






摘要
背景
资源受限场景下的图像超分辨率(SR)需要平衡性能和延迟的轻量级模型。
挑战
CNN提供低延迟,但是缺少全局特征的捕获,Transformers擅长于全局建模,但是推理速度较慢
提出新方法
提出大型内核调制网络(LKMN),是一种基于CNN的模型,有两个核心模块增强型部分大内核模块(EPLKB)和跨门前馈网络(CGFN),EPLKB通过通道洗牌促进通道间的交互,结合通道注意力关注关键信息,并在部分通道上应用大核条带卷积以降低复杂度进行非局部特征提取。CGFN 通过可学习的缩放因子动态调整输入、局部和非局部特征之间的差异,然后采用跨门策略来调制和融合这些特征,增强它们的互补性。
贡献
方法优于现有的SOTA轻量级模型,同时平衡了质量和效率。
引言
背景
图像超分辨率(SR)是指从低分辨率(LR)输入重建高分辨率(HR)图像的过程,作为数学书不合理的问题,SR极大的受益于例如CNN、Transformers等深度学习技术,它们提供了强大的特征提取和表示能力。较传统方法,这些方式在SR上实现了显著的提升。
挑战
这些收益通常来源于不断复杂的架构,导致了模型参数和计算成本以及推理延迟的显著提升
研究现状
基于 Transformer 的高效 SR 模型,如 SwinIR-light 和 SRFormer-light,受益于 Self-Attention 机制强大的远程建模能力,从而实现了远超 CNN 模型的 SR 性能。这表明非局部特征对于提高高效 SR 模型的性能至关重要。然而,Self-Attention 机制显著降低了模型的推理速度,这对于边缘设备来说是不可接受的。
目前,基于 CNN 的高效 SR 方法,如 RFDN和 BSRN ,倾向于堆叠小卷积核(3 × 3),以增强局部特征提取并最大限度地减少延迟。然而,这种方法缺乏捕获非局部特征信息的能力,从而限制了模型的性能。为了解决这个问题,VapSR和 LKDN] 等方法考虑采用大核分解和扩张卷积来扩展模型的感受野,但这不可避免地导致了信息丢失。此外,PLKSR建议直接采用 17 × 17 个大核卷积进行非局部特征提取。虽然这有效地捕获了信息,但它会导致模型参数和计算开销急剧增加。
提出新方法
提出了一种纯CNN模型,成为大内核调制网络,分为EPLKB和CGFN,EPLKB在部分通道上使用 31 × 31 个大卷积核来提取非局部特征。CGFN动态调整输入特征、非局部特征和局部特征之间的特征差异,并采用跨门策略,增强模型对非局部特征和局部特征的建模和融合能力。基于上述设计,所提出的 LKMN 与其他 SOTA 轻量级 SR 方法相比,实现了更优越的 SR 性能,同时保持了相当的模型复杂度和推理速度。
贡献
提出了EPLKB,通过通道洗牌和部分通道大核条卷积,该设计不仅保留了大核卷积固有的非局部特征提取能力,而且有效降低了模型复杂度
提出了CGFN,动态调整局部和非局部特征之间的特征差异,通过跨门策略能够更明确的对局部和非局部特征之间的互补性进行建模
大量实验表明,所提出的 LKMN 在定量和定性上都优于其他轻量级 SR 方法,同时保持更快的推理速度。
相关工作
高效图像超分辨率
SRCNN 的引入确立了 CNN 作为解决高效图像 SR 的有效方法。例如,IMDN 和 RFDN 采用特征蒸馏策略来有效地细化特征,同时消除冗余信息。BSRN 和 SMFANet 分别利用蓝图可分离卷积 (BSConv) 和深度卷积 (DWConv) 来进一步降低模型复杂性。EARFA 构建了一种基于微分熵的注意力机制来评估信道特征的重要性。鉴于 CNN 难以捕获远程特征依赖关系,基于 Transformer 的 SR 方法已表现出卓越的性能。SwinIR 通过计算局部窗口内的注意力矩阵来降低计算复杂性。SRFormer 构建了基于窗口的转置自注意力,从而实现了更显著的性能。CAMixerSR将卷积与可变形窗口自注意力相结合,显著降低了推理延迟。ASID 引入了注意力共享特征蒸馏框架,有效缓解了自注意力的效率瓶颈。然而,现有的基于 Transformer 的 SR 方法在推理速度方面仍然明显落后于基于 CNN 的方法,使其不适合具有实时性要求的低计算能力设备。
大内核网络
最近的研究强调了大型卷积核的有效性。例如,SegNeXt 通过融合具有 7、11 和 21 大核大小的深条带卷积分支,增强了其捕获多尺度上下文信息的能力。PLKSR 在部分通道上使用了 17 × 17 个大卷积核,以近似 Transformer 处理远程依赖关系的能力。RepLKNet采用 31 × 31 个大卷积核来扩展感受野,同时通过 DWConv 缓解计算负载的急剧增加。SLaK通过在矩阵核中引入动态稀疏性,进一步将卷积核大小推高到 51。OKNet使用 63 × 63 个不同形状的大卷积核捕获多尺度感受野并调制大规模信息。PeLK提出了模拟人类视觉感知的外围卷积,通过参数共享有效减少卷积参数,使卷积核大小达到惊人的 101。
方法部分只涉及EPLKB
预先准备
给定输入F∈RC×H×W\mathbf{F} \in \mathbb{R}^{C \times H \times W}F∈RC×H×W
输出加强特征Fout∈RC×H×W\mathbf{F}_{out} \in \mathbb{R}^{C \times H \times W}Fout∈RC×H×W
方法部分
![![[Pasted image 20251011160020.png]]](https://i-blog.csdnimg.cn/direct/f7058b42843c48ffac0d446b4c0be51c.png)
对于输入特征F,将其Reshape为Rd×N×H×W\mathbb{R}^{d \times N \times H \times W}Rd×N×H×W
其中C=d×NC = d \times NC=d×N,N是组的数量,d是每组的通道数,交换这两个维度,并恢复为与输入相同的shape
F∈RN×d×H×W=Permute(F)F \in \mathbb{R}^{N \times d \times H \times W}=Permute(F)F∈RN×d×H×W=Permute(F)
F∈RC×H×W=Reshape(F)F \in \mathbb{R}^{C \times H \times W}=Reshape(F)F∈RC×H×W=Reshape(F)
将洗牌后的特征分割为两部分,其中F1是具有一组通道的特征,F2是剩下的所有通道特征,加入洗牌操作后,在模型不同深度下,通过不断搅拌通道,可以提升跨组信息的交换和覆盖面
F1∈Rd×H×W,F2∈R(C−d)×H×WF_1 \in \mathbb{R}^{d \times H \times W},F_2 \in \mathbb{R}^{(C-d)\times H \times W}F1∈Rd×H×W,F2∈R(C−d)×H×W
然后F1F_1F1进行特征提取,先通过一个通道注意力模块增强感兴趣的通道,再通过两个不同方向的大核条状卷积提取垂直和水平方向的特征
F1′=DWConv31×1(DWConv1×31(ChannelAttention(F1)))F_{1'}=DWConv_{31 \times 1}(DWConv_{1 \times 31}(ChannelAttention(F_1)))F1′=DWConv31×1(DWConv1×31(ChannelAttention(F1)))
相比于31×3131 \times 3131×31的二维卷积,条状卷积有着更高的效率和更少的参数,并在捕捉长条纹理时更有效
最后将输出的F1′F_{1'}F1′与原特征在通道方向上拼接,通过点卷积进行融合
Fout=Conv1×1(Concat(F1′,F2))F_{out}=Conv_{1 \times 1}(Concat(F_{1'},F_2))Fout=Conv1×1(Concat(F1′,F2))
实验部分
在DIV2k和Flickr2K数据集上进行训练,采用五个数据集Set5、Set14、BSD100、Urban100和Manga109测试
具体细节
通过滑动窗口切片作将训练的 HR 图像分解成 480 × 480 个小块,以加快训练速度,同时通过随机旋转、水平和垂直翻转进行数据增强。裁剪后的 LR 补丁大小和批量大小分别设置为 48 和 64。使用 Adan 优化器优化了 1000K 迭代的 L1 损耗和 FFT 损耗,特别是在 DIV2K 数据集上训练时 LKMN-L 的 500K 迭代。初始和最小学习率设置为 5 × 10−3 和 1 × 10−6 ,根据余弦退火方案进行更新。所有实验均使用 NVIDIA RTX 3090 GPU 上的 PyTorch 框架进行。对于{LKMN, LKMN-L},RFMG 和通道的数量分别设置为{8, 12}和{36, 64}。同时,EPLKB 中的洗牌组 g 和核大小分别设置为 4 和 31。
![![[Pasted image 20251011163314.png]]](https://i-blog.csdnimg.cn/direct/ffa506d0a84e4cbaab1b22dcf8a25382.png)
与最先进方法的比较
定量比较
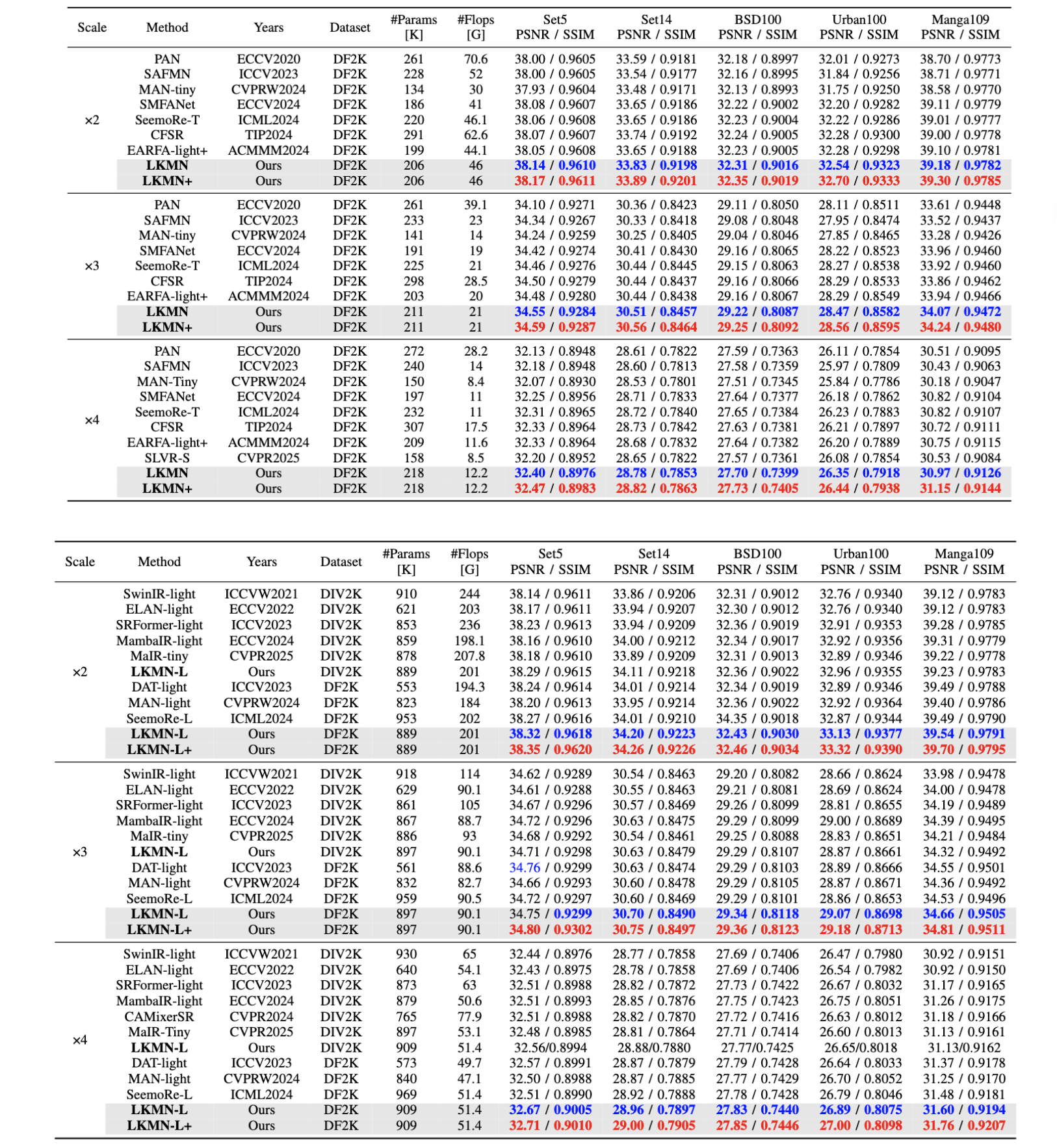
对于 LKMN 和 LKMN-L,与基于 CNN 和基于 Transformer 的模型相比,它们在所有数据集中几乎都实现了最佳的 SR 性能。同时,当 LKMN-L 仅在 DIV2K 数据集上进行训练以与基于 Transformer 的模型进行公平比较时,它仍然获得了优越或相当的 SR 性能。实验结果证明了所提出的 LKMN 的有效性。
定性比较

图中给出了所提出的 LKMN 与其他轻量级 SR 方法之间的视觉比较。可以观察到,我们方法的微型和大型版本都表现出更强的图像恢复能力,能够重建更多的图像细节(例如,img-062 和 img-092),同时具有更少的失真(例如,img-054 和 img-100)。上述结果也凸显了所提出的 LKMN 的有效性。
![![[Pasted image 20251011163514.png]]](https://i-blog.csdnimg.cn/direct/be065763393141cf9b86165bf8ca8db5.png)
同时,还利用局部归因图(LAM)来分析感受野的范围,如图所示 所提出的 LKMN-L 能够获得更高的扩散指数(DI)值和更大的感受野,证明了大核卷积的有效性。
GPU内存和延迟比较
![![[Pasted image 20251011163547.png]]](https://i-blog.csdnimg.cn/direct/e4aa1abad161451ba3463ef3307d24b6.png)
表显示了 GPU 内存消耗和推理速度的比较。尽管 LKMN 实现了最佳的 SR 性能,但其推理速度比其他基于 CNN 的模型略慢。LKMN-L 实现了最佳的 SR 性能和最快的推理速度,比基于 Transformer 的 DAT-light 模型快近 × 4.8 倍,同时 GPU 内存消耗减少 71.6%。同时,LKMN-L 比基于 CNN 的 MAN-light 型号快 16%。上述分析表明,所提出的 LKMN 系列在 SR 性能和推理速度之间实现了更好的平衡。
定量视觉感知对比
![![[Pasted image 20251011163650.png]]](https://i-blog.csdnimg.cn/direct/efe213c58e1b444fa5497d11952f82a4.png)
为了对所提出的 LKMN 的性能进行更全面的分析,我们进一步采用主观评价指标 LPIPS 来评估视觉感知性能,结果如表所示。对于微型版本,所提出的 LKMN 实现了最佳的感知指标,证明了其优于其他基于 CNN 的轻量级 SR 模型。对于大型版本,与基于 Transformer 的模型 CAMixerSR 相比,所提出的 LKMN-L 的性能略逊一筹,但略优于 SwinIR-light,这表明其性能有可能优于基于 Transformer 的轻量级 SR 模型。
真实世界的超分辨率图像

我们还探索了模型在真实世界图像上的重建能力,以检验其泛化性和实用性,结果如图所示,当不在真实世界的图像数据集上进行训练时,常用的轻量级 SR 模型的恢复性能相对有限。然而,仍然可以观察到,与其他模型相比,所提出的 LKMN-L 能够重建更清晰的纹理细节,证明了所提出模型的优越性。
消融实验
EPLKB
首先验证EPLKB的通道洗牌和通道注意力,如表所示,当删除这些设计中的每一个,性能都会下降,证明了其有效性,此外使用全卷积核时,模型参数、计算和推理时间分别增加了× 6.3 倍、 × 6.5 倍和 74.4%,而性能反而下降了。这证实了条状大卷积核设计的有效性。
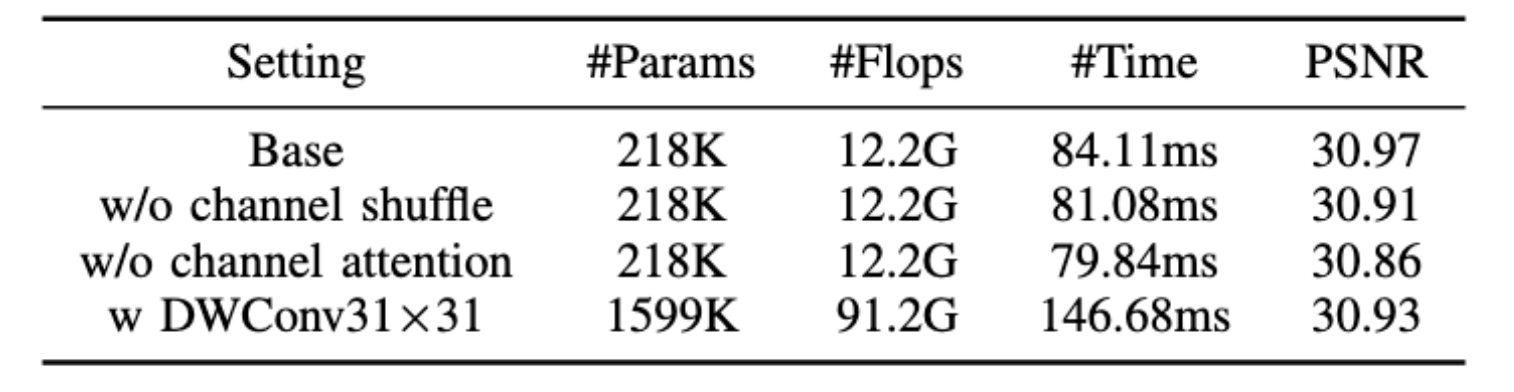
同时分析了EPLKB中核大小,随着核大小增大,SR性能逐渐提高,当达到31时为最优,,超过31时模型性能下降可能是过大的卷积核引入了更多的冗余信息,待未来工作研究
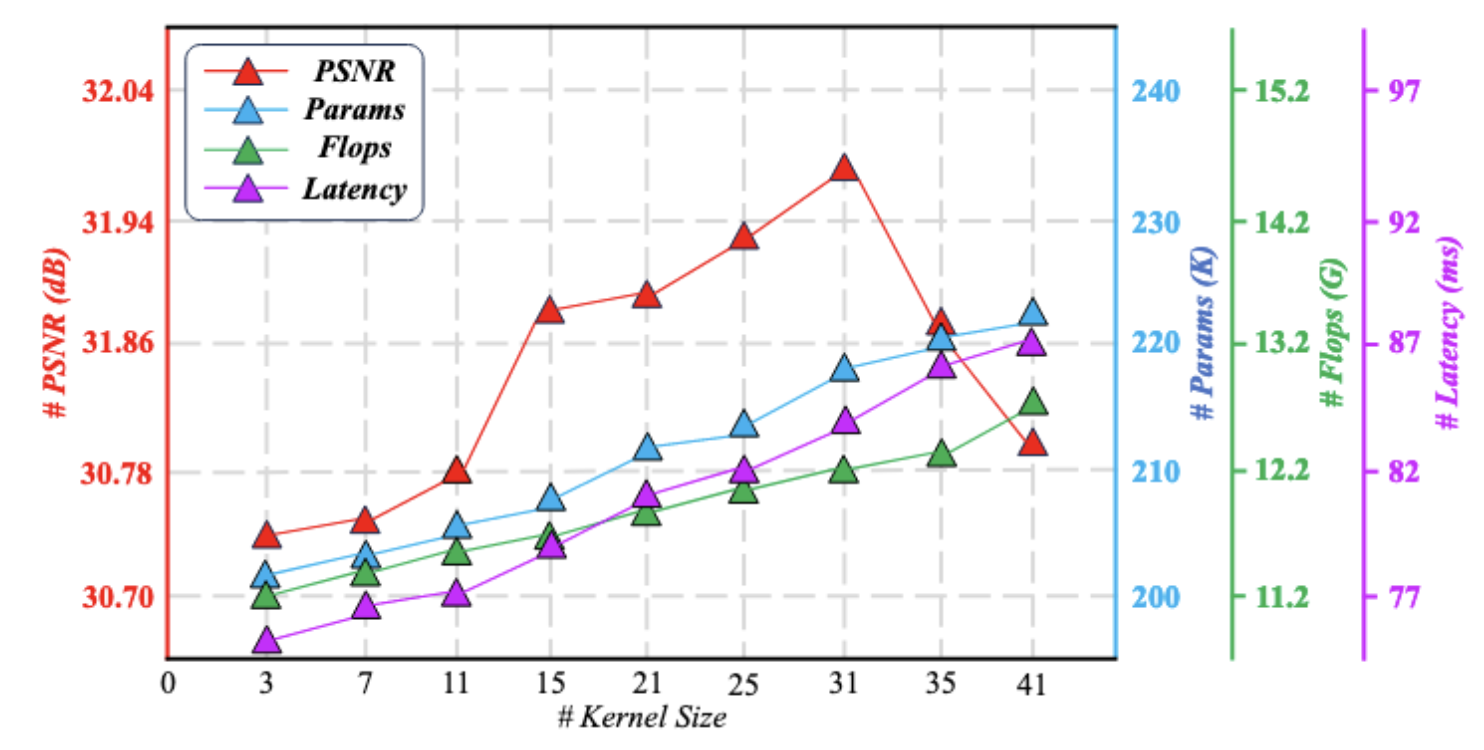
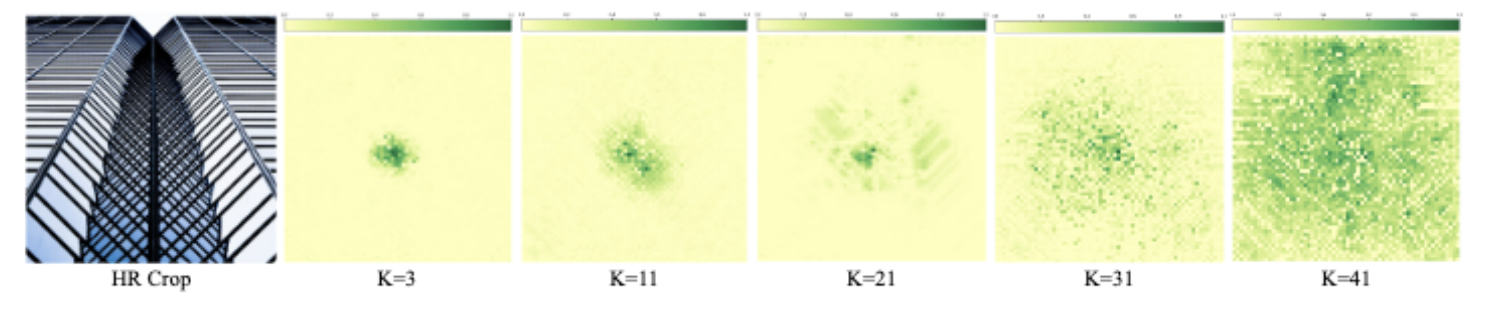
同时使用有效感受野对核大小进行分析,随着卷积核大小的增大,感受野的范围也逐渐扩大。以上实验都证明了大核卷积的有效性。
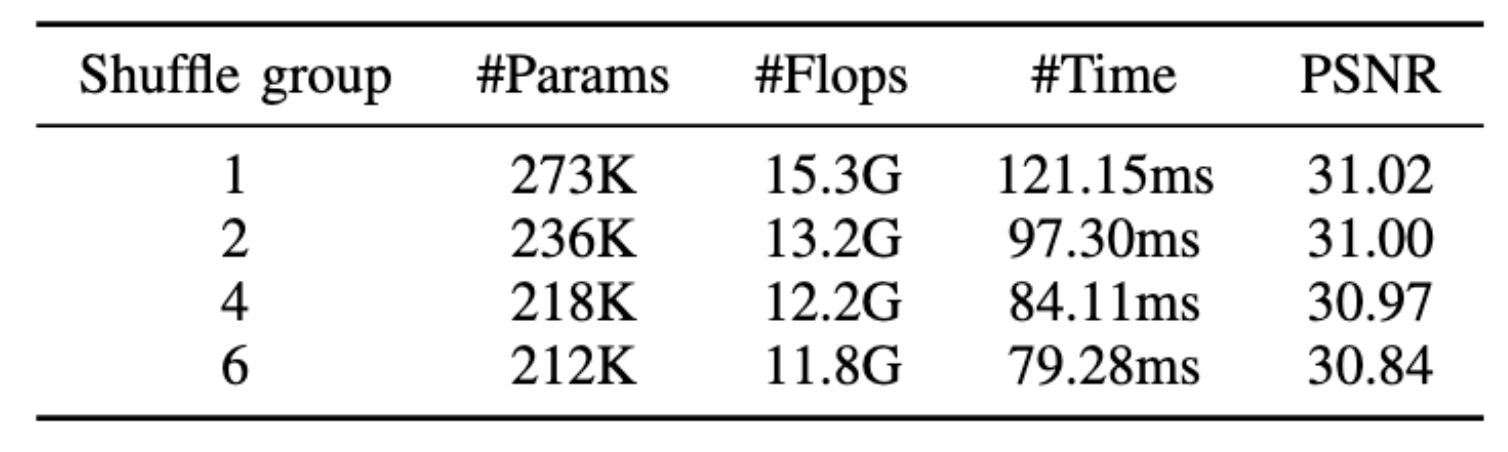
此外,我们分析了洗牌组 g 对模型性能的影响,如表所示。随着 的 g 值减小,参与特征提取的通道数量逐渐增加,导致 SR 性能相应提高。然而,模型的复杂性和推理时间也逐渐增加。考虑到高效 SR 模型的设计目标,我们最终设置为 g=4,以在模型复杂度、SR 性能和推理速度之间保持更好的平衡。
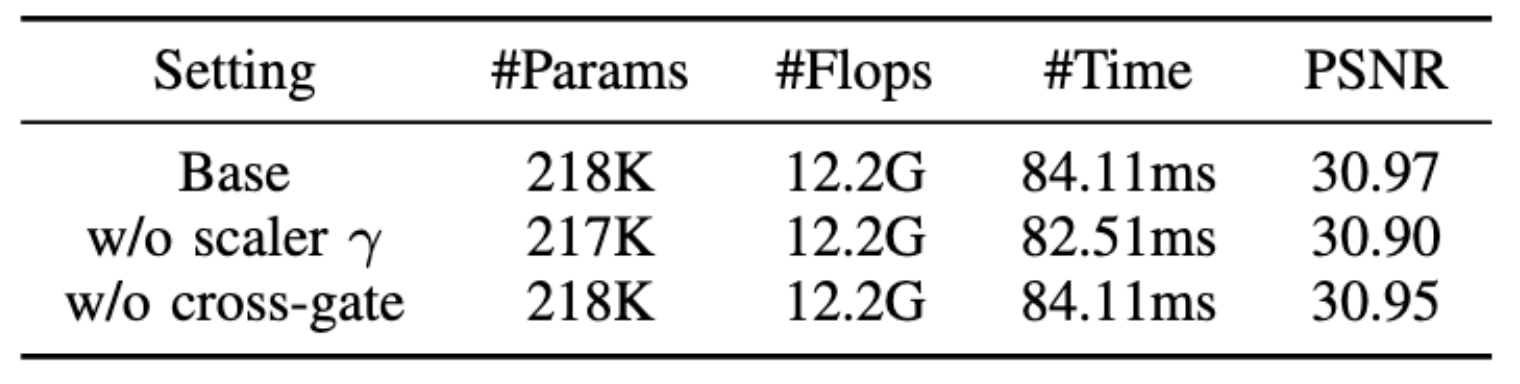
CGFN
显示了可学习比例因子 γ 和跨门策略的影响。当可学习的缩放因子 γ 被删除并将交叉门控策略替换为直接门控时,SR 性能会下降。此外,它们都对模型复杂度或推理速度没有实质性影响,这都证明了它们的有效性。
此外,我们分析了 CGFN 中的特征图输出,如图所示、可以看出,EPLKB 倾向于提取全局轮廓等低频信息,而 DWConv3×3 负责提取局部纹理信息。同时,通过调制特征差异可以获得更全面的特征信息,在交叉门策略的作用下,可以更突出地对非局部和局部特征进行建模。上述分析也证明了 CGFN 模块的有效性。
![![[Pasted image 20251011164222.png]]](https://i-blog.csdnimg.cn/direct/aabd6a23d84a4fabb9be6106f503c517.png)
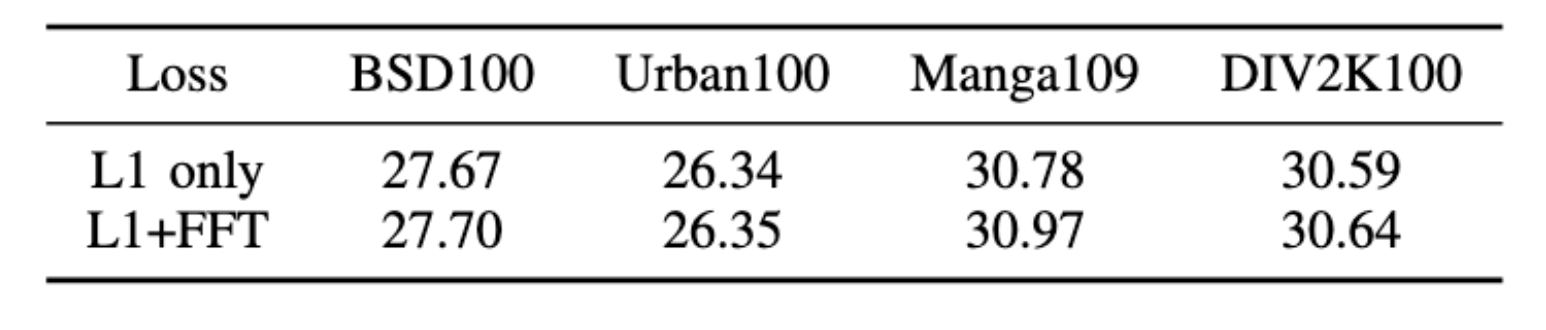
消融损失函数实验
分析了不同损失函数对模型性能的影响,结果如表 所示。FFT 损耗用于最小化频域特征差异,可以从低频和高频特征的角度更好地指导模型训练。因此,与常用的 L1 损耗相比,加上 FFT 损耗后模型性能进一步提高,在 SeemoRe 中也观察到了这种现象
结论
方法
提出了LKMM,是一种基于CNN的高效SR模型,通过设计部分通道条状大核卷积,在获得较强非局部特征提取能力的同时,有效控制了核尺寸增大导致的模型复杂度增加的问题,并引入动态调整局部和非局部特征之间的差异,引入交叉们机制,增强特征融合的特异性
效果
实现优于其他方法的性能,同时保留CNN的低延迟优势
展望未来
首先,虽然所提模型的性能优于其他 SR 模型,但 LKMN 的推理速度略慢于基于 CNN 的 SR 模型。另一方面,当所用的大卷积核的大小为 31 时,可以获得最佳性能,但进一步增加大小会导致尽管扩大了感受野,但性能会下降。造成这种现象的原因目前仅被推测为噪音的引入,尚未给出真正的解释。在未来的工作中,我们将对模型进行全面分析,探索更高效的网络架构,以进一步降低推理速度。同时,我们还将尝试使用频域分析和特征图可视化等方法来进一步验证卷积核大小对模型性能的影响。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











