









问题
生成的取数结果含有纯数字,在保存为csv文件并用Excel或WPS查看结果时,数字会以科学表达式,或Excel默认的单元格格式展示,非常的不友好

描述
在通过pyspark脚本,按需求清洗(按条件筛选)、聚合(按日期、月份进行分组)后,得到的数据,通常会包含纯数字的用户id(如 05912000003186)或者编码code(如 00600637000000010000000007149945变为6.00637E+29),同时调整单元格格式又找不到符合的格式
| 原数据 | Excel展示数据 |
|---|---|
| 00600637000000010000000007149945 | 6.00637E+29 |
方法
在纯数字的末尾添加tab制表符(转义字符 ‘\t’)
import pyspark.sql.functions as F
df = df.select('user_id','code')
df1 = df.withColumn("sep", F.lit("\t"))
data = df1.withColumn("new_code", F.concat(df1.code, df1.sep))
结果如下图

Excel上展示效果
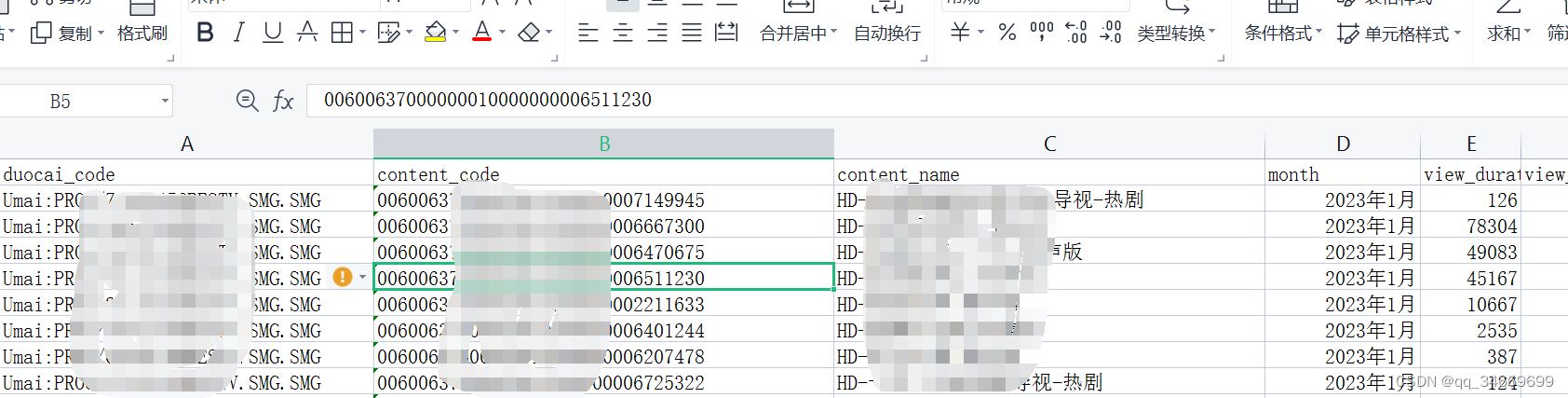
这样就可以巧妙的避免Excel自动处理纯数字的数据















 9734
9734











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









