持多租户环境。在企业环境中,不同的团队或项目可以使用不同的 Namespace 来隔离资源,实现资源共享和管理的灵活性。同时,Kubernetes 还提供了资源配额(Resource Quota)和限制范围(LimitRange)等机制,用于控制每个租户的资源使用量,确保资源的合理分配。
6. Kubernetes 的优缺点
优点
强大的社区和生态(如 Helm、Prometheus、Istio)。
跨平台支持(AWS EKS、Google GKE、Azure AKS)。
高度可扩展(通过 CRD 自定义资源)。
缺点
学习曲线陡峭,概念复杂。
中小型项目可能过度复杂。
原生网络和存储方案需额外配置。
二、使用Kubernetes(k8s)配置服务器并允许其他客户端访问
关闭交换分区,docker安装和使用教程见:Ubuntu系统安装并使用docker-CSDN博客
查看docker镜像源:
docker info | grep Registry1、安装依赖组件
更新系统
sudo apt update && sudo apt upgrade -y
安装Kubernetes组件
扩展:
1、阿里云安装k8s:
kubernetes镜像_kubernetes下载地址_kubernetes安装教程-阿里巴巴开源镜像站
sudo apt install -y apt-transport-https ca-certificates curl software-properties-common # 完整命令链添加 sudo curl -fsSL https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.33/deb/Release.key | \ sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg echo "deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.33/deb/ /" | sudo tee /etc/apt/sources.list.d/kubernetes.list sudo apt-get update sudo apt-get install -y kubelet kubeadm kubectl2、查看安装的版本
wangqiang@wangqiang:/home$ kubelet --version Kubernetes v1.33.0 wangqiang@wangqiang:/home$ kubeadm version kubeadm version: &version.Info{Major:"1", Minor:"33", EmulationMajor:"", EmulationMinor:"", MinCompatibilityMajor:"", MinCompatibilityMinor:"", GitVersion:"v1.33.0", GitCommit:"60a317eadfcb839692a68eab88b2096f4d708f4f", GitTreeState:"clean", BuildDate:"2025-04-23T13:05:48Z", GoVersion:"go1.24.2", Compiler:"gc", Platform:"linux/amd64"} wangqiang@wangqiang:/home$ kubectl version --client Client Version: v1.33.0 Kustomize Version: v5.6.0
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.28/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
作用:下载 Kubernetes 仓库的 GPG 密钥,并将其存储到系统的 APT 密钥环中,以确保后续安装的软件包来源的安全性。
curl -fsSL <URL>:从指定 URL 下载文件,其中-fsSL参数的含义:
-f:在发生错误时静默失败(不输出多余信息)。
-s:静默模式(不显示进度条)。
-S:在静默模式下仍显示错误信息。
-L:跟随重定向(如果 URL 跳转)。
sudo gpg --dearmor:将 GPG 密钥转换为二进制格式(--dearmor),以便 APT 能正确识别。
-o /etc/apt/keyrings/kubernetes-apt-keyring.gpg:将转换后的密钥保存到指定文件路径。
curl的作用是从指定的 URL下载内容,并将输出传递到管道(|)的下一个命令。
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.28/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
作用:将 Kubernetes 的 APT 仓库地址添加到系统的软件源列表中。
echo 'deb [signed-by=...] <URL> /':生成一个 APT 源条目,指定软件包的下载地址和签名密钥。
deb:表示这是一个 Debian 软件包仓库。
[signed-by=...]:指定验证软件包签名的密钥文件路径。
<URL>:Kubernetes 仓库的地址。
/:表示该仓库支持所有默认的 APT 组件(components)。
sudo tee /etc/apt/sources.list.d/kubernetes.list:将生成的内容写入到文件/etc/apt/sources.list.d/kubernetes.list中,这是 APT 搜索并读取自定义仓库配置的目录。
sudo apt update
作用:更新 APT 的软件包缓存,使其包含新添加的 Kubernetes 仓库中的软件包信息。
sudo apt install -y kubelet kubeadm kubectl
作用:安装三个核心的 Kubernetes 组件:
kubelet:在每个节点上运行,负责管理Pod和容器。
kubeadm:用于初始化和管理 Kubernetes 集群的工具。
kubectl:Kubernetes 命令行工具,用于与集群交互。
sudo apt-mark hold kubelet kubeadm kubectl
作用:将指定的软件包标记为“保留”状态,防止它们被自动更新。这可以避免版本不兼容的问题。
2、初始化Kubernetes集群
kubeadm config images list:输出 Kubernetes 集群初始化时需要的镜像及其版本信息,包括 Kubernetes 控制平面组件(如 kube-apiserver、kube-controller-manager、kube-scheduler)、kube-proxy、etcd 以及 pause 容器等。
wangqiang@wangqiang:/home$ kubeadm config images list
registry.k8s.io/kube-apiserver:v1.33.0
registry.k8s.io/kube-controller-manager:v1.33.0
registry.k8s.io/kube-scheduler:v1.33.0
registry.k8s.io/kube-proxy:v1.33.0
registry.k8s.io/coredns/coredns:v1.12.0
registry.k8s.io/pause:3.10
registry.k8s.io/etcd:3.5.21-0
定义镜像列表
images=(
kube-apiserver:v1.33.0
kube-controller-manager:v1.33.0
kube-scheduler:v1.33.0
kube-proxy:v1.33.0
coredns/coredns:v1.12.0
pause:3.10
etcd:3.5.21-0
)避免手动维护镜像列表,直接通过 kubeadm 命令生成列表,确保完整性:
#!/bin/bash
# 动态获取Kubernetes v1.33.0所需镜像列表
K8S_VERSION="v1.33.0"
images=$(kubeadm config images list --kubernetes-version $K8S_VERSION | awk -F'/' '{print $NF}')
for imageName in $images; do
# 处理coredns路径差异(阿里云路径为coredns,非coredns/coredns)
if [[ $imageName == "coredns/coredns:v1.12.0" ]]; then
aliImage="coredns:v1.12.0"
else
aliImage="$imageName"
fi
# 从阿里云拉取镜像
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/$aliImage
# 重标签为官方路径
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/$aliImage registry.k8s.io/$imageName
# 删除临时镜像
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/$aliImage 2>/dev/null
done容器运行时(如 containerd 或 Docker)当前使用的 pause 镜像版本为 3.8,但 Kubernetes v1.33.0 要求使用 pause:3.10。以下是解决方案:
# 1. 生成默认 containerd 配置(若文件不存在)
sudo mkdir -p /etc/containerd
containerd config default | sudo tee /etc/containerd/config.toml
# 2. 修改 pause 镜像版本
sudo sed -i 's#sandbox_image = "registry.k8s.io/pause:3.8"#sandbox_image = "registry.k8s.io/pause:3.10"#g' /etc/containerd/config.toml
# 3. 重启 containerd 服务
sudo systemctl restart containerd
# 4. 重启 Docker 服务(确保 Docker 使用更新后的 containerd)
sudo systemctl restart docker验证镜像列表
wangqiang@wangqiang:/home$ docker images | grep -E 'kube-apiserver|kube-controller-manager|kube-scheduler|kube-proxy|coredns|pause|etcd'
registry.k8s.io/kube-apiserver v1.33.0 6ba9545b2183 26 hours ago 102MB
registry.k8s.io/kube-controller-manager v1.33.0 1d579cb6d696 26 hours ago 94.6MB
registry.k8s.io/kube-proxy v1.33.0 f1184a0bd7fe 26 hours ago 97.9MB
registry.k8s.io/kube-scheduler v1.33.0 8d72586a7646 26 hours ago 73.4MB
registry.k8s.io/etcd 3.5.21-0 499038711c08 3 weeks ago 153MB
registry.k8s.io/coredns/coredns v1.12.0 1cf5f116067c 5 months ago 70.1MB
registry.k8s.io/coredns v1.12.0 1cf5f116067c 5 months ago 70.1MB
registry.k8s.io/kube-apiserver v1.28.15 9dc6939e7c57 6 months ago 125MB
registry.k8s.io/kube-controller-manager v1.28.15 10541d8af03f 6 months ago 121MB
registry.k8s.io/kube-proxy v1.28.15 ba6d7f8bc25b 6 months ago 81.8MB
registry.k8s.io/kube-scheduler v1.28.15 9d3465f8477c 6 months ago 59.3MB
registry.k8s.io/etcd 3.5.15-0 2e96e5913fc0 9 months ago 148MB
registry.k8s.io/pause 3.10 873ed7510279 11 months ago 736kB
初始化集群
sudo kubeadm init --kubernetes-version v1.33.0遇到问题,后续更新
初始化Master节点
sudo kubeadm init --pod-network-cidr=10.244.0.0/16 # 使用Flannel网络插件使用
kubeadm工具来初始化一个新的 Kubernetes 集群。它会设置控制平面(Control Plane)节点(通常是一个主节点),并为集群配置网络。
sudo:以超级用户权限运行命令,因为某些操作需要管理员权限。
kubeadm init:初始化一个新的 Kubernetes 集群。
--pod-network-cidr=10.244.0.0/16:指定集群中 Pod 网络的 CIDR(无类别域间路由)范围。这个参数告诉 Kubernetes 如何为集群中的 Pod 分配 IP 地址。
10.244.0.0/16是一个常见的默认值,用于 Flannel 网络插件(一种常用的 CNI 网络插件)。你也可以根据需要选择其他范围,但需要确保它与集群中的其他网络(如服务网络)不冲突。
遇到的问题,拉取镜像失败,
# 创建或更新 Docker 配置文件,添加多个镜像源
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": [
"http://mirrors.ustc.edu.cn",
"https://docker.zhai.cm",
"https://a.ussh.net",
"https://func.ink",
"https://dytt.online",
"https://lispy.org",
"http://mirror.azure.cn"
]
}
EOF
# 重启 Docker 以应用更改
sudo systemctl restart dockersudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://cz5sz8zh.mirror.aliyuncs.com"]
}
EOFsudo systemctl daemon-reload
sudo systemctl restart docker运行 kubeadm init 后,系统会输出一些信息,包括如何配置 kubelet 和如何将其他节点加入集群的指令。以下是关键步骤:
配置kubectl(Kubernetes 节点代理),使其能够与控制平面通信:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config目的是将 Kubernetes 集群的管理员配置文件复制到当前用户的家目录下,以便
kubectl命令行工具能够正确地与集群通信。
mkdir -p $HOME/.kube
创建目录
$HOME/.kube(如果目录不存在)。
$HOME是当前用户的家目录,-p参数确保即使目录已存在也不会报错。
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
将 Kubernetes 生成的管理员配置文件
/etc/kubernetes/admin.conf复制到$HOME/.kube/config。
-i参数会在覆盖文件前提示用户确认(如果目标文件已存在)。这个配置文件包含了与 Kubernetes API 服务器通信所需的凭据和配置信息。
sudo chown $(id -u):$(id -g) $HOME/.kube/config
更改
$HOME/.kube/config文件的所有权,使其属于当前用户。
$(id -u)获取当前用户的用户 ID,$(id -g)获取当前用户的主组 ID。这一步确保当前用户有权读取和写入该配置文件,否则
kubectl可能会因为权限问题无法正常工作。
初始化完成后,需要安装一个 CNI(容器网络接口)网络插件,以便 Pod 之间可以相互通信。常用的插件包括 Flannel、Calico、Cilium 等。安装 Flannel:
kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml目的是在 Kubernetes 集群中部署一个网络插件(CNI,Container Network Interface),以便集群中的 Pod 可以相互通信。
kubectl apply -f <URL>
使用
kubectl命令应用指定的 YAML 配置文件。
-f <URL>指定配置文件的来源,这里是一个远程 URL。Flannel 是一个流行的 CNI 插件,
kube-flannel.yml是其部署配置文件。Flannel 的功能
Flannel 为 Kubernetes 提供了一个覆盖网络(Overlay Network),使得不同节点上的 Pod 可以通过 IP 地址直接相互通信。
它会根据步骤1中指定的
--pod-network-cidr参数来分配 Pod 的 IP 地址。其他网络插件
除了 Flannel,还有其他 CNI 插件(如 Calico、Cilium 等)可以根据需求选择。
选择网络插件时,需要确保其兼容 Kubernetes 版本和集群的网络配置。
将工作节点(Worker Node)加入集群时,你需要在工作节点上运行 kubeadm join 命令。主节点初始化时会输出这个命令,格式类似:
kubeadm join <控制平面节点IP>:<端口> --token <token> --discovery-token-ca-cert-hash <hash>目的是将一个新的工作节点(Worker Node)加入到已初始化的 Kubernetes 集群中。
kubeadm join
使用
kubeadm工具将当前节点加入到一个现有的 Kubernetes 集群中。
<控制平面节点IP>:<端口>
指定控制平面节点(主节点)的 IP 地址和端口。
例如:
192.168.1.100:6443,其中6443是 Kubernetes API 服务器的默认端口。
--token <token>
指定一个安全令牌(Token),用于验证工作节点的身份。
这个令牌在步骤1(
kubeadm init)的输出中提供,有效期默认为 24 小时。
--discovery-token-ca-cert-hash <hash>
指定一个哈希值,用于验证控制平面节点的 CA(证书颁发机构)证书。
这个哈希值在步骤1的输出中提供,确保工作节点信任控制平面节点的证书。
常见问题
网络插件冲突:确保选择的
--pod-network-cidr范围与集群中的其他网络(如服务网络)不冲突。防火墙限制:某些网络端口(如 6443、2379-2380 等)需要开放,否则节点之间可能无法通信。
初始化失败:如果初始化失败,可以尝试清理节点状态并重新初始化:
sudo kubeadm reset sudo rm -rf ~/.kube/*
3、部署示例应用
创建Deployment
创建一个Nginx示例应用:
kubectl create deployment nginx --image=nginx:latest创建Service(暴露服务)
kubectl expose deployment nginx --type=NodePort --port=804、客户端访问服务
查看服务端口
kubectl get svc nginx输出示例:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx NodePort 10.96.123.45 <none> 80:32456/TCP 5m
客户端可通过任意节点IP + 端口 32456(NodePort)访问服务。
开放防火墙(如果需要)
sudo ufw allow 32456/tcp访问服务
从客户端浏览器或命令行访问:
curl http://<节点IP>:324565、扩展与维护
扩展副本数量
kubectl scale deployment nginx --replicas=3查看Pod状态
kubectl get pods -o wide删除服务
kubectl delete svc nginx
kubectl delete deployment nginx6、常见问题排查
-
节点未就绪(Not Ready):
-
检查网络插件是否安装正确(如Flannel)。
-
执行
kubectl describe node <节点名>查看详情。
-
-
服务无法访问:
-
确认防火墙放行端口。
-
检查Service的NodePort是否配置正确。
-
-
重置集群:
sudo kubeadm reset
rm -rf $HOME/.kube三、完全卸载Kubernetes(主节点/工作节点通用)
# 1. 停止 kubelet 服务
sudo kubeadm reset -f # 强制重置集群
sudo systemctl stop kubelet # 停止 kubelet 服务,防止其在卸载过程中运行
sudo systemctl disable kubelet # 禁用 kubelet 服务,避免开机自启
# 2. 卸载 kubeadm、kubelet 和 kubectl
sudo apt remove --purge kubeadm kubelet kubectl kubernetes-cni # 使用 apt 卸载软件包,--purge 用于删除配置文件
# 3. 清理残留文件和目录
sudo rm -rf /etc/kubernetes # 删除 Kubernetes 配置目录,包含集群配置等
sudo rm -rf /var/lib/kubelet # 删除 kubelet 工作目录,包含相关数据和状态文件
sudo rm -rf /var/lib/dockershim # 删除 Docker Shim 相关文件,用于处理容器运行时交互
sudo rm -rf /etc/cni # 删除容器网络接口(CNI)配置文件目录,包含网络插件配置
sudo rm -rf ~/.kube # 删除用户主目录下的 Kubernetes 配置文件,通常含 kubectl 配置
sudo rm -rf /var/lib/etcd/ # 删除 etcd 数据
# 4. 清理网络配置
sudo ip link delete flannel.1 2>/dev/null # 删除 Flannel 虚拟接口(如果存在)。2>/dev/null 用于忽略接口不存在时的报错。
sudo ip link delete cni0 2>/dev/null # 删除 CNI 默认虚拟接口(如果存在)
sudo rm -rf /etc/cni/net.d/* # 删除所有 CNI 插件配置文件
sudo rm -rf /var/lib/cni/ # 删除 CNI 插件运行时数据
sudo rm -rf /var/lib/kubelet/pods/ # 删除 Pod 网络命名空间残留
sudo rm /etc/apt/keyrings/kubernetes-apt-keyring.gpg验证卸载是否成功
# 1. 验证 kubeadm、kubelet 和 kubectl 是否已卸载
kubeadm --version # 检查 kubeadm 是否卸载成功,成功则提示命令未找到
kubectl version --client # 检查 kubectl 是否卸载成功,成功则提示命令未找到
which kubelet # 检查 kubelet 是否卸载成功,成功则不返回路径
# 2. 验证残留文件和目录是否已清理
ls /etc/kubernetes # 检查 /etc/kubernetes 目录是否已删除
ls /var/lib/kubelet # 检查 /var/lib/kubelet 目录是否已删除
ls /etc/cni # 检查 /etc/cni 目录是否已删除
ls ~/.kube # 检查 ~/.kube 目录是否已删除
# 3. 验证网络配置是否已清理
sudo ip link show | grep -E 'flannel.1|cni0' # 检查 flannel.1 和 cni0 网络接口是否已删除
ls /etc/cni/net.d # 检查 /etc/cni/net.d 目录是否已删除
# 4. 验证apt缓存中是否还存在相关软件包
apt list --installed | grep -i kubernetes # 检查是否还有残留的 Kubernetes 相关软件包删除仓库配置示例
wangqiang@wangqiang:~$ sudo apt update && sudo apt upgrade -y
命中:1 http://mirrors.aliyun.com/ubuntu jammy InRelease
命中:2 http://mirrors.aliyun.com/ubuntu jammy-updates InRelease
命中:3 http://mirrors.aliyun.com/ubuntu jammy-backports InRelease
命中:4 http://mirrors.aliyun.com/ubuntu jammy-security InRelease
错误:5 https://prod-cdn.packages.k8s.io/repositories/isv:/kubernetes:/core:/stable:/v1.33.0/deb InRelease
403 Forbidden [IP: 3.165.75.66 443]
正在读取软件包列表... 完成
E: 无法下载 https://pkgs.k8s.io/core:/stable:/v1.33.0/deb/InRelease 403 Forbidden [IP: 3.165.75.66 443]
E: 仓库 “https://pkgs.k8s.io/core:/stable:/v1.33.0/deb InRelease” 没有数字签名。
N: 无法安全地用该源进行更新,所以默认禁用该源。
N: 参见 apt-secure(8) 手册以了解仓库创建和用户配置方面的细节。
wangqiang@wangqiang:~$ ls /etc/apt/sources.list.d/
archive_uri-https_mirrors_aliyun_com_kubernetes_apt_-jammy.list kubernetes.list
wangqiang@wangqiang:~$ sudo rm /etc/apt/sources.list.d/kubernetes.list
wangqiang@wangqiang:~$ sudo apt update
命中:1 http://mirrors.aliyun.com/ubuntu jammy InRelease
命中:2 http://mirrors.aliyun.com/ubuntu jammy-updates InRelease
命中:3 http://mirrors.aliyun.com/ubuntu jammy-backports InRelease
命中:4 http://mirrors.aliyun.com/ubuntu jammy-security InRelease
正在读取软件包列表... 完成
正在分析软件包的依赖关系树... 完成
正在读取状态信息... 完成
有 4 个软件包可以升级。请执行 ‘apt list --upgradable’ 来查看它们。四、ubantu操作指令说明
sudo rm -rf:非常强大的命令,用于在 Linux 或类 Unix 系统中删除文件和目录。然而,它也是一个非常危险的命令,因为它会强制删除指定的文件或目录,且无法恢复。# 强制删除指定的文件,即使文件不存在也不会报错 sudo rm -f 文件名 # 递归删除指定的目录及其所有子目录和文件,且不会提示用户确认 sudo rm -rf 目录名
rm是 "remove" 的缩写,用于删除文件和目录。
-r是递归(recursive)选项,表示删除指定目录及其所有子目录和文件。如果不使用-r,rm只能删除文件,而不能删除目录。
-f是强制(force)选项,表示在删除文件时不提示用户确认。它会忽略不存在的文件,且不会提示用户是否确认删除。
其他
REST API介绍
REST API(Representational State Transfer Application Programming Interface)是一种基于HTTP协议的接口设计风格,用于不同系统之间的数据交互。它的核心思想是通过资源(Resource)和标准HTTP方法(GET、POST、PUT、DELETE等)实现服务端与客户端的通信。
关键概念解析
资源(Resource)
REST 将一切数据视为“资源”,例如用户、订单、图片等。
每个资源通过唯一的URI(统一资源标识符)标识,例如:
/users/123表示ID为123的用户。HTTP方法(HTTP Verbs)
通过标准HTTP方法定义对资源的操作:
GET:获取资源(查询)
POST:创建资源
PUT:更新资源(全量替换)
DELETE:删除资源
PATCH:部分更新资源无状态(Stateless)
服务端不保存客户端请求的上下文,每次请求必须包含所有必要信息(如身份认证、参数等)。
表述性(Representation)
资源的具体表现形式可以是JSON、XML、HTML等格式,客户端与服务端通过协商(如HTTP头
Accept和Content-Type)决定使用哪种格式。
REST API 的典型特点
统一接口(Uniform Interface):使用标准的HTTP方法和状态码,简化交互逻辑。
可寻址性(Addressability):每个资源有唯一的URI。
可缓存性(Cacheability):通过HTTP缓存机制提升性能。
分层系统(Layered System):客户端无需关心服务端具体实现,例如是否有负载均衡、代理等。
示例:一个用户管理的REST API
1、获取用户列表
GET /users
返回JSON格式的用户列表:[{"id": 1, "name": "Alice"}, {"id": 2, "name": "Bob"}]
2、创建新用户(http)
POST /users Body(JSON): {"name": "Charlie"}
返回新用户的URI:HTTP/1.1 201 Created Location: /users/3
3、删除用户(http)
DELETE /users/3
RESTful设计原则
URI设计:使用名词(而非动词)表示资源,例如:
/articles(正确) vs/getArticles(非REST风格)。状态码(Status Codes):通过HTTP状态码反馈结果,例如:
200 OK:请求成功
404 Not Found:资源不存在
401 Unauthorized:未授权版本控制:在URI或HTTP头中指定API版本,例如:
/api/v1/users。
REST vs. 传统API(如SOAP)
特性 REST API SOAP 协议 基于HTTP 通常基于HTTP/SMTP 数据格式 JSON、XML等 仅XML 性能 轻量、高效 较臃肿(XML+WS-*规范) 灵活性 高(无严格规范约束) 低(需遵循严格规范) 使用场景 现代Web/移动应用 企业级复杂系统(如银行)
总结
REST API 是一种以资源为中心、基于HTTP标准的接口设计风格,通过简洁的URI和明确的HTTP方法实现高效的数据交互。它的设计哲学是简单、灵活、可扩展,广泛应用于Web、移动应用和微服务架构中。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











