







 本文详述了LuckyRabbit团队在第二届搜狐内容识别算法大赛中夺冠的解决方案,包括任务说明、数据处理、特征提取、模型构建(深度学习和机器学习)、模型融合策略(Stacking、Pseudo labeling、Snapshot Ensemble)以及数据增强和预处理技术的应用。团队利用OCR、词向量和文本翻译增强数据,通过模型融合提高分类性能。
本文详述了LuckyRabbit团队在第二届搜狐内容识别算法大赛中夺冠的解决方案,包括任务说明、数据处理、特征提取、模型构建(深度学习和机器学习)、模型融合策略(Stacking、Pseudo labeling、Snapshot Ensemble)以及数据增强和预处理技术的应用。团队利用OCR、词向量和文本翻译增强数据,通过模型融合提高分类性能。
第二届搜狐内容识别大赛冠军LuckyRabbit团队的解决方案
本文主要是向大家介绍一下团队的解决方案,具体代码和答辩PPT可以上 github
任务说明
比赛的网站是这里,比赛时长是两个半月、也算是时间很长的一个比赛了
任务要求
比赛的目的是给我们一篇新闻,希望我们给出:
- 新闻是属于全营销类别、部分营销类别、还是无营销类别。这里相当于是一个分类问题
- 对部分营销类别的新闻,我们要给出属于营销类别的文本片段和图片。这里是信息抽取和图像分类的问题
数据格式
数据给出来的是原生的HTML格式,如下:
<title>惠尔新品 | 冷色系实木多层地板系列</title> <p> </p> <br/><p> <span style="font-size: 16px;">冷色系实木多层系列全新上市</span></p> P0000001.JPEG;P0000002.JPEG;
我们要先把HTML解析成可训练的文本和图片
评分标准
官方使用的是F1-measure来进行得分评判
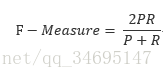
代码流程
模型融合是打比赛的大杀器,我们团队也是采用了这种方案,下面就来介绍一下我们团队的代码流程。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









