






声明:该笔记为学习笔记,如有理解不到位的地方或者错误的地方恳请指正,以下仅代表个人观点。如有不合适的地方可联系删除。
视频链接地址:书生·浦语大模型全链路开源体系_哔哩哔哩_bilibili
一、模型介绍
2024 年1 月 17 日InternLM 2正式开源,包含两个规格7B 和 20B,并且按照不同的需求又设计了三个不同的版本InternLM2-Base、InternLM2和InternLM2-Chat。
- 7B:为轻量级的研究和应用提供了一个轻便但性能不俗的模型
- 20B:模型的综合性能更为强劲,可有效支持更加复杂的使用场景
- InternLM2-Base:高质量和具有很强可塑性的模型基座,是模型进行深度领域适配的高质量起点。
- InternLM2:进一步在大规模无标签数据上进行预训练,并结合特定领域的增强语料库进行训练,在评测中成绩优异,同时保持了很好的通用语言能力,是我们推荐的在大部分应用中考虑选用的优秀基座。
- InternLM2-Chat-SFT: 基于 InternLM2-Base 模型进行了有监督微调,是 InternLM2-Chat 模型的中间版本。我们将它们开源以助力社区在对齐方面的研究。
- InternLM2-Chat: 在 InternLM2-Chat-SFT 的基础上进行了 online RLHF 以进一步对齐. InternLM2-Chat 面向对话交互进行了优化,具有较好的指令遵循、共情聊天和调用工具等的能力,是我们推荐直接用于下游应用的模型。
二、新一代数据清洗技术
大语言模型的数据质量会很大程度上影响大语言模型的性能,所以即使相同结构的大语言模型训练的数据质量不同,也会导致性能上的差距。

三、InternLM2的亮点
- 有效支持20万字超长上下文:模型在 20 万字长输入中几乎完美地实现长文“大海捞针”,而且在 LongBench 和 L-Eval 等长文任务中的表现也达到开源模型中的领先水平。 可以通过 LMDeploy 尝试20万字超长上下文推理。
- 综合性能全面提升:各能力维度相比上一代模型全面进步,在推理、数学、代码、对话体验、指令遵循和创意写作等方面的能力提升尤为显著,综合性能达到同量级开源模型的领先水平,在重点能力评测上 InternLM2-Chat-20B 能比肩甚至超越 ChatGPT (GPT-3.5)。
- 代码解释器与数据分析:在配合代码解释器(code-interpreter)的条件下,InternLM2-Chat-20B 在 GSM8K 和 MATH 上可以达到和 GPT-4 相仿的水平。基于在数理和工具方面强大的基础能力,InternLM2-Chat 提供了实用的数据分析能力。
- 工具调用能力整体升级:基于更强和更具有泛化性的指令理解、工具筛选与结果反思等能力,新版模型可以更可靠地支持复杂智能体的搭建,支持对工具进行有效的多轮调用,完成较复杂的任务。可以查看更多样例。
四、从模型到应用
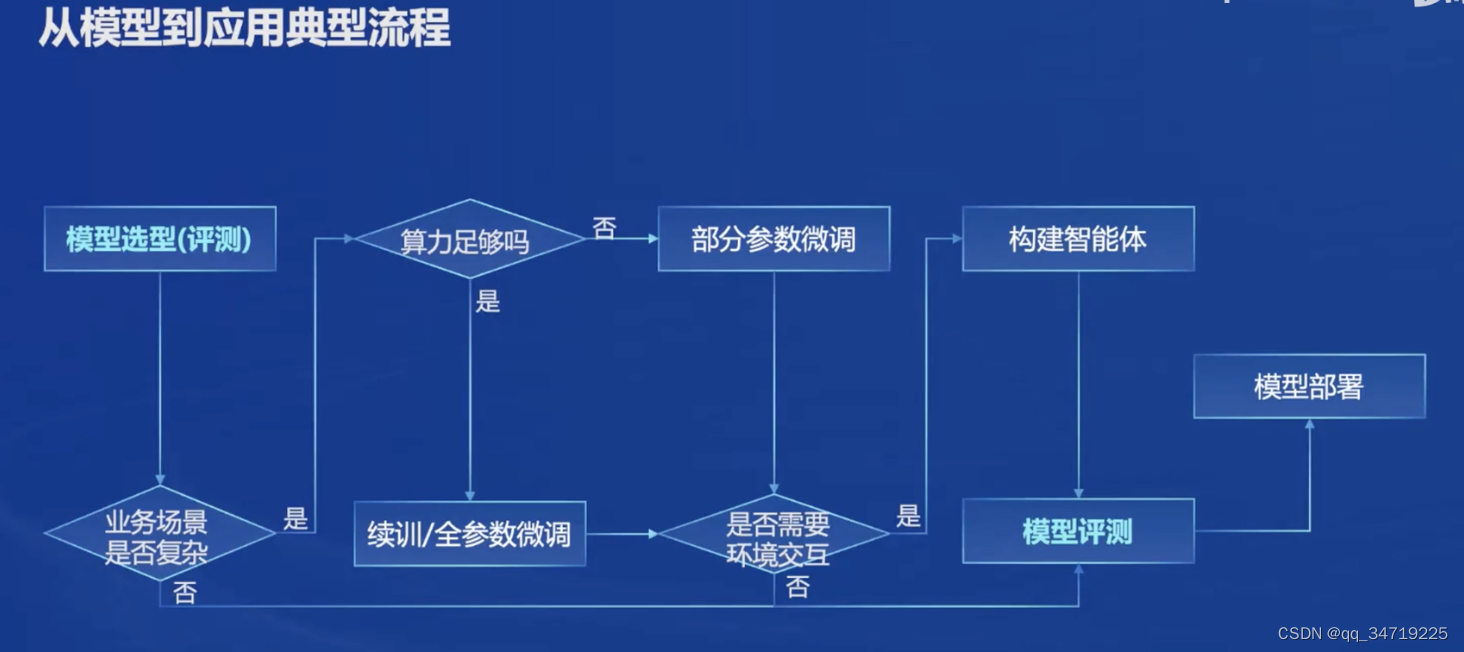
书生·浦语大模型全链路开源体系开源了包括数据(包括了2TB的数据,涵盖多种模态和任务)、预训练(开源了internLM - train一个预训练框架)、微调(X tuner框架,支持全参微调和LoRA等低成本微调)、部署(LMDeploy)、评测(opencompass等工具)和应用(支持多种智能体)等全链条环节,以及开源工具的功能和优势。
1、开源数据集

2、预训练

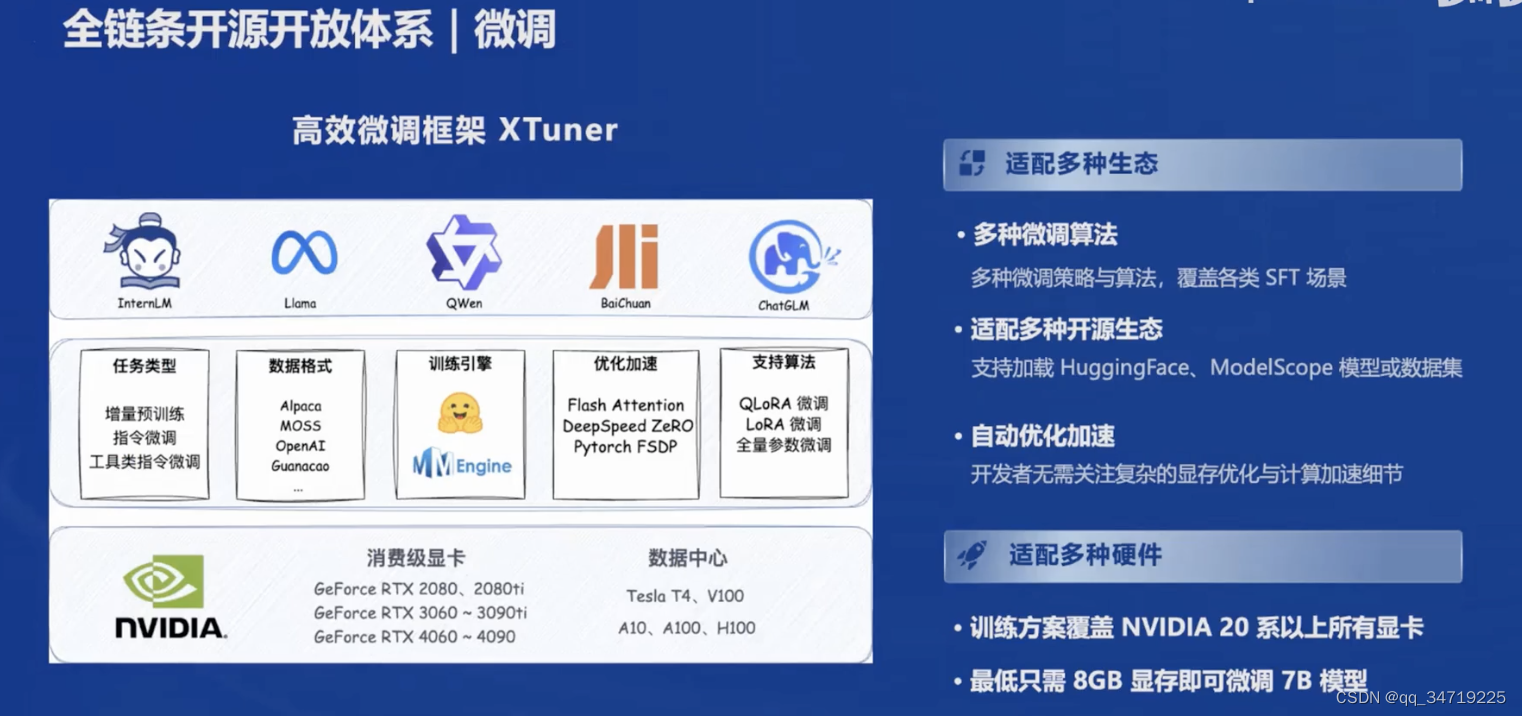
3、微调

4、评测
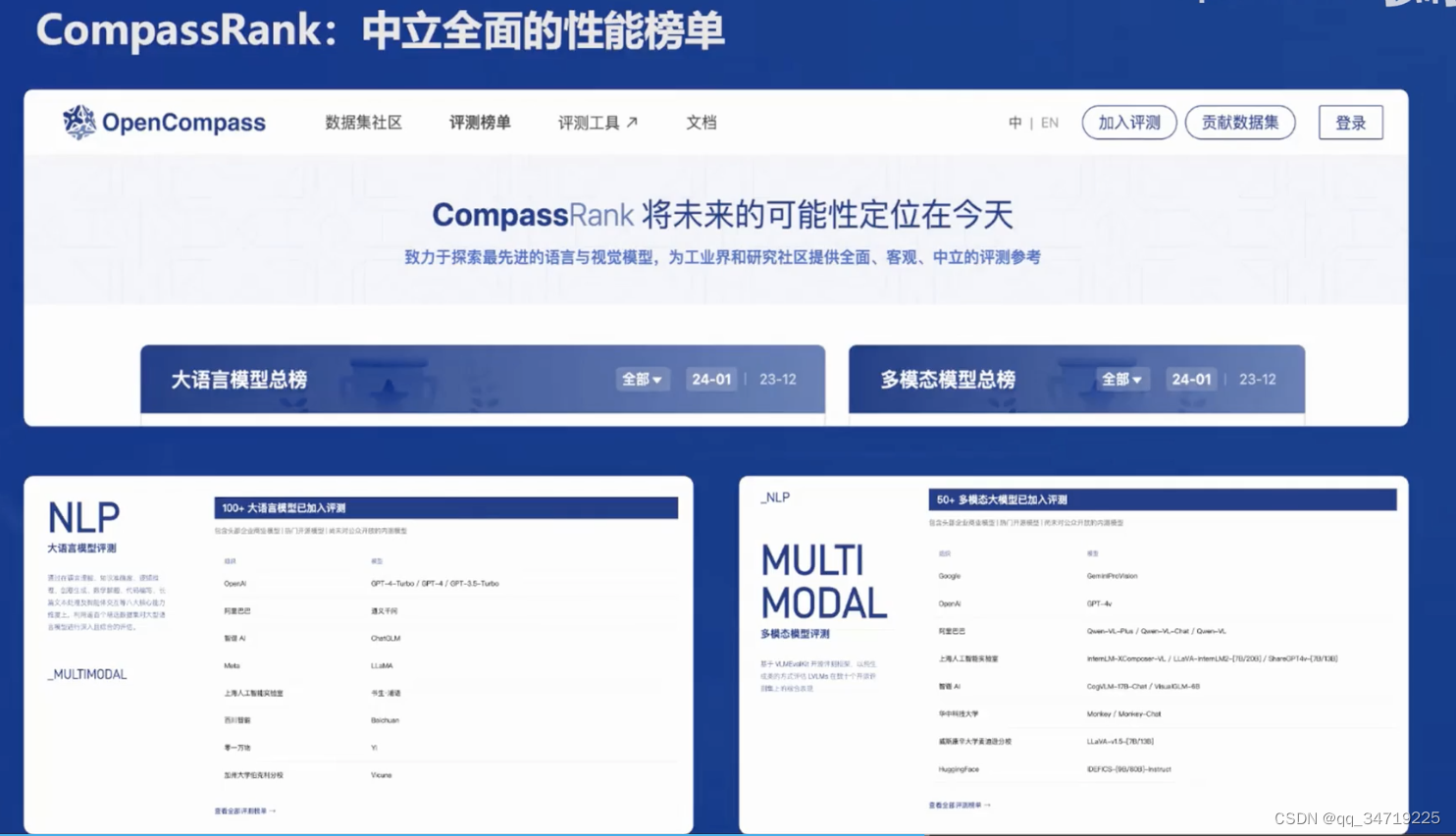
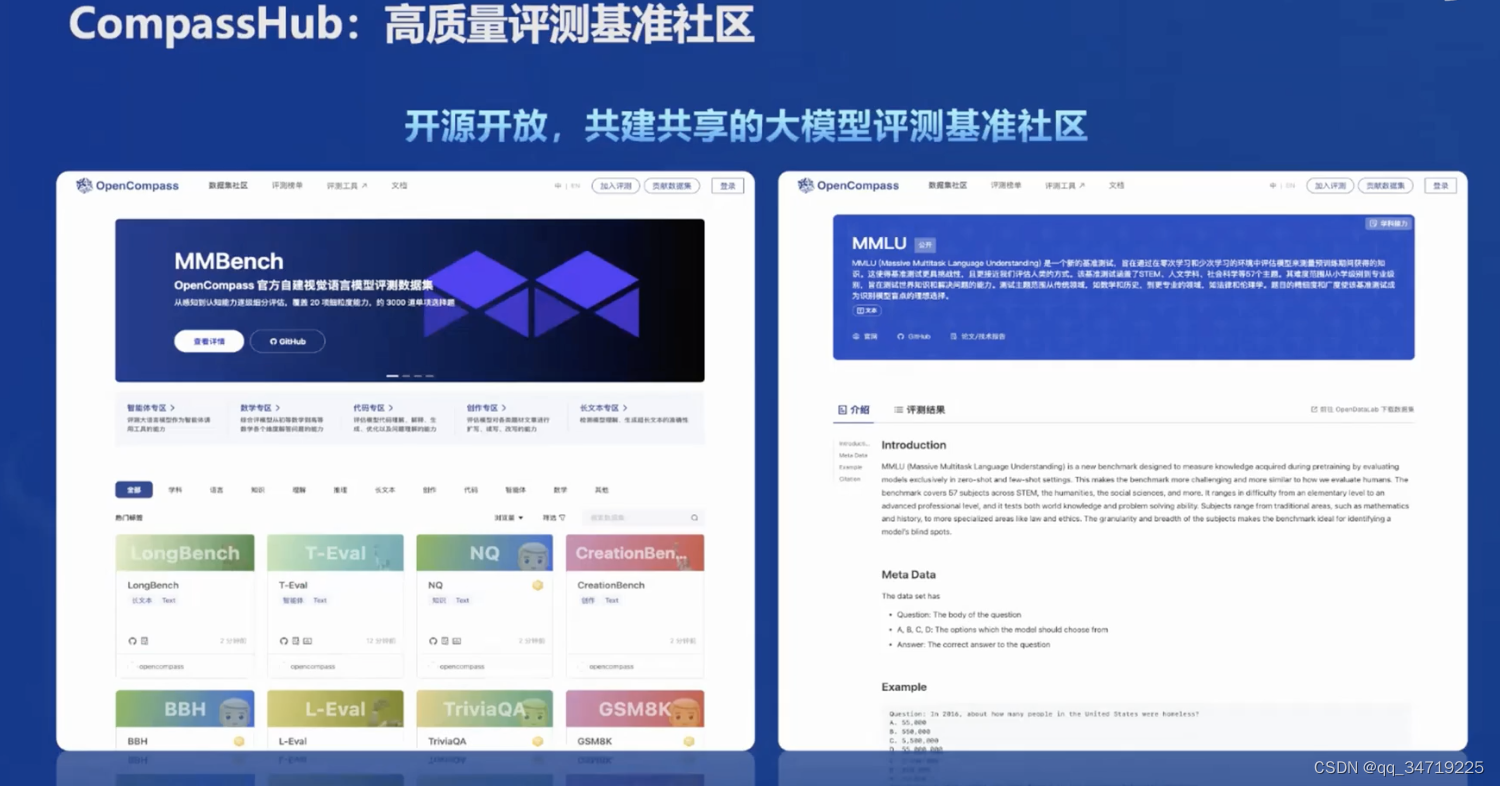
在评测方面,开发了OpenCompass评测框架,包含80 套评测集,40 万道题目。OpenCompass可以对模型在多个任务和数据集上的表现进行全面评估,从而了解模型的优势和局限性。
5、部署
大语言模型的特点是内存开销巨大,动态Shape。
存在的挑战有:
低存储设备(消费级显卡、移动端等)如何部署?
在推理的过程中:
如何加速 token 的生成速度?
如何解决动态shape,让推理可以不间断?
如何有效管理和利用内存?
在服务中:
如何提升系统整体吞吐量?
如何降低请求的平均响应时间?
针对以上问题,LMDeploy提供了一个在 GPU 上部署的全流程解决方案,包括模型的轻量化、推理和服务。

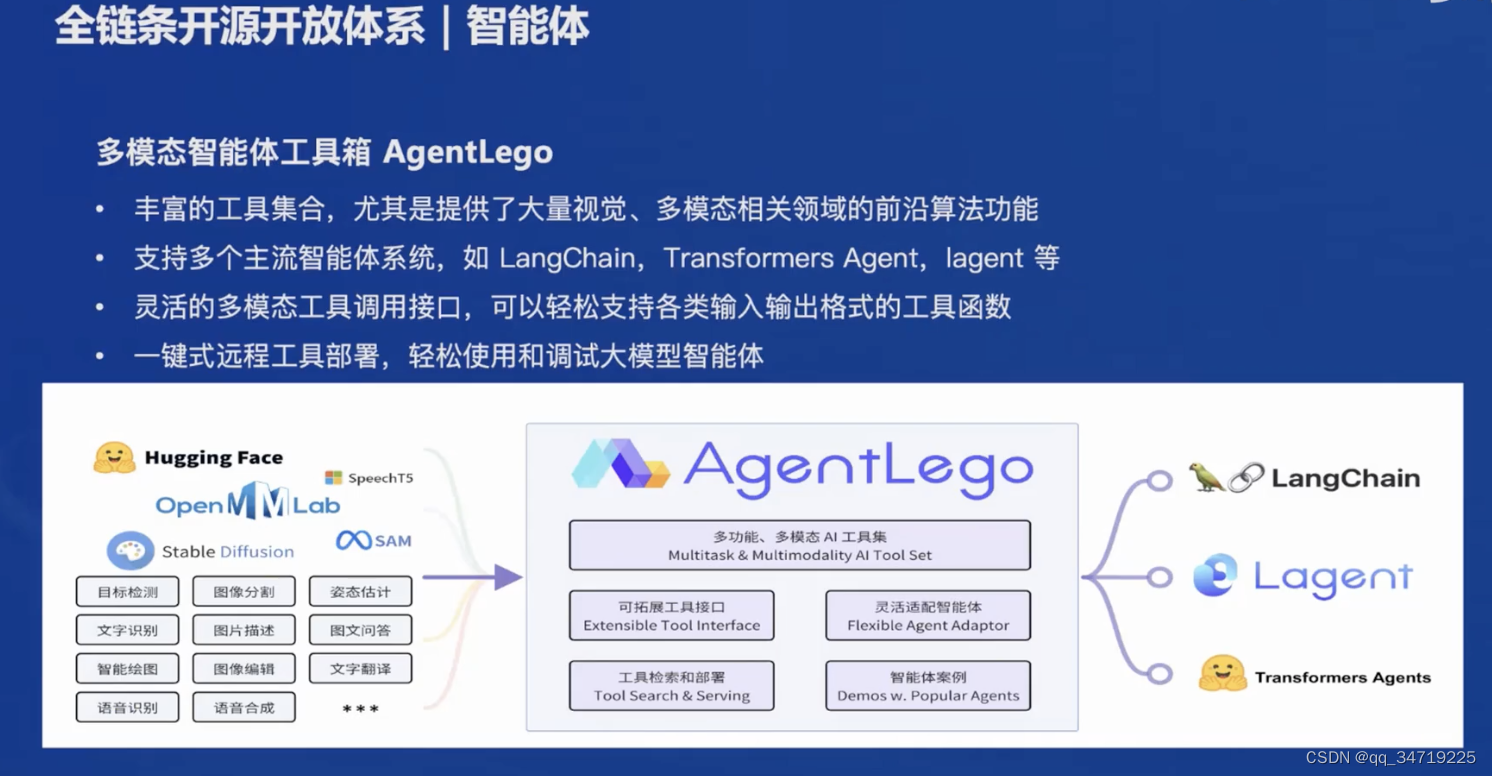
6、智能体(Agent)
在LLM语境下,Agent可以理解为在某种能自主理解、规划决策、执行复杂任务的智能体。

五、总结
ok,以上就是书生·浦语大模型全链路开源体系的全部内容了,也感谢视频老师的耐心讲解,对入门大语言模型有很好的帮助。















 1629
1629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









