






1. 课程目标
1.1. 掌握Spark Streaming的原理
1.2. 熟练使用Spark Streaming完成流式计算任务
2. Spark Streaming介绍
2.1. Spark Streaming概述
2.1.1. 什么是Spark Streaming

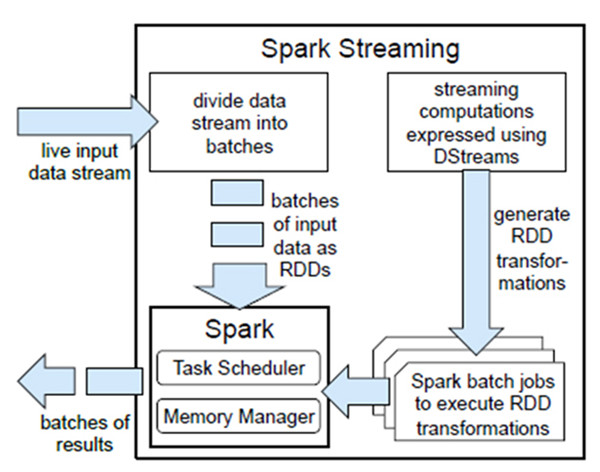
Spark Streaming类似于Apache Storm,用于流式数据的处理。根据其官方文档介绍,Spark Streaming有高吞吐量和容错能力强等特点。Spark Streaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。数据输入后可以用Spark的高度抽象原语如:map、reduce、join、window等进行运算。而结果也能保存在很多地方,如HDFS,数据库等。另外Spark Streaming也能和MLlib(机器学习)以及Graphx完美融合。
2.1.2. 为什么要学习Spark Streaming
1.易用
2.容错
3.易整合到Spark体系
2.1.3. Spark与Storm的对比
| Spark | Storm |
| | |
| 开发语言:Scala | 开发语言:Clojure |
| 编程模型:DStream | 编程模型:Spout/Bolt |
|
| |

3. DStream
3.1. 什么是DStream
Discretized Stream是Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark原语操作后的结果数据流。在内部实现上,DStream是一系列连续的RDD来表示。每个RDD含有一段时间间隔内的数据,如下图:

对数据的操作也是按照RDD为单位来进行的
计算过程由Spark engine来完成
3.2. DStream相关操作
DStream上的原语与RDD的类似,分为Transformations(转换)和Output Operations(输出)两种,此外转换操作中还有一些比较特殊的原语,如:updateStateByKey()、transform()以及各种Window相关的原语。
3.2.1. Transformations on DStreams
|
| |
| Transformation算子 | 用途 |
|---|---|
| map(func) | 返回会一个新的DStream,并将源DStream中每个元素通过func映射为新的元素 |
| flatMap(func) | 和map类似,不过每个输入元素不再是映射为一个输出,而是映射为0到多个输出 |
| filter(func) | 返回一个新的DStream,并包含源DStream中被func选中(func返回true)的元素 |
| repartition(numPartitions) | 更改DStream的并行度(增加或减少分区数) |
| union(otherStream) | 返回新的DStream,包含源DStream和otherDStream元素的并集 |
| count() | 返回一个包含单元素RDDs的DStream,其中每个元素是源DStream中各个RDD中的元素个数 |
| reduce(func) | 返回一个包含单元素RDDs的DStream,其中每个元素是通过源RDD中各个RDD的元素经func(func输入两个参数并返回一个同类型结果数据)聚合得到的结果。func必须满足结合律,以便支持并行计算。 |
| countByValue() | 如果源DStream包含的元素类型为K,那么该算子返回新的DStream包含元素为(K, Long)键值对,其中K为源DStream各个元素,而Long为该元素出现的次数。 |
| reduceByKey(func, [numTasks]) | 如果源DStream 包含的元素为 (K, V) 键值对,则该算子返回一个新的也包含(K, V)键值对的DStream,其中V是由func聚合得到的。注意:默认情况下,该算子使用Spark的默认并发任务数(本地模式为2,集群模式下由spark.default.parallelism 决定)。你可以通过可选参数numTasks来指定并发任务个数。 |
| join(otherStream, [numTasks]) | 如果源DStream包含元素为(K, V),同时otherDStream包含元素为(K, W)键值对,则该算子返回一个新的DStream,其中源DStream和otherDStream中每个K都对应一个 (K, (V, W))键值对元素。 |
| cogroup(otherStream, [numTasks]) | 如果源DStream包含元素为(K, V),同时otherDStream包含元素为(K, W)键值对,则该算子返回一个新的DStream,其中每个元素类型为包含(K, Seq[V], Seq[W])的tuple。 |
| transform(func) | 返回一个新的DStream,其包含的RDD为源RDD经过func操作后得到的结果。利用该算子可以对DStream施加任意的操作。 |
| updateStateByKey(func) | 返回一个包含新”状态”的DStream。源DStream中每个key及其对应的values会作为func的输入,而func可以用于对每个key的“状态”数据作任意的更新操作。 |
特殊的Transformations
1.UpdateStateByKey Operation
UpdateStateByKey原语用于记录历史记录,上文中Word Count示例中就用到了该特性。若不用UpdateStateByKey来更新状态,那么每次数据进来后分析完成后,结果输出后将不在保存
2.Transform Operation
Transform原语允许DStream上执行任意的RDD-to-RDD函数。通过该函数可以方便的扩展Spark API。此外,MLlib(机器学习)以及Graphx也是通过本函数来进行结合的。
3.Window Operations
Window Operations有点类似于Storm中的State,可以设置窗口的大小和滑动窗口的间隔来动态的获取当前Steaming的允许状态
这里列出一些基于窗口计算的算子
| Transformation窗口算子 | 用途 |
|---|---|
| window(windowLength, slideInterval) | 将源DStream窗口化,并返回转化后的DStream |
| countByWindow(windowLength,slideInterval) | 返回数据流在一个滑动窗口内的元素个数 |
| reduceByWindow(func, windowLength,slideInterval) | 基于数据流在一个滑动窗口内的元素,用func做聚合,返回一个单元素数据流。func必须满足结合律,以便支持并行计算。 |
| reduceByKeyAndWindow(func,windowLength, slideInterval, [numTasks]) | 基于(K, V)键值对DStream,将一个滑动窗口内的数据进行聚合,返回一个新的包含(K,V)键值对的DStream,其中每个value都是各个key经过func聚合后的结果。 注意:如果不指定numTasks,其值将使用Spark的默认并行任务数(本地模式下为2,集群模式下由 spark.default.parallelism决定)。当然,你也可以通过numTasks来指定任务个数。 |
| reduceByKeyAndWindow(func, invFunc,windowLength,slideInterval, [numTasks]) | 和前面的reduceByKeyAndWindow() 类似,只是这个版本会用之前滑动窗口计算结果,递增地计算每个窗口的归约结果。当新的数据进入窗口时,这些values会被输入func做归约计算,而这些数据离开窗口时,对应的这些values又会被输入 invFunc 做”反归约”计算。举个简单的例子,就是把新进入窗口数据中各个单词个数“增加”到各个单词统计结果上,同时把离开窗口数据中各个单词的统计个数从相应的统计结果中“减掉”。不过,你的自己定义好”反归约”函数,即:该算子不仅有归约函数(见参数func),还得有一个对应的”反归约”函数(见参数中的 invFunc)。和前面的reduceByKeyAndWindow() 类似,该算子也有一个可选参数numTasks来指定并行任务数。注意,这个算子需要配置好检查点(checkpointing)才能用。 |
| countByValueAndWindow(windowLength,slideInterval, [numTasks]) | 基于包含(K, V)键值对的DStream,返回新的包含(K, Long)键值对的DStream。其中的Long value都是滑动窗口内key出现次数的计数。 和前面的reduceByKeyAndWindow() 类似,该算子也有一个可选参数numTasks来指定并行任务数。 |
3.2.2. Output Operations on DStreams
Output Operations可以将DStream的数据输出到外部的数据库或文件系统,当某个Output Operations原语被调用时(与RDD的Action相同),streaming程序才会开始真正的计
| 输出算子 | 用途 |
|---|---|
| print() | 在驱动器(driver)节点上打印DStream每个批次中的头十个元素。 Python API 对应的Python API为 pprint() |
| saveAsTextFiles(prefix, [suffix]) | 将DStream的内容保存到文本文件。 每个批次一个文件,各文件命名规则为 “prefix-TIME_IN_MS[.suffix]” |
| saveAsObjectFiles(prefix, [suffix]) | 将DStream内容以序列化Java对象的形式保存到顺序文件中。 每个批次一个文件,各文件命名规则为 “prefix-TIME_IN_MS[.suffix]”Python API 暂不支持Python |
| saveAsHadoopFiles(prefix, [suffix]) | 将DStream内容保存到Hadoop文件中。 每个批次一个文件,各文件命名规则为 “prefix-TIME_IN_MS[.suffix]”Python API 暂不支持Python |
| foreachRDD(func) | 这是最通用的输出算子了,该算子接收一个函数func,func将作用于DStream的每个RDD上。 func应该实现将每个RDD的数据推到外部系统中,比如:保存到文件或者写到数据库中。 注意,func函数是在streaming应用的驱动器进程中执行的,所以如果其中包含RDD的action算子,就会触发对DStream中RDDs的实际计算过程。 |
4. 实战
4.1. 用Spark Streaming实现实时WordCount
架构图:
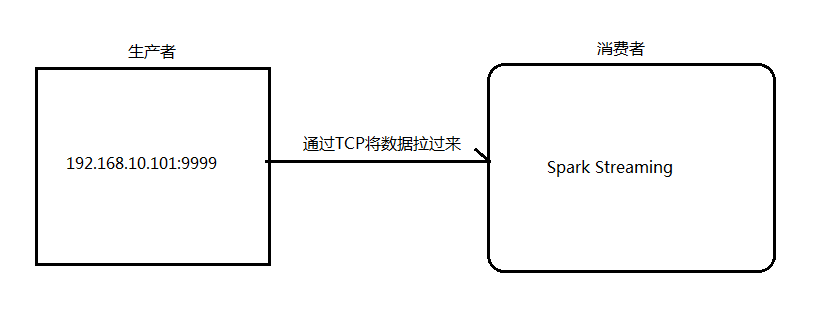
1.安装并启动生成者
首先在一台Linux(ip:192.168.10.101())上用YUM安装nc工具
yum install -y nc
启动一个服务端并监听9999端口
nc -lk 9999
2.编写Spark Streaming程序
| package org.spark.streaming |
3.启动Spark Streaming程序:由于使用的是本地模式"local[2]"所以可以直接在本地运行该程序
注意:要指定并行度,如在本地运行设置setMaster("local[2]"),相当于启动两个线程,一个给receiver,一个给computer。如果是在集群中运行,必须要求集群中可用core数大于1

4.在Linux端命令行中输入单词
#nc -lk 9999
hello tom hello jerry hello tom
5.在IDEA控制台中查看结果

问题:结果每次在Linux段输入的单词次数都被正确的统计出来,但是结果不能累加!如果需要累加需要使用updateStateByKey(func)来更新状态,下面给出一个例子:
| package cn.itcast.spark.streaming
|
4.2. Spark Streaming整合Kafka完成网站点击流实时统计
Apache Kafka是一个分布式的消息发布-订阅系统。可以说,在任何实时大数据处理工具缺少与Kafka整合都是不完善的。使用Spark Streaming从Kafka中接受数据,这里会介绍两种方法:(1)使用Receivers和Kafka高层次的API;(2)【spark2.0版本以后最常用】使用Direct API,这是使用低层次的Kafka API,并没有使用到Receivers
1.安装并配置zk
2.安装并配置Kafka
3.启动zk
4.启动Kafka
5.创建topic
bin/kafka-topics.sh --create --zookeeper node1.itcast.cn:2181,node2.itcast.cn:2181 \
--replication-factor 3 --partitions 3 --topic urlcount
6.编写基于Receivers的Spark Streaming应用程序
| package org.spark.streaming
defmain(args:Array[String]) { if(args.length < 4) { System.err.println("Usage: KafkaWordCount <zkQuorum> <group> <topics> <numThreads>") System.exit(1) } StreamingExamples.setStreamingLogLevels() //需要编写设置打印日志级别 valArray(zkQuorum, group, topics, numThreads) =args valsparkConf=newSparkConf().setAppName("KafkaWordCount") valssc= newStreamingContext(sparkConf, Seconds(2)) ssc.checkpoint("checkpoint") valtopicMap=topics.split(",").map((_,numThreads.toInt)).toMap vallines=KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2) valwords=lines.flatMap(_.split(" ")) valwordCounts=words.map(x=> (x, 1L)) .reduceByKeyAndWindow(_+_,_-_, Minutes(10), Seconds(2),2) wordCounts.print() ssc.start() ssc.awaitTermination() } } |
7.编写基于Direct API的Spark Streaming应用程序
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka010._
object DirectKafkaWordCount{
def main(args: Array[String]): Unit = {
if (args.length < 2) {
System.err.println(s"""
|Usage: DirectKafkaWordCount <brokers> <topics>
| <brokers> is a list of one or more Kafka brokers
| <topics> is a list of one or more kafka topics to consume from
|
""".stripMargin)
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
val Array(brokers, topics) = args
// Create context with 2 second batch interval
val sparkConf = new SparkConf().setAppName("DirectKafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
// Create direct kafka stream with brokers and topics
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, String]("metadata.broker.list" -> brokers)
val messages = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams))
// Get the lines, split them into words, count the words and print
val lines = messages.map(_.value)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.print()
// Start the computation
ssc.start()
ssc.awaitTermination()
}
}
8.Direct API方式与Receivers相比,有以下优点:
(1)、简化并行。我们不需要创建多个Kafka 输入流,然后union他们。而使用directStream,Spark Streaming将会创建和Kafka分区一样的RDD分区个数,而且会从Kafka并行地读取数据,也就是说Spark分区将会和Kafka分区有一一对应的关系,这对我们来说很容易理解和使用;
(2)、高效。第一种实现零数据丢失是通过将数据预先保存在WAL中,这将会复制一遍数据,这种方式实际上很不高效,因为这导致了数据被拷贝两次:一次是被Kafka复制;另一次是写到WAL中。但是本文介绍的方法因为没有Receiver,从而消除了这个问题,所以不需要WAL日志;
(3)、恰好一次语义(Exactly-once semantics)。Receivers方式通过使用Kafka高层次的API把偏移量写入Zookeeper中,这是读取Kafka中数据的传统方法。虽然这种方法可以保证零数据丢失,但是还是存在一些情况导致数据会丢失,因为在失败情况下通过Spark Streaming读取偏移量和Zookeeper中存储的偏移量可能不一致。而本文提到的方法是通过Kafka低层次的API,并没有使用到Zookeeper,偏移量仅仅被Spark Streaming保存在Checkpoint中。这就消除了Spark Streaming和Zookeeper中偏移量的不一致,而且可以保证每个记录仅仅被Spark Streaming读取一次,即使是出现故障。















 388
388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









