






 文章使用Python的Pandas库进行数据处理,通过for循环实现数据框的不重复排列组合。首先读取CSV文件,然后选取特定行并进行拼接,利用pd.concat去除重复行。文中也引入了其他库,如Numpy、Scipy和Sklearn,但主要关注点在于数据框的组合操作。
文章使用Python的Pandas库进行数据处理,通过for循环实现数据框的不重复排列组合。首先读取CSV文件,然后选取特定行并进行拼接,利用pd.concat去除重复行。文中也引入了其他库,如Numpy、Scipy和Sklearn,但主要关注点在于数据框的组合操作。
1、需要实现不重复的排列组合,例如C100^2,100个行中取出两行
2、数据框的拼接
import pandas as pd
import numpy as np
import math
from scipy.stats import ttest_1samp
from sklearn.model_selection import train_test_split
from scipy.optimize import leastsq##引入最小二乘法算法
from sklearn import metrics
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
import os
from itertools import combinations
import itertools
path=r"F:\***\***\***"
pathDir = os.listdir(path)
for f in pathDir:
#data1 = pd.read_csv(os.path.join(path, f))
#data = data1.replace(0, 0.00001)
data2 = pd.read_csv(os.path.join(path, f))#获取路径文件
print(data2)
for ii in range(0,len(data2)):#data[0:1]
df1 = data2
df2 = data2[ii:ii+1]#取出第一列
for jj in range(ii+1, len(data2)):
df3 = data2[jj:jj + 1]#取出第二列
df4= pd.concat([df2,df3])#组合两列
set_diff_df = pd.concat([df4,df1]).drop_duplicates(keep=False) # 实现去除相同的列
print(set_diff_df)
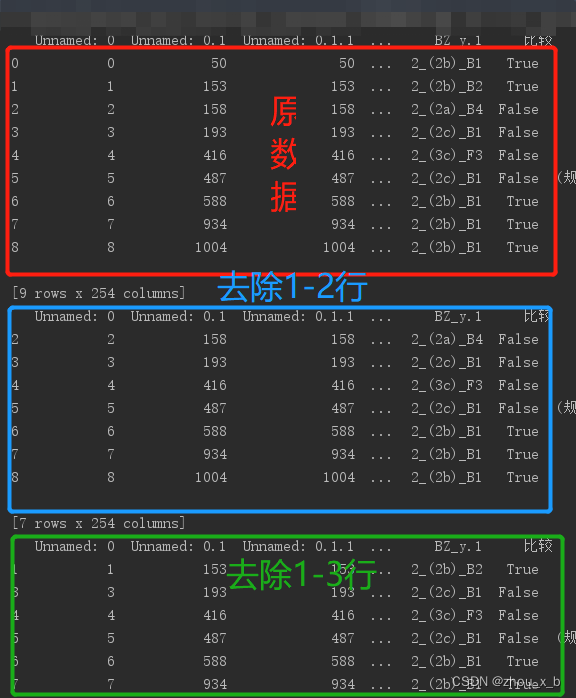
结果如图,依次类推,通常用combinations()实现排列组合,但是数据框的操作难以实现,直接通过for循环即可。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









