







深度学习笔记1(卷积神经网络)
在看完了UFLDL教程之后,决定趁热打铁,继续深度学习的学习,主要想讲点卷积神经网络,卷积神经网络是深度学习的模型之一,还有其它如AutoEncoding、Deep Belief Network、Restricted Boltzmann Machine和sparse coding等。
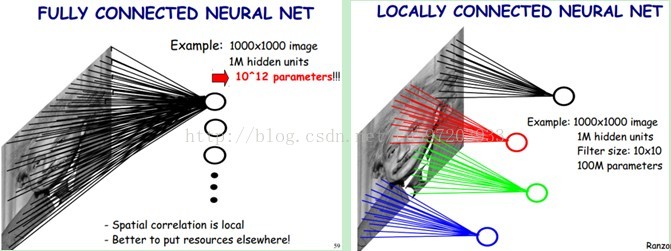
在UFLDL教程中提到了针对大型图像的处理,使用卷积和池化的概念。原因主要对于全连接网络,需要的参数就有很多。比如对于一副1000*1000的图像,hidden layer也为1000000个神经元,那么需要学习的参数就是10^12,这样从计算的角度来说,将会变得非常耗时;此外全连接,将会忽略掉图像内部的拓扑结构。因此我们采用部分连接网络,这就是卷积神经网络的要点之一—局部感受野,卷积神经网络还有两个卖点,就是权值共享和时空亚采样。
局部感受野
每个隐含单元仅仅只能连接输入单元的一部分。例如,每个隐含单元仅仅连接输入图像的一小片相邻区域。比如我们每个隐含单元只与10*10的区域相连接,那么我们参数的个数就变为了10^8,降低了10000倍,这样训练起来就没有那么费力了。这一思想主要受启发于生物学里面的视觉系统结构。视觉皮层的神经元就是局部接受信息的(即这些神经元只响应某些特定区域的刺激),此外图像的像素也是局部时空相关的。
如下图所示,左边就是全连接网络,每个隐藏神经元与每个像素进行连接。右边就是部分连接网络,每个隐神经元只与一部分区域相连接。
权值共享
部分连接以后,参数降低了很多,但是感觉参数还是有很多,怎么办呢?我们进行权值共享,权值共享的意思是每个隐神经元连接的100个参数都是相同,那么训练参数就降低到10*10=100个了。参数真的是极大的简化了啊!这个思想主要来源于:自然图像有其固有特性,也就是说,图像的一部分的统计特性与其他部分是一样的。这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征。
如果隐神经元与其连接的100个输入单元具有相同的100个参数,那么就相当于是一个10*10的模板在原始的输入图像上做卷积(当然需要加上一个偏置参数b),这样相当于得到一个新的图像,新图像的大小为(1000-100+1)*(1000-100+1),因此也得名卷积神经网络。这样的10*10的模板,我们也把它称为一个卷积核。此外只用一个卷积核提取得到的特征往往是不充分的,只能算作是一种类型的特征(比如某个方向的边缘),如果我们要提取其它方向的边缘,那就多弄几个卷积核呗,这样就变成了多卷积核了。假设有k个卷积核,那么可训练的参数的个数就变为了k*10*10。注意没有包含偏置参数。每个卷积核得到一副特征图像也被称为一个Feature Map。
卷积的过程也被称为特征提取的过程,通常该层用Cx来标记,其中C是convolution的意思,x表示是第几层。
时空亚采样
降低图像的分辨率,可以减少输出对于变形和扭曲的敏感性。此外,在通过卷积获得了特征 (features) 之后,下一步我们希望利用这些特征去做分类。理论上讲,人们可以用所有提取得到的特征去训练分类器,例如 softmax 分类器,但这样做面临计算量的挑战。例如:对于一个 96X96 像素的图像,假设我们已经学习得到了400个定义在8X8输入上的特征,每一个特征和图像卷积都会得到一个 (96 − 8 + 1) * (96 − 8 + 1) = 7921 维的卷积特征,由于有 400 个特征,所以每个样例(example) 都会得到一个 892 * 400 = 3,168,400 维的卷积特征向量。学习一个拥有超过 3 百万特征输入的分类器十分不便,并且容易出现过拟合 (over-fitting)。
为了解决这个问题,首先回忆一下,我们之所以决定使用卷积后的特征是因为图像具有一种“静态性”的属性,这也就意味着在一个图像区域有用的特征极有可能在另一个区域同样适用。因此,为了描述大的图像,一个很自然的想法就是对不同位置的特征进行聚合统计,例如,人们可以计算图像一个区域上的某个特定特征的平均值 (或最大值)。这些概要统计特征不仅具有低得多的维度 (相比使用所有提取得到的特征),同时还会改善结果(不容易过拟合)。这种聚合的操作就叫做池化 (pooling),有时也称为平均池化或者最大池化 (取决于计算池化的方法)。
池化的过程通常也被称为特征映射的过程,通常该层用Sx表示,S就是sumsampling的意思,x表示第几层。
多层卷积网络—典型的例子
下面我们用一个典型的数字识别系统LeNet-5来讲解挫等卷积网络。以下是其leNet-5多层网络的示意图,总共包含了7层,不包含输入层。
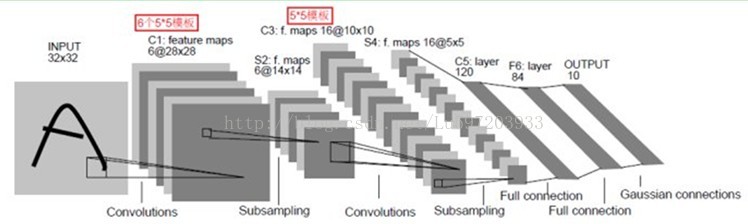
输入原始图像的大小是32*32,卷积层用Cx表示,亚采样层用Sx表示,全连接层用Fx表示,x表示第x层。
C1层是卷积层,用了6个卷积核,这样就得到了6个feature map,其中每个卷积核的大小为5*5,用每个卷积核与原始的输入图像进行卷积,这样feature map的大小为(32-5+1)* (32-5+1)= 28*28,所需要的参数的个数为(5*5+1)*6= 156(其中5*5为卷积模板参数,1为偏置参数),连接数为(5*5+1)*28*28*6=122304(其中28*28为卷积后图像的大小)。
S2层为采样层,也可以说是池化或者特征映射的过程,拥有6个feature maps,每个feature map的大小为14*14,每个feature map的隐单元与上一层C1相对应的feature map的2*2单元相连接,这里没有重叠。计算过程是:2*2单元里的值相加然后再乘以训练参数w,再加上一个偏置参数b(每一个feature map共享相同w和b),然后取sigmoid值,作为对应的该单元的值。所以S2层中每个featuremap的长宽都是上一层C1的一半。S2层需要2*6=12个参数,连接数为(4+1)*14*14*6 = 5880.【这里池化的过程与ufldl教程中略有不同。】
C3层也是一个卷积层,有16个卷积核,卷积模板的大小为5*5,因此具有16个feature maps,每个featuremap的大小为(14-5+1)*(14-5+1)= 10*10。每个feature map只与上一层S2中部分feature maps相连接,下表给出了16个feature maps与上一层S2的连接方式(行为S2层feature map的标号,列为C3层feature map的标号,第一列表示C3层的第0个feature map只有S2层的第0、1和2这三个feature maps相连接,其它解释类似)。为什么要采用部分连接,而不采用全连接呢?首先就是部分连接,可计算的参数就会比较少,其次更重要的是它能打破对称性,这样就能得到输入的不同特征集合。以第0个feature map描述计算过程:用1个卷积核(对应3个卷积模板,但仍称为一个卷积核,可以认为是三维卷积核)分别与S2层的3个feature maps进行卷积,然后将卷积的结果相加,再加上一个偏置,再取sigmoid就可以得出对应的feature map了。所需要的参数数目为(5*5*3+1)*6 +( 5*5*4+1)*9 +5*5*6+1 = 1516(5*5为卷积参数,该卷积核有3个卷积模板),连接数为1516*10*10= 151600(98论文年论文给出的结果是156000,个人认为这是错误的,因为一个卷积核只有一个偏置参数)。

同理,S4层也是采样层,有16个feature maps,每个featuremap的大小为5*5,计算过程和S2类似,需要参数个数为16*2 = 32个,连接数为(4+1)*5*5*16 = 2000.
C5为卷积层,有120个卷积核,卷积核的大小仍然为5*5,因此有120个feature maps,
每个feature map的大小都与上一层S4的所有feature maps进行连接,这样一个卷积核就有16个卷积模板。Feature map的大小为1*1,这样刚好变成了全连接,但是我们不把它写成F5,因为这只是巧合。C5层有120*(5*5*16+1) = 48120(16为上一层所有的feature maps个数)参数,连接数也是这么多。
F6层有86个神经单元,每个神经单元与C5进行全连接。它的连接数和参数均为86*120= 10164。这样F6层就可以得到一个86维特征了。后面可以使用该86维特征进行做分类预测等内容了。
大体的多层神经网络卷积和采样的过程基本讲完。如有问题欢迎留言交流!注意:这里卷积和池化的计算过程和ufldl教程中的计算略有不同。
参考文献
1:UFLDL教程:http://deeplearning.stanford.edu/wiki/index.php/UFLDL_Tutorial
2:1998年论文:Gradient-BasedLearning Applied to Document Recognition
3:http://blog.csdn.net/stdcoutzyx/article/details/41596663卷积神经网络
4:http://blog.csdn.net/zouxy09/article/details/8781543 Deep Learning(深度学习)学习笔记整理系列之(七)
本文转载自卷积神经网络














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









