







概览
Redis 3.2 版本前,列表的底层是采用 linkedlist 与 ziplist 作为数据结构实现,而在 3.2 版本之后则改为了 quicklist。
那 quicklist 究竟是什么样的数据结构,出现的原因又是什么?
这要源于 2014 年,一个名为 mattsta 的大佬给 Redis 提了一个 PR,号称自己实现了 twitter 之前所描述的一种非常高效的数据结构,而这种数据结构是链表与 ziplist 的结合体,原文如下:
My implementation of what Twitter has previously described as ziplists in a linked list for better memory efficiency.
Longer writeup with improvement graphs at https://matt.sh/redis-quicklist
PR 的链接:https://github.com/redis/redis/pull/2143。
首先 quicklist 是基于时间和空间效率上权衡的一个产物,原因如下:
- linkedlist 在插入,删除节点时有较高的效率,但当数据规模较小时,空间的利用率很低(节点需要额外存储指针信息)
- ziplist 拥有较高的空间利用率,但在数据规模较大时,它的插入,删除效率会大大降低(需要进行大范围的内存重分配操作)
quicklist 取长补短,既吸收了 ziplist 的内存压缩特性,又保持了 linkedlist 高效率增删节点的特性,因此 Redis 在 3.2 版本之后直接用 quicklist 作为列表的底层数据结构,替代了原本的 linkedlist 与 ziplist。
本文主要讲述 quicklist 的底层实现原理,揭秘它为何既“快”又“稳”。
数据结构
quicklist 本质是双向链表和压缩列表的结合体,整体数据结构模型如下:

数据结构如下:

- head,tail 为头尾节点指针
- count,所有 ziplist 中的 entry 总数
- len,quicklist 节点总数
- fill 属性,控制 ziplist 节点的最大容量,如果 fill 属性设置过大,quicklist 会退化成 ziplist
- compress 属性,控制压缩深度,防止不必要的压缩工作(quicklist 会对部分节点,通过 LZF 算法进行压缩)
quicklistNode 节点的数据结构如下:
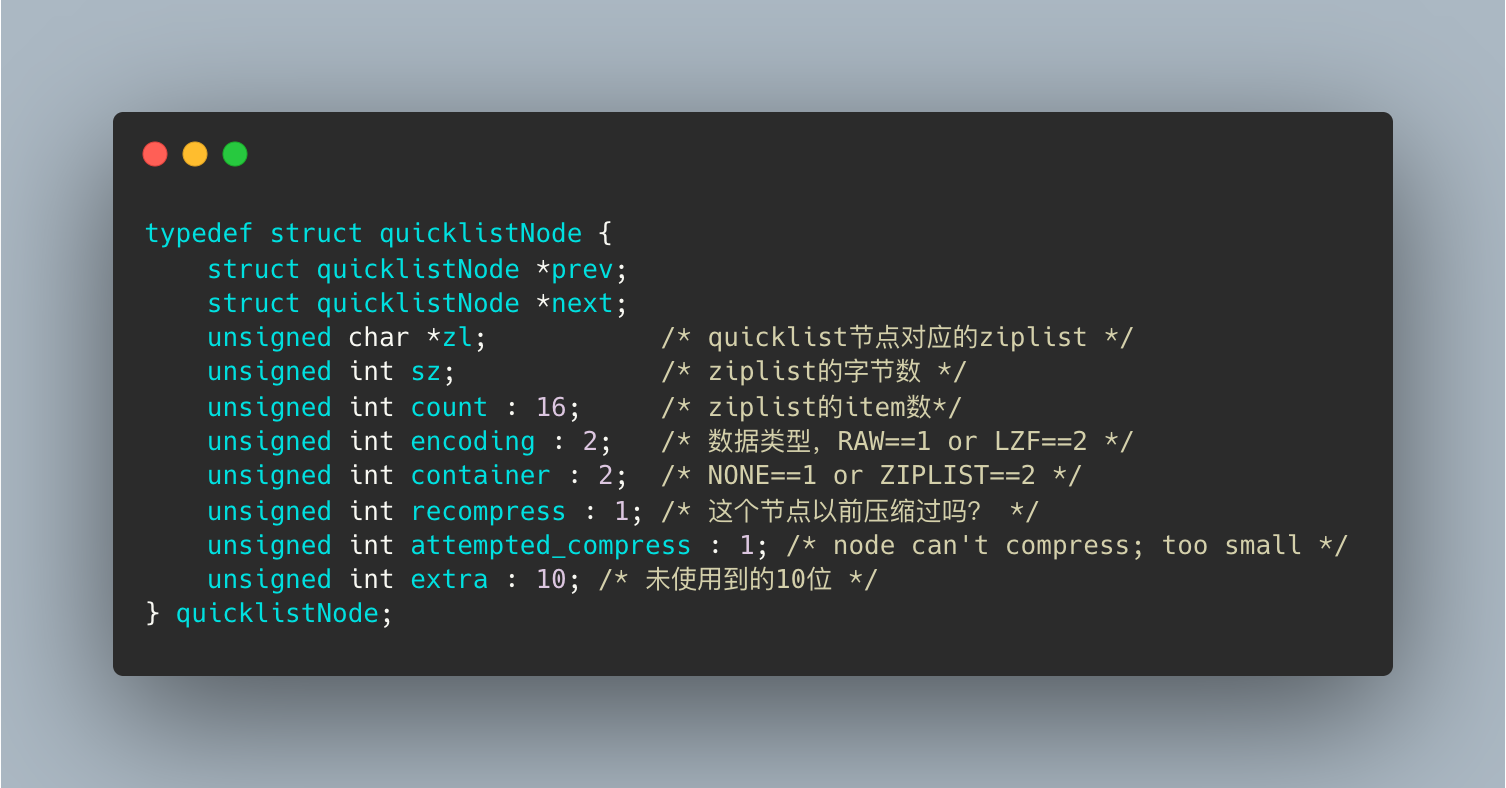
- prev,next 指针分别指向前后节点
- zl,指向节点对应的 ziplist
- count,ziplist 中存储的数据量
- encoding,数据类型编码 RAW1 or LZF2,标识节点数据是否被压缩
下面主要讲解 quicklist 的数据更新实现逻辑。
数据插入(头插和尾插)
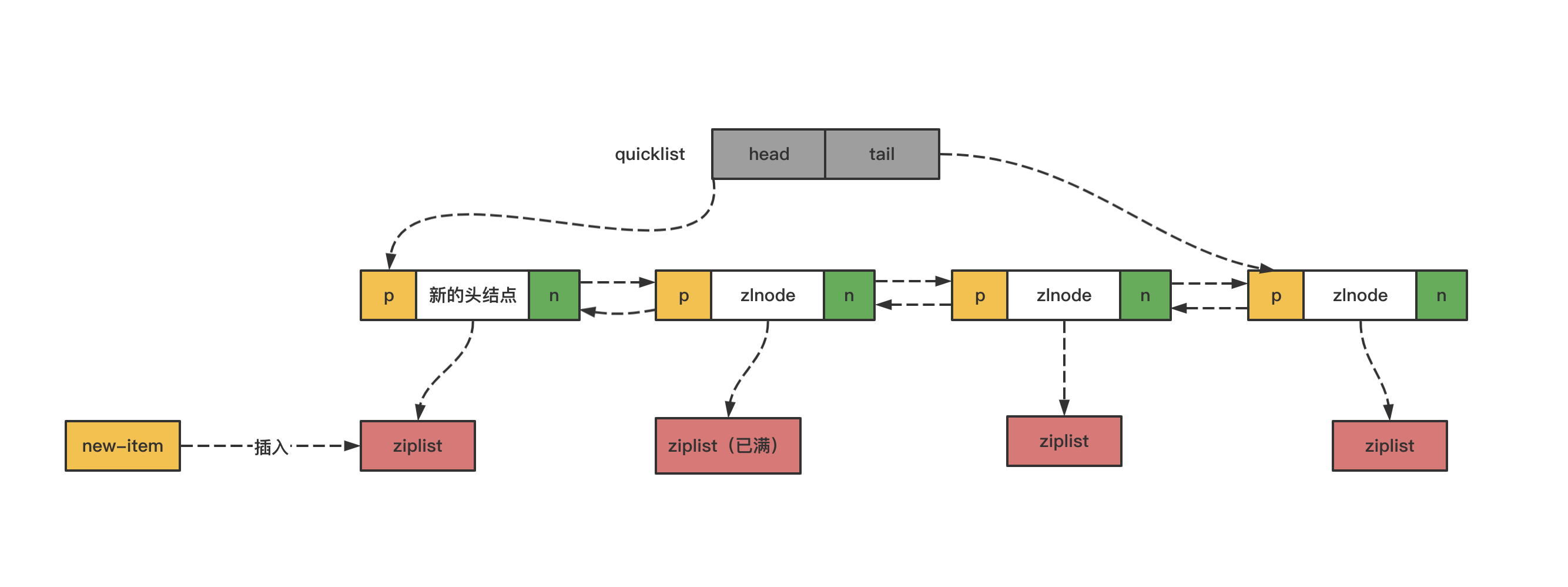
头插和尾插相对更简单些:
- 如果头/尾节点的 ziplist 空间未满(通过 fill 属性判断),则直接将数据插入对应的 ziplist 中
- 如果头/尾节点的 ziplist 空间已满,则需要新建节点
如下图所示,往链表头部插入数据项,但头结点的 ziplist 数据已满,则生成新的头结点,将数据插入新生成的节点中,往尾部插入数据也同理。
数据插入(特定位置插入)
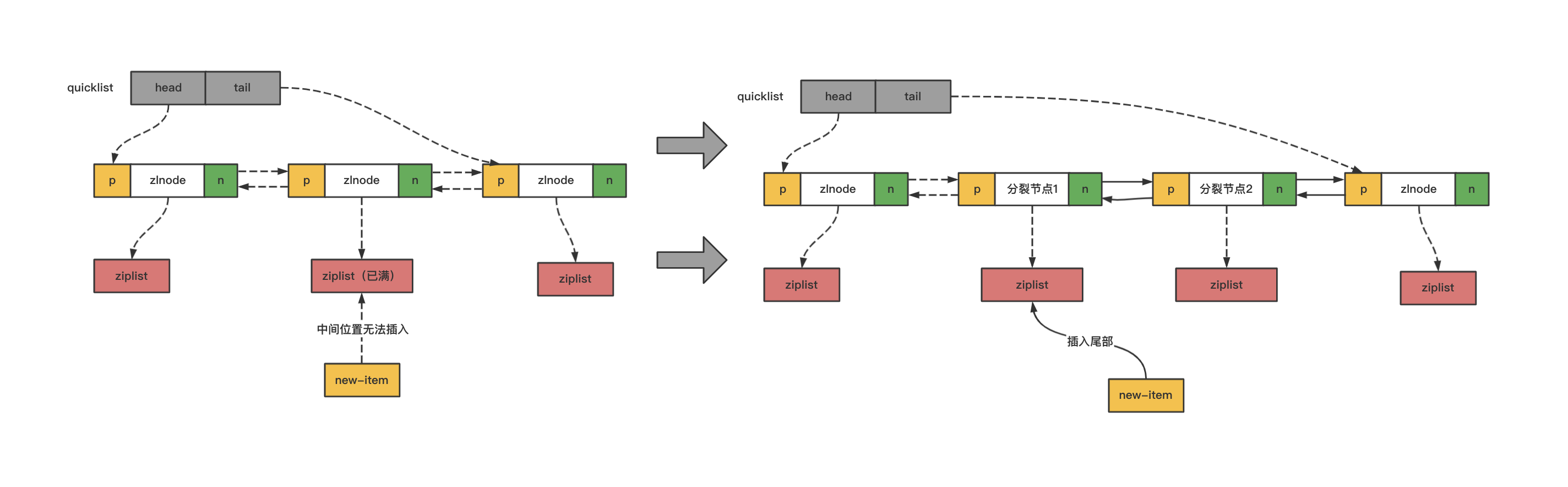
往特定位置插入就复杂多了,涉及多种情况。
1.如果当前被插入节点不满,直接插入;
2.如果当前被插入节点是满的,要插入的位置是当前节点的尾部,且后一个节点有空间,那就插入到后一个节点的头部,如下图所示;

3.如果当前被插入节点是满的,要插入的位置是当前节点的头部,且前一个节点有空间,那就插入到前一个节点的尾部,如下图所示;

4.如果当前被插入节点是满的,前后节点也都是满的,要插入的位置是当前节点的头部或者尾部,那就创建一个新的节点插进去,如下图所示;

5.如果当前节点是满的,且要插入的位置在当前节点的中间位置,我们需要把当前节点分裂成两个新节点,然后再插入,如下图所示;
数据删除
删除相对于插入而言就简单多了,直接把 ziplist 对应位置数据删除,并没有节点合并的操作。















 362
362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









