







第一个MapReduce程序开发
前言
上篇博文已经搭建完成了Hadoop的开发环境,后面我们就需要专注于MapReduce的开发了。本文介绍如何利用MapReduce进行单词个数统计的代码实现,完整介绍一个Job作业的开发流程。
一、Job作业体系结构
一次Job作业包括5个阶段,其中只有Map阶段和Reduce阶段是需要我们去编写逻辑代码的,其它阶段都是自动完成。
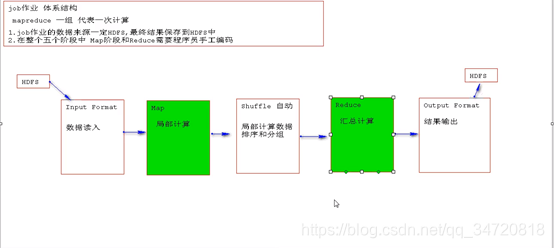
二、单词统计(WordCount)例子分析
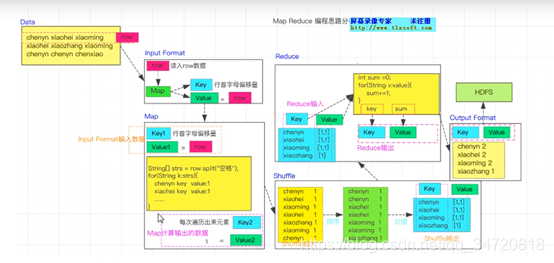
二、单词统计(WordCount)程序开发
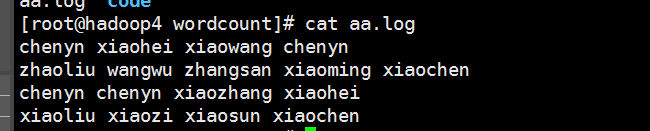
1、将数据上传至HDFS

aa.log的数据如下
2、创建Maven项目
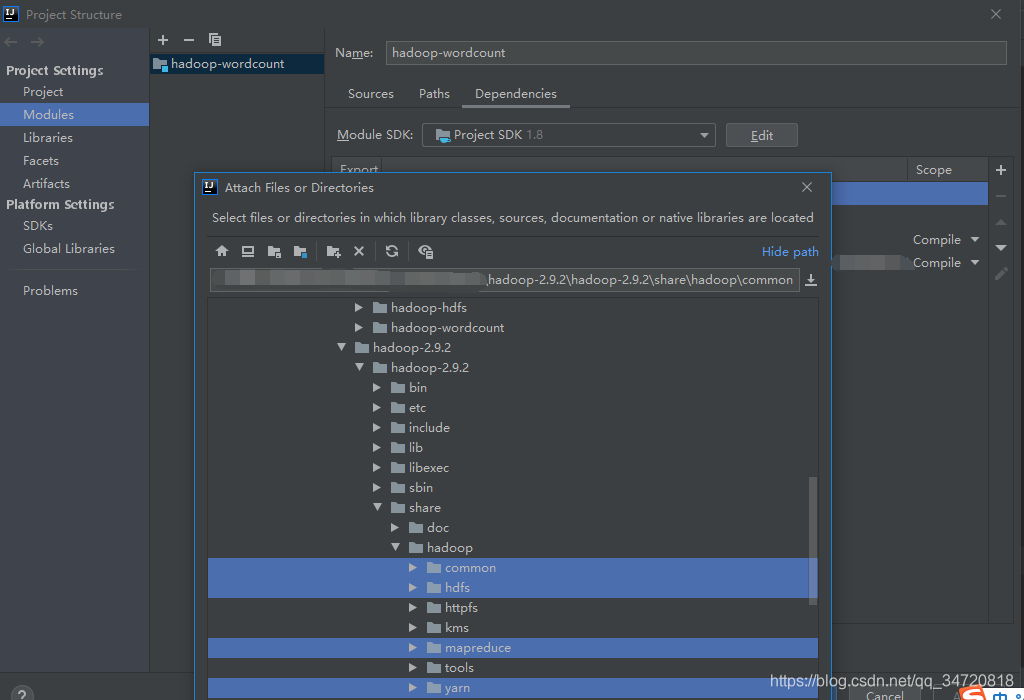
File->Project Structure->Modules添加hadoop安装包下share/hadoop/common;share/hadoop/dfdf;share/hadoop/mapreduce;share/hadoop/yarn目录下的Jar包
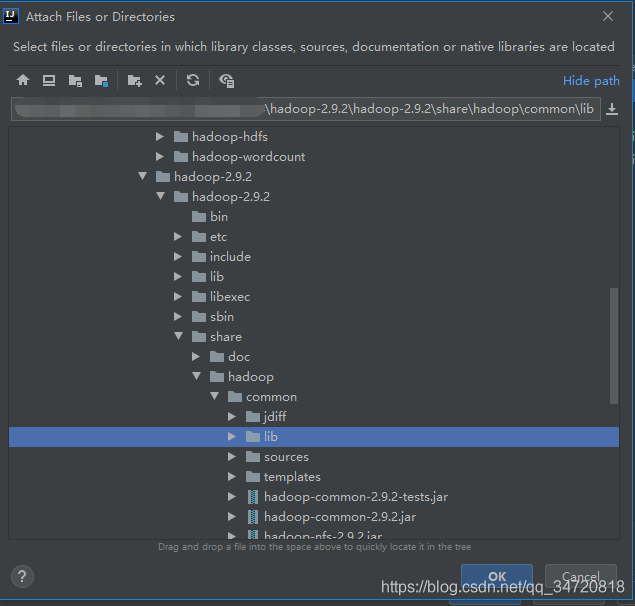
添加hadoop安装包下share/hadoop/common/lib下的Jar包
3、编写Job工作代码
package com.sun.wordcount;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
//测试数据
/*
chenyn xiaohei xiaowang chenyn
zhaoliu wangwu zhangsan xiaoming xiaochen
chenyn chenyn xiaozhang xiaohei
xiaoliu xiaozi xiaosun xiaochen
*/
public class WordCountJob extends Configured implements Tool {
//生成这个方法的快捷键(psvm)
public static void main(String[] args) throws Exception {
//执行Job作业的对象是谁
ToolRunner.run(new WordCountJob(),args);
}
//查找待实现方法快捷键(Ctrl+i)
//执行Job作业
public int run(String[] strings) throws Exception {
//创建Job作业
Job job = Job.getInstance(getConf());
job.setJarByClass(WordCountJob.class);
//1、设置inputFormat
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("/wordcount/aa.log"));
//2、设置map
job.setMapperClass(WordCountMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//3、设置shuffle 自动处理
//4、设置reduce
job.setReducerClass(WordCountReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//5、设置output format
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("/wordcount/result"));//必须保证output farmat输出结果的目录不存在(这个机制是为了防止丢失你的数据)
//6、提交Job作业
//job.submit();//这种方式没有返回状态
boolean status = job.waitForCompletion(true);//这种方式可以返回执行状态
System.out.println("word count status = " + status);//生成快捷键(soutv)
return 0;
}
//map阶段 (部分计算)
// hadoop包装了基本类型
// int->intWritable Long->LongWritable
// Double->DoubleWritable
// Float->FloatWritable String->Text
//泛型1:keyin inputFormat中的输出key类型 泛型2:valuein inputFormat中的输出value类型
//泛型3:keyout map阶段中的输出key类型 泛型2:valueout map阶段中的输出value类型
public static class WordCountMap extends Mapper<LongWritable, Text,Text,IntWritable>{
//input format 输出一次,调用一次map方法;
// 参数key是本次input format输出这行数据的行首偏移量
// 参数value是当前input format输出的这行值
@Override //打开重写方法的快捷键(Ctrl+o)
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//多读取的行数据进行切分
String[] words = value.toString().split(" ");
for (String s : words) {
context.write(new Text(s),new IntWritable(1));
}
}
}
//reduce阶段(汇总计算)
public static class WordCountReduce extends Reducer<Text, IntWritable,Text,IntWritable>
{
//所有map执行完,执行Reduce阶段
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable value : values) {
sum+=value.get();
}
//输出结果
context.write(key,new IntWritable(sum));
}
}
}
4、Pacakge打包Job工作代码
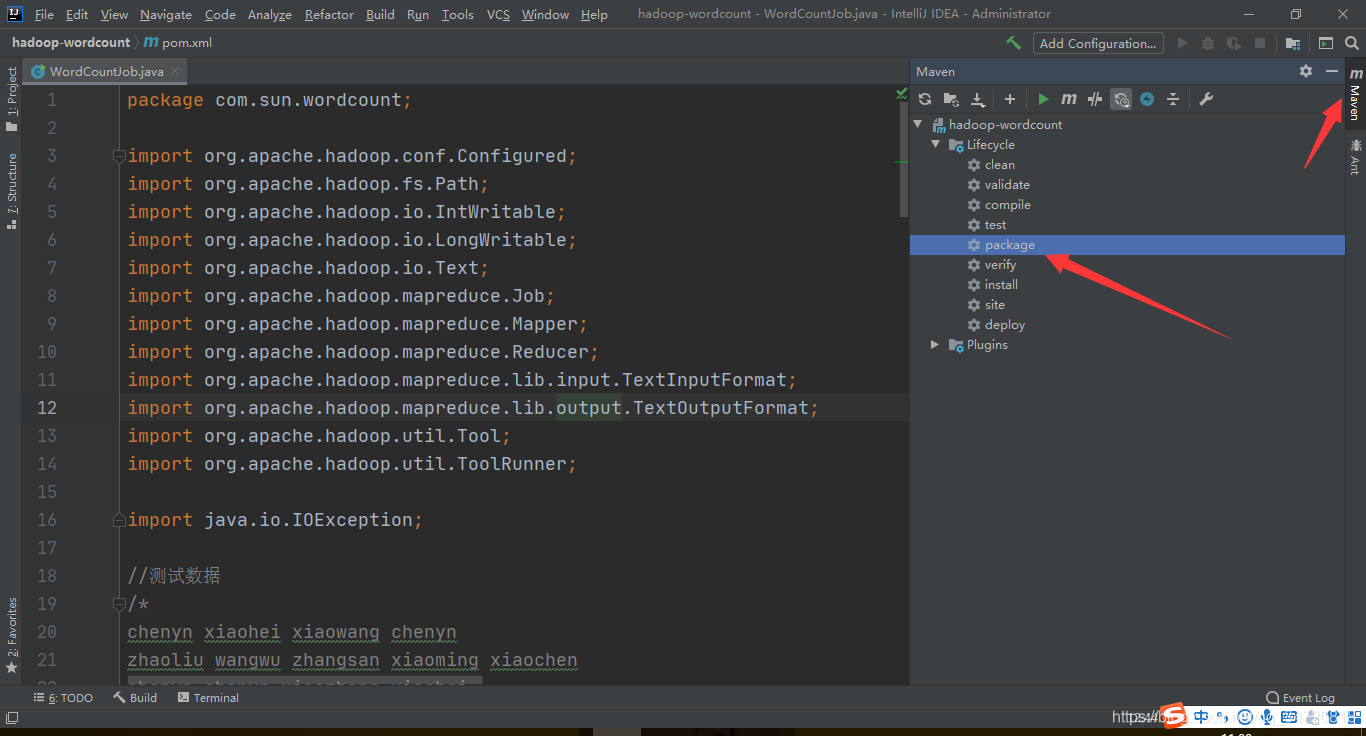
生成Jar包
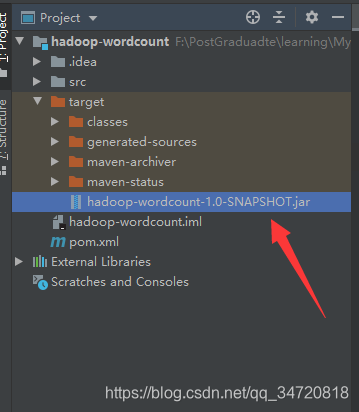
5、将Pacakge打包的Jar包放到lunix系统中执行
yarn jar hadoop-wordcount-1.0-SNAPSHOT.jar com.sun.wordcount.WordCountJob
shell执行过程
[root@hadoop4 code]# yarn jar hadoop-wordcount-1.0-SNAPSHOT.jar com.sun.wordcount.WordCountJob
20/06/26 11:03:58 INFO client.RMProxy: Connecting to ResourceManager at hadoop4/192.168.23.134:8032
20/06/26 11:04:05 INFO input.FileInputFormat: Total input files to process : 1
20/06/26 11:04:06 INFO mapreduce.JobSubmitter: number of splits:1
20/06/26 11:04:06 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
20/06/26 11:04:07 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1593138102465_0001
20/06/26 11:04:08 INFO impl.YarnClientImpl: Submitted application application_1593138102465_0001
20/06/26 11:04:08 INFO mapreduce.Job: The url to track the job: http://hadoop4:8088/proxy/application_1593138102465_0001/
20/06/26 11:04:08 INFO mapreduce.Job: Running job: job_1593138102465_0001
20/06/26 11:04:42 INFO mapreduce.Job: Job job_1593138102465_0001 running in uber mode : false
20/06/26 11:04:42 INFO mapreduce.Job: map 0% reduce 0%
20/06/26 11:05:08 INFO mapreduce.Job: map 100% reduce 0%
20/06/26 11:05:40 INFO mapreduce.Job: map 100% reduce 100%
20/06/26 11:05:42 INFO mapreduce.Job: Job job_1593138102465_0001 completed successfully
20/06/26 11:05:42 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=245
FILE: Number of bytes written=398523
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=241
HDFS: Number of bytes written=123
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=22254
Total time spent by all reduces in occupied slots (ms)=21557
Total time spent by all map tasks (ms)=22254
Total time spent by all reduce tasks (ms)=21557
Total vcore-milliseconds taken by all map tasks=22254
Total vcore-milliseconds taken by all reduce tasks=21557
Total megabyte-milliseconds taken by all map tasks=22788096
Total megabyte-milliseconds taken by all reduce tasks=22074368
Map-Reduce Framework
Map input records=4
Map output records=17
Map output bytes=205
Map output materialized bytes=245
Input split bytes=101
Combine input records=0
Combine output records=0
Reduce input groups=12
Reduce shuffle bytes=245
Reduce input records=17
Reduce output records=12
Spilled Records=34
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=425
CPU time spent (ms)=2330
Physical memory (bytes) snapshot=314445824
Virtual memory (bytes) snapshot=4174807040
Total committed heap usage (bytes)=137498624
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=140
File Output Format Counters
Bytes Written=123
word count status = true
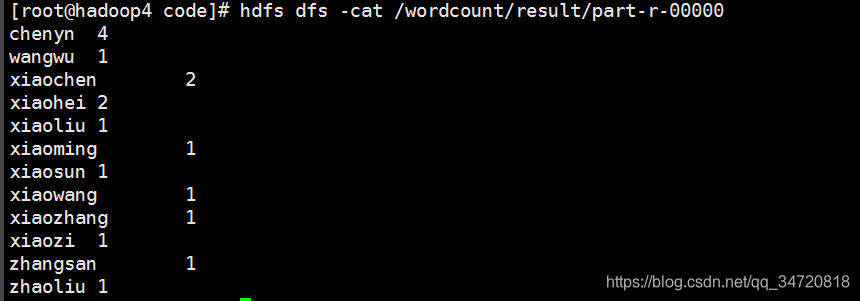
part-r-00000文件就是计算结果
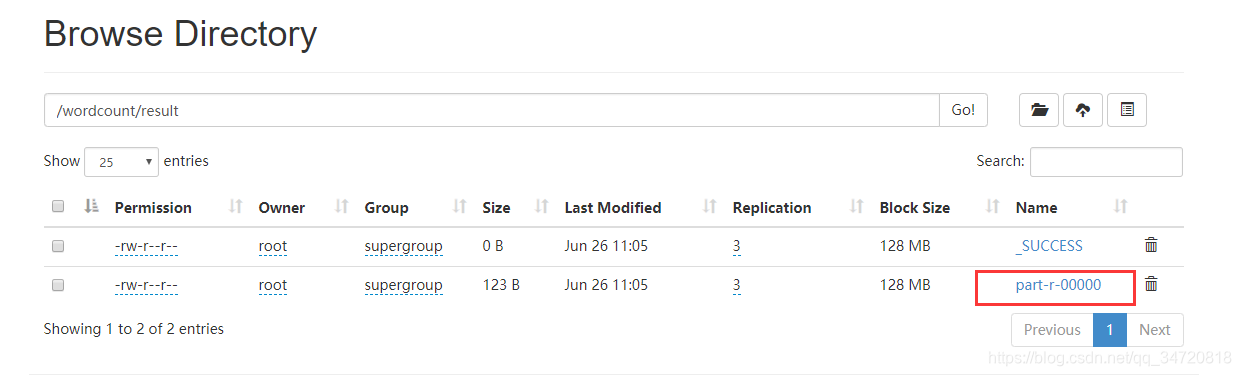
查看计算结果















 3262
3262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











