







Spark SQL and DataFrame、DataSet
1. 课程目标
1.1. 掌握Spark SQL的原理
1.2. 掌握DataFrame数据结构和使用方式
1.3. 熟练使用Spark SQL完成计算任务
2. Spark SQL
2.1. Spark SQL概述
2.1.1. 什么是Spark SQL

Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用。
2.1.2. 为什么要学习Spark SQL
我们已经学习了Hive,它是将Hive SQL转换成MapReduce然后提交到集群上执行,大大简化了编写MapReduce的程序的复杂性,由于MapReduce这种计算模型执行效率比较慢。所有Spark SQL的应运而生,它是将Spark SQL转换成RDD,然后提交到集群执行,执行效率非常快!
1.易整合
2.统一的数据访问方式
3.兼容Hive
4.标准的数据连接
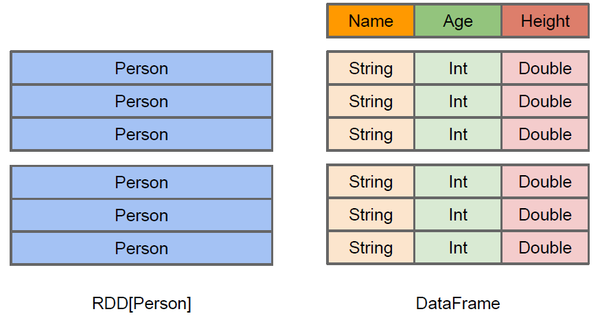
2.2. DataFrames
2.2.1. 什么是DataFrames
与RDD类似,DataFrame也是一个分布式数据容器。然而DataFrame更像传统数据库的二维表格,除了数据以外,还记录数据的结构信息,即schema。同时,与Hive类似,DataFrame也支持嵌套数据类型(struct、array和map)。从API易用性的角度上 看,DataFrame API提供的是一套高层的关系操作,比函数式的RDD API要更加友好,门槛更低。由于与R和Pandas的DataFrame类似,Spark DataFrame很好地继承了传统单机数据分析的开发体验。
2.2.2. 创建DataFrames
在Spark SQL中SQLContext是创建DataFrames和执行SQL的入口,在spark中已经内置了一个sqlContext
1.在本地创建一个文件,有三列,分别是id、name、age,用空格分隔,然后上传到hdfs上
hdfs dfs -put person.txt /
2.在spark shell执行下面命令,读取数据,将每一行的数据使用列分隔符分割
val lineRDD = sc.textFile("hdfs://node1.itcast.cn:9000/person.txt").map(_.split(" "))
3.定义case class(相当于表的schema)
case class Person(id:Int, name:String, age:Int)
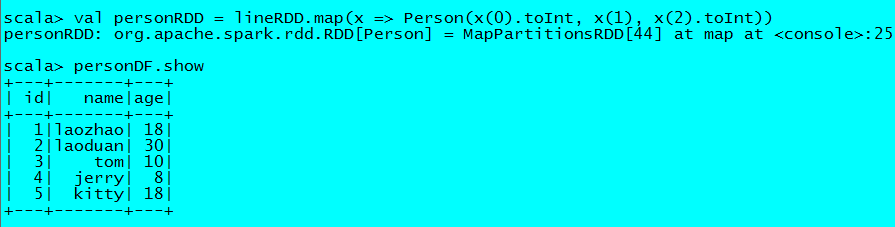
4.将RDD和case class关联
val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt))
5.将RDD转换成DataFrame
val personDF = personRDD.toDF
6.对DataFrame进行处理
personDF.show
2.3. DataFrame常用操作
2.3.1. DSL风格语法
//查看DataFrame中的内容
personDF.show
//查看DataFrame部分列中的内容
personDF.select(personDF.col("name")).show
personDF.select(col("name"), col("age")).show
personDF.select("name").show
//打印DataFrame的Schema信息
personDF.printSchema
//查询所有的name和age,并将age+1
personDF.select(col("id"), col("name"), col("age") + 1).show
personDF.select(personDF("id"), personDF("name"), personDF("age") + 1).show

//过滤age大于等于18的
personDF.filter(col("age") >= 18).show
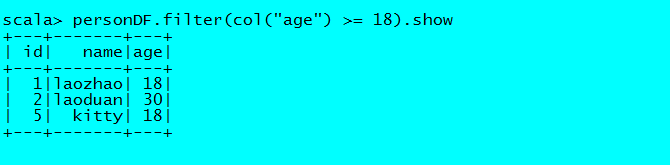
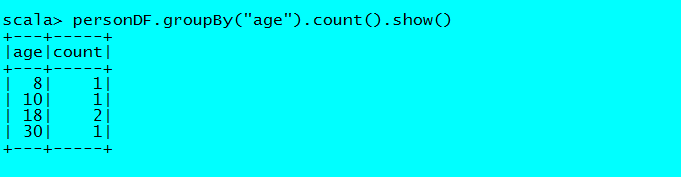
//按年龄进行分组并统计相同年龄的人数
personDF.groupBy("age").count().show()
2.3.2. SQL风格语法
如果想使用SQL风格的语法,需要将DataFrame注册成表
personDF.registerTempTable("t_person")
//查询年龄最大的前两名
sqlContext.sql("select * from t_person order by age desc limit 2").show

//显示表的Schema信息
sqlContext.sql("desc t_person").show

3. 以编程方式执行Spark SQL查询
3.1. 编写Spark SQL查询程序
前面我们学习了如何在Spark Shell中使用SQL完成查询,现在我们来实现在自定义的程序中编写Spark SQL查询程序。首先在maven项目的pom.xml中添加Spark SQL的依赖
| <dependency> </dependency> |
3.1.1. 通过反射推断Schema
创建一个object为org.spark.sql.InferringSchema
| package org.spark.sql
|
将程序打成jar包,上传到spark集群,提交Spark任务
.bin/spark-submit \
--class org.spark.sql.InferringSchema \
--master local(本地方式) \或者(-- master spark://masterIP:port)
/root/spark-mvn-1.0-SNAPSHOT.jar \(用maven打的jar包)
hdfs://mater(localhost):9000/person.txt \(hdfs地址)
hdfs://master(localhost):9000/out
查看运行结果
hdfs dfs -cat hdfs://master(localhost):9000/out/part-r-*

3.1.2. 通过StructType直接指定Schema
创建一个object为org.spark.sql.SpecifyingSchema
| package org.spark.sql
|
将程序打成jar包,上传到spark集群,提交Spark任务
.bin/spark-submit \
--class org.spark.sql.InferringSchema \
--master local(本地方式) \或者(-- master spark://masterIP:port)
/root/spark-mvn-1.0-SNAPSHOT.jar \(用maven打的jar包)
hdfs://mater(localhost):9000/person.txt \(hdfs地址)
hdfs://master(localhost):9000/out
查看结果
hdfs dfs -cat hdfs://master(localhost):9000/out1/part-r-*

3.2 数据源
3.2.1. JDBC
Spark SQL可以通过JDBC从关系型数据库中读取数据的方式创建DataFrame,通过对DataFrame一系列的计算后,还可以将数据再写回关系型数据库中。
3.2.1.1. 从MySQL中加载数据(Spark Shell方式)
1.启动Spark Shell,必须指定mysql连接驱动jar包
.bin/spark-shell \
--master spark://masterIP:Port(或者用local) \
--jars /usr/mysql-connector-java-5.1.35-bin.jar \
--driver-class-path /usr/mysql-connector-java-5.1.35-bin.jar
2.从mysql中加载数据
val jdbcDF = sqlContext.read.format("jdbc").options(Map("url" -> "jdbc:mysql://192.168.111.20:3306/bigdata", "driver" -> "com.mysql.jdbc.Driver", "dbtable" -> "person", "user" -> "root", "password" -> "123456")).load()
3.执行查询
jdbcDF.show()

3.2.1.2. 将数据写入到MySQL中(打jar包方式)
1.编写Spark SQL程序
| package org.spark.sql
|
2.用maven将程序打包
3.将Jar包提交到spark集群
.bin/spark-submit \
--class org.spark.sql.JdbcRDD \
--master spark://masterIP:Port \或者(local)
--jars /usr/mysql-connector-java-5.1.35-bin.jar \
--driver-class-path /usr/mysql-connector-java-5.1.35-bin.jar \
/root/spark-mvn-1.0-SNAPSHOT.jar
4. Spark SQL+DataFrame创建代码
import java.util.Properties
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SQLContext}
import org.apache.spark.sql.types.{DataType, DataTypes, StructField, StructType}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by zys on 2017/9/18 0025.
*/
case class Person(name:String, age:Int)
object CreateDF {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
//spark入口
//spark conf配置对象
valconf = new SparkConf().setAppName("CreateDF").setMaster("local[2]")
val sc = newSparkContext(conf)
//Spark SQL的入口
valsqlContext = new SQLContext(sc)
//一. DataFrame创建
// 1.json文件
// val df = sqlContext.read.json("file:\\G:\\code\\source_code\\spark\\examples\\src\\main\\resources\\people.json")
// 2.parquet文件
// val df = sqlContext.read.parquet("file:\\G:\\code\\source_code\\spark\\examples\\src\\main\\resources\\users.parquet")
// 3.jdbc方式创建
// val props = new Properties()
// props.put("user","root")
// props.put("password","123456")
// val df = sqlContext.read.jdbc("jdbc:mysql://hdp1:3306/spark","student",props)
// 4.通过表创建
// df.registerTempTable("student")
// var sql = sqlContext.sql("select * from student")
// sql.printSchema()
// sql.show()
// 5.avro文件创建
// import com.databricks.spark.avro._
// val df = sqlContext.read.avro("D:/code/spark_code/course/data/users.avro")
// 6.通过RDD的方式
// 6.1反射方式创建DataFrame
// import sqlContext.implicits._
// var rdd = sc.textFile("file:\\G:\\code\\source_code\\spark\\examples\\src\\main\\resources\\people.txt")
// .map { line =>
// val strs = line.split(",")
// Person(strs(0), strs(1).trim.toInt)
// }
// val df = rdd.toDF()
// 6.2注册元数据方法
varrdd = sc.textFile("file:\\G:\\code\\source_code\\spark\\examples\\src\\main\\resources\\people.txt")
.map { line =>
val strs = line.split(",")
Row(strs(0), strs(1).trim.toInt)
}
var structType = StructType(Array(
StructField("name", DataTypes.StringType),
StructField("age", DataTypes.IntegerType)
))
val df = sqlContext.createDataFrame(rdd,structType)
//df操作
df.printSchema()
df.show()
}
}
5. Spark SQL+DataFrame操作和DataSet代码
import java.util.Properties
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SQLContext}
import org.apache.spark.sql.types.{DataType, DataTypes, StructField, StructType}
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.JavaConverters._
/**
* Created by zys on 2017/9/25 0025.
*/
case class Person(name:String, age:java.lang.Long)
object CreateDF {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
//spark入口
//spark conf配置对象
valconf = new SparkConf().setAppName("CreateDF").setMaster("local[2]")
val sc = newSparkContext(conf)
//Spark SQL的入口
valsqlContext = new SQLContext(sc)
//一. DataFrame创建
// 1.json文件
// val df = sqlContext.read.json("file:\\G:\\code\\source_code\\spark\\examples\\src\\main\\resources\\people.json")
// val df = sqlContext.read.format("json").load("G:\\code\\source_code\\spark\\examples\\src\\main\\resources\\people.json")
// sqlContext.read.format("json").load("file:\\G:\\code\\source_code\\spark\\examples\\src\\main\\resources\\people.json")
// 2.parquet文件
// val df = sqlContext.read.parquet("file:\\G:\\code\\source_code\\spark\\examples\\src\\main\\resources\\users.parquet")
// 3.jdbc方式创建
// val props = new Properties()
// props.put("user","root")
// props.put("password","123456")
// val df = sqlContext.read.jdbc("jdbc:mysql://hdp1:3306/spark","student",props)
// 4.通过表创建
// df.registerTempTable("student")
// var sql = sqlContext.sql("select * from student")
// sql.printSchema()
// sql.show()
// 5.avro文件创建
// import com.databricks.spark.avro._
// val df = sqlContext.read.avro("D:/code/spark_code/course/data/users.avro")
// 6.通过RDD的方式
// 6.1反射方式创建DataFrame
// import sqlContext.implicits._
// var rdd = sc.textFile("file:\\G:\\code\\source_code\\spark\\examples\\src\\main\\resources\\people.txt")
// .map { line =>
// val strs = line.split(",")
// Person(strs(0), strs(1).trim.toInt)
// }
// val df = rdd.toDF()
// 6.2注册元数据方法
// var rdd = sc.textFile("file:\\G:\\code\\source_code\\spark\\examples\\src\\main\\resources\\people.txt")
// .map { line =>
// val strs = line.split(",")
// Row(strs(0), strs(1).trim.toInt)
// }
// var structType = StructType(Array(
// StructField("name", DataTypes.StringType),
// StructField("age", DataTypes.IntegerType)
// ))
// val df = sqlContext.createDataFrame(rdd,structType)
//df操作
// df.printSchema() //打印对应的约束信息
// df.show() //小数据量时候,客户端显示数据
// val arrs = df.collect()
// val list = df.collectAsList()
// for(i <- 0 until list.size()){
// println(list.get(i))
// }
// for(ele <- list){
// println(ele)
// }
// println(df.count())
// println(df.describe("name","age"))
// println(df.first())
// for(ele <- df.head(2) ){
// println(ele)
// }
// for(ele <- df.take(1)){
// println(ele)
// }
// for(ele <- df.columns){
// println(ele)
// }
// println(df.schema)
// println(df.select("age").explain())
// 条件过滤
// println(df.filter(df.col("age").gt(20)).first())
// println(df.filter(df.col("age") > 20).first())
// println(df.agg(("name" -> "count")).first())
// println(df.groupBy("name").count())
// df.registerTempTable("people")
// println(sqlContext.sql("select * from people where age > 20").first())
// 第二部分:Dataset
// 1.Dataset的创建
// import sqlContext.implicits._
// var dS = List(Person("Kevin",24),Person("Jhon",20)).toDS()
// val list = List(Person("Kevin",24),Person("Jhon",20))
// val frame = sqlContext.createDataFrame(list)
// frame.printSchema()
// var rdd = sc.textFile("file:\\G:\\code\\source_code\\spark\\examples\\src\\main\\resources\\people.txt")
// .map { line =>
// val strs = line.split(",")
// Person(strs(0), strs(1).trim.toInt)
// }
// var dS = rdd.toDS()
// dS.printSchema()
importsqlContext.implicits._
var frame = sqlContext.read.json("file:\\G:\\code\\source_code\\spark\\examples\\src\\main\\resources\\people.json")
// frame.printSchema()
vardataset = frame.as[Person]
// dataset.printSchema()
// dataset.show()
// dataset.filter(person => person.age > 21).show()
println(dataset.groupBy(person => person.name).count().show())
}
}















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









