







当使用CI框架进行开发时,发现这样一个小问题,文件上传的时候,一切都正常,但是当上传0字节文件的时候(以.txt文件为例),报出以下错误:
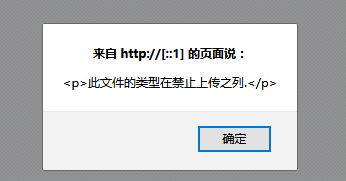
那么为什么明明设置的上传允许类型有,但是还显示类型在禁止上传之列呢?
经过一番查询资料,才得知原来是mimes.php中没有对应的类型,才导致上传类判断没有对应的类型。
那么首先我们先获取这个文件的mime类型(如下):
在CI目录下system/libraries/Upload.php找到(并添加红框中的内容):
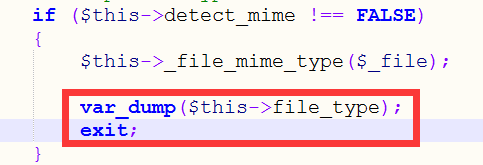
然后回到页面中选择0字节文件,点击上传,会输出如下内容:
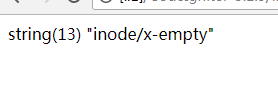
说明0字节的.txt文件mime类型是这,我们只需要在mimes.php中加上对应的类型即可。

然后 保存,回去,发现可以了,大功告成。类似的错误都可以这样解决。















 3823
3823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









