







1、Redis持久化有几种方式?
redis提供了两种持久化的方式,分别是RDB(Redis DataBase)和AOF(Append Only File)。
RDB,简而言之,就是在不同的时间点,将redis存储的数据生成快照并存储到磁盘等介质上;
AOF,则是换了一个角度来实现持久化,那就是将redis执行过的所有写指令记录下来,在下次redis重新启动时,只要把这些写指令从前到后再重复执行一遍,就可以实现数据恢复了。
其实RDB和AOF两种方式也可以同时使用,在这种情况下,如果redis重启的话,则会优先采用AOF方式来进行数据恢复,这是因为AOF方式的数据恢复完整度更高。
如果你没有数据持久化的需求,也完全可以关闭RDB和AOF方式,这样的话,redis将变成一个纯内存数据库,就像memcache一样。
2、Redis快的原因:
1、redis完全基于内存:绝大部分请求是纯粹的内存操作,非常快速。
2、数据结构简单:redis中的数据结构是专门进行设计的。
3、采用单线程模型,避免了不必要的上下文切换和竞争条件:也不存在多线程或者多线程切换而消耗CPU, 不用考虑各种锁的问题, 不存在加锁, 释放锁的操作, 没有因为可能出现死锁而导致性能消耗
4、使用了多路IO复用模型:非阻塞IO
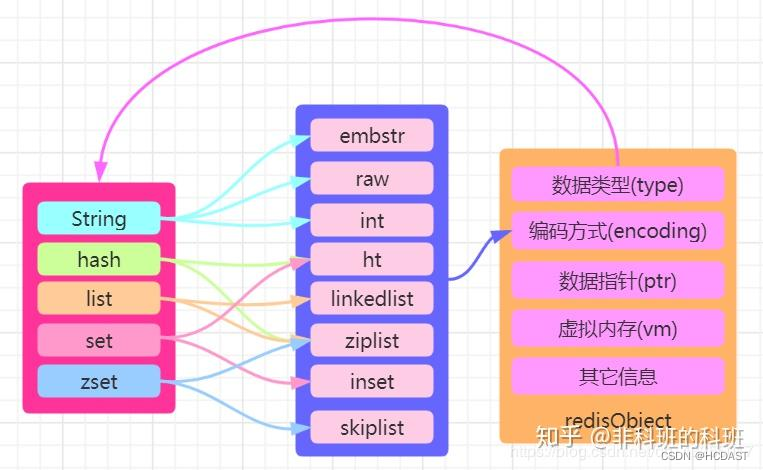
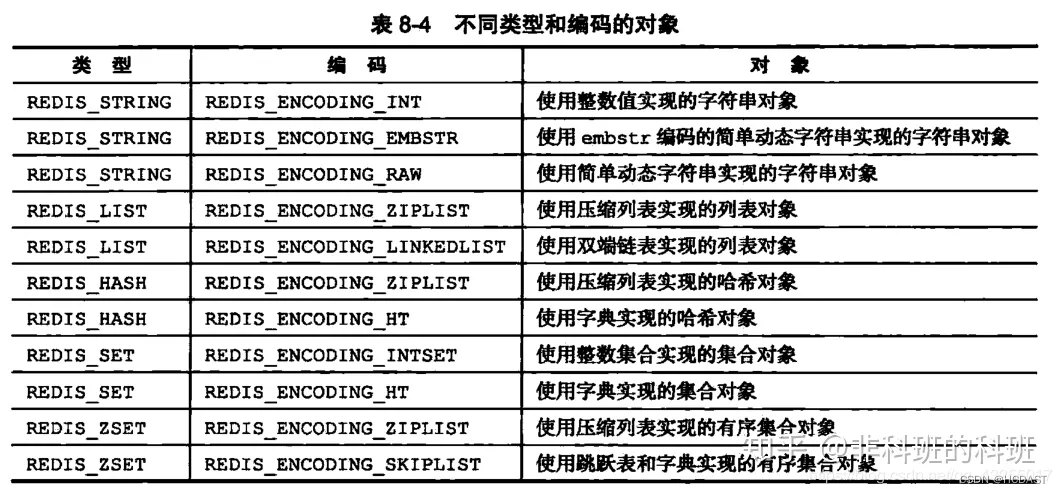
3、Redis的数据类型
String(字符串):
底层数据结构:
SDS即动态字符串,最大容量512M,每次最多扩容1M,是二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或序列化的对象
应用场景:
分布式锁、计数器(如访问次数、点赞转发数量)
常用方法:
set 、get、strlen 、incr 、 decr 、setnx、setex、exists
内部编码:
int编码:当字符串长度小于等于12字节并且字符串可以表示为整数时,Redis会使用int编码。这样可以节省内存,并且在执行一些命令时可以直接进行数值计算。
embstr编码:当字符串长度小于等于39字节时,Redis会使用embstr编码。这种编码方式会将字符串和存储它的结构体一起分配在内存中,这样可以减少内存碎片和结构体的开销。
raw编码:当字符串长度大于39字节或者字符串不能表示为整数时,Redis会使用raw编码。这种编码方式直接将字符串存储在一个结构体中,没有进行任何优化。
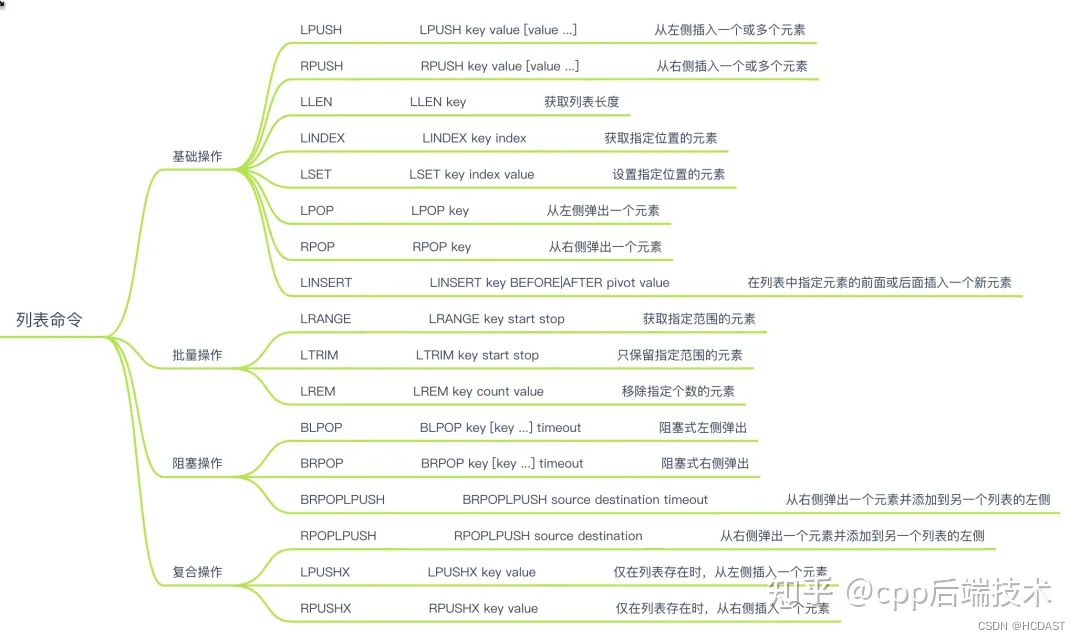
list(双向列表):
特点:单值多键,用来存储多个有序的字符串,一个列表最多可以存储2^32-1个元素。可以实现队列和栈
底层数据结构:
快表
应用场景:
消息队列 、文章列表
常用方法:
lpush 、lrang 、rpush 、lpop 、rpop 、llen、lindex、rpoplpush、linsert
内部编码:
ziplist是一种特殊的编码方式,它可以将小数据量的列表存储在一个连续的内存块中,节省了内存空间,同时还可以提高存取效率。
ziplist编码的列表最大长度为2^16-1个元素,每个元素可以是字符串类型、整数类型或浮点数类型。在ziplist中,每个元素都被存储为一个字节数组,并包含一个前缀和一个后缀,用于标识该元素的类型和长度。linkedlist是一种常规的双向链表结构,它可以存储任意长度的列表,并且支持高效的插入和删除操作。在linkedlist中,每个节点都包含了一个指向前一个节点和后一个节点的指针,以及一个存储元素数据的指针。
linkedlist适用于存储大数量的列表,它没有像ziplist那样的内存限制,但是会占用更多的内存空间。
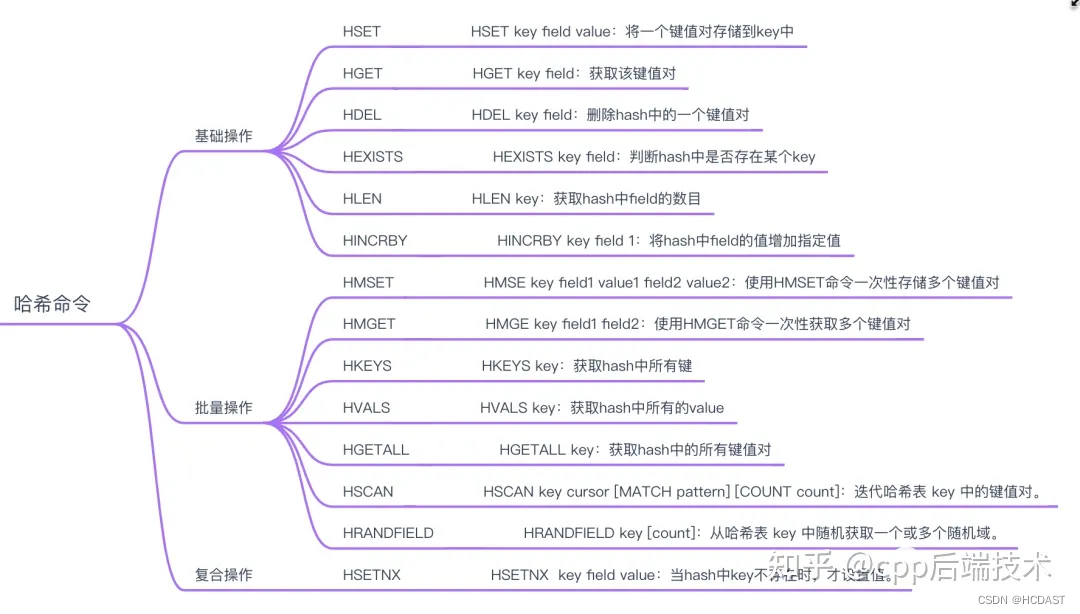
Hash(哈希):
底层数据结构:压缩列表、哈希表。
特点:指v(值)本身又是一个键值对(k-v)结构
应用场景:
缓存用户信息、购物车等。
常用方法:
hset 、hget 、hkeys 、hvals 、hmset 、hmget 、hgetAll 、hlen 、hdel 、hsetnx
、hexists
内部编码:
ziplist(压缩列表):当Hash类型的元素比较少,且元素的大小比较小(小于64字节)时,Redis采用ziplist作为Hash类型的内部编码。ziplist是一种紧凑的、压缩的列表结构,可以节省内存空间。但是,ziplist只能进行线性查找,不支持快速的随机访问。
hashtable(字典):当Hash类型的元素比较多,或者元素的大小比较大(大于64字节)时,Redis采用hashtable作为Hash类型的内部编码。hashtable是一种基于链表的哈希表结构,可以快速地进行随机访问。但是,hashtable需要占用更多的内存空间。
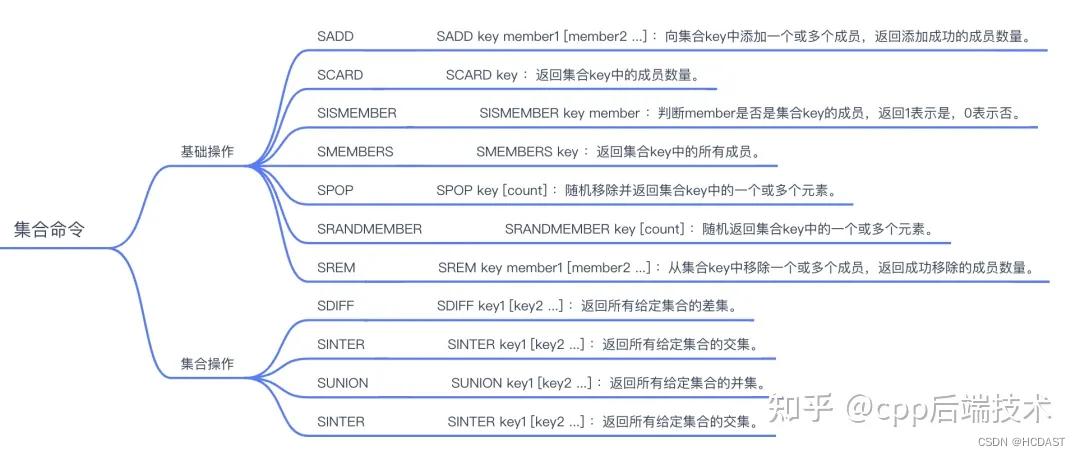
set(集合):
特点:用来保存多个的字符串元素,但是不允许重复元素,元素是无序的。可以实现并集、交集、差集的操作
底层数据结构:
哈希表、整数集
应用场景:
抽奖、共同关注、QQ内推等。
常用方法:
sadd 、smembers 、sismember 、scard 、srem、srandmember、spop、smove、sdiff、sinter、sunion
内部编码:
intset(整数集合):当Set类型只包含整数类型的数据,并且元素数量较少(小于512个)时,Redis会使用intset作为Set类型的内部编码。intset是一种紧凑的、压缩的整数集合结构,可以节省内存空间,并且支持快速的查找、插入和删除操作。在intset中,所有元素都按照从小到大的顺序排列,并且可以使用不同的编码方式(16位、32位、64位)存储不同大小范围内的整数。
hashtable(字典):当Set类型包含字符串类型或者元素数量较多时,Redis会使用hashtable作为Set类型的内部编码。hashtable是一种基于链表的哈希表结构,可以快速地进行随机访问、插入和删除操作。在hashtable中,每个元素都被存储为一个字符串,并且使用哈希函数将字符串映射到一个桶中,然后在桶中进行查找、插入和删除操作。
zset(有序集合)
特点:有序不重复的集合。和 set 相⽐sorted set 增加了⼀个权重参数 score,可以根据score进行排序,但score是可以重复的,value是不可以重复的。
底层数据结构:
压缩列表、跳表
应用场景:
排行榜、抖音热搜
常用方法:
zadd 、zrange 、zrangebyscore(按score从小到大) 、zrem 、zcard 、zcount、zrevrange(按score从大到小)

内部编码:
ziplist编码:当Zset中元素个数小于128个,并且所有元素的长度都小于64字节时,Redis会使用ziplist编码存储Zset。这种编码方式可以节省内存空间,并且可以提高存取效率,但是不支持随机访问和范围查询。
skiplist编码:当Zset中元素个数大于等于128个,或者有一个元素的长度大于64字节时,Redis会使用skiplist编码存储Zset。这种编码方式支持高效的随机访问和范围查询,但是需要占用更多的内存空间。
4、Redis 对 ACID的支持性理解
-
原子性atomicity
Redis官方文档给的理解是,Redis的事务是原子性的:所有的命令,要么全部执行,要么全部不执行。而不是完全成功。 -
一致性consistency
redis事务可以保证命令失败的情况下得以回滚,数据能恢复到没有执行之前的样子,是保证一致性的,除非redis进程意外终结。 -
隔离性Isolation
redis事务是严格遵守隔离性的,原因是redis是单进程单线程模式(v6.0之前),可以保证命令执行过程中不会被其他客户端命令打断。但是,Redis不像其它结构化数据库有隔离级别这种设计。 -
持久性Durability
redis事务是不保证持久性的,这是因为redis持久化策略中不管是RDB还是AOF都是异步执行的,不保证持久性是出于对性能的考虑。
5、zset数据结构
zipList:
满足以下两个条件:
- [score,value]键值对数量少于128个;
- 每个元素的长度小于64字节;
skipList:
不满足以上两个条件时使用跳表(组合了hash和skipList)
- hash用来存储value到score的映射,这样就可以在O(1)时间内找到value对应的分数;
- skipList按照从小到大的顺序存储分数;
- skipList每个元素的值都是[score,value]对
Redis 中 zset 不是单一结构完成,是跳表和哈希表共同完成。
Redis sorted set的内部使用HashMap和跳跃表(skipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
6、什么是跳表?
对链表进行改造,在链表上建索引,即每两个结点提取一个结点到上一级,我们把抽出来的那一级叫作索引。这种链表加多级索引的结构,就是跳表。
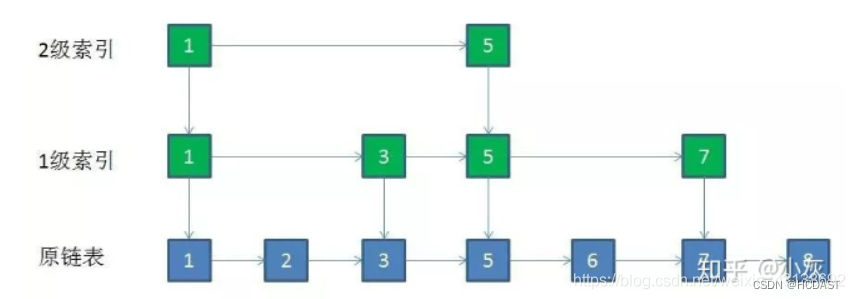
跳表的特点:
由许多层结构组成。
- 每一层都是一个有序的链表。
- 最底层 (Level 1) 的链表包含所有元素。
- 如果一个元素出现在 Level i 的链表中,则它在 Level i 之下的链表也都会出现。
- 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素。
跳表的优点:
跳表可以保证增、删、查等操作时的时间复杂度为O(logN),且维持结构平衡的成本比较低,完全依靠随机。而二叉查找树在多次插入删除后,需要Rebalance来重新调整结构平衡。
跳表的缺点:
跳表占用的空间比较大(多级索引),其实就是一种空间换时间的思想。
7、哈希表数据结构
Hash类型是Redis中非常重要的复合型结构,通过(K,V)来实现,采用链地址法来处理哈希冲突,整体数据结构与Java中的HashMap极为相似,都是采用数组+链表(Redis中不会将链表改为红黑树)的结构来实现,我们直接来看一下哈希表结构图
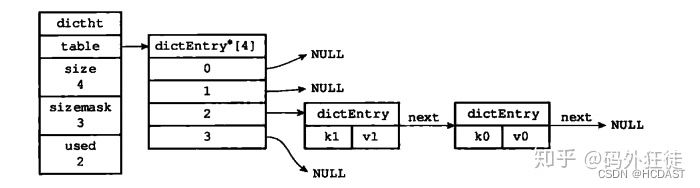
Hash对象的实现方式有两种分别是ziplist、hashtable,其中hashtable的存储方式key是String类型的,value也是以key value的形式进行存储。
字典类型的底层就是hashtable实现的,明白了字典的底层实现原理也就是明白了hashtable的实现原理,hashtable的实现原理可以于HashMap的是底层原理相类比。
hashtable中计算出hash值后,通过sizemask 属性和哈希值再次得到数组下标。为了解决hash冲突,假如hashtable中不同的key通过计算得到同一个index,就会形成单向链表(「链地址法」),如下图所示:
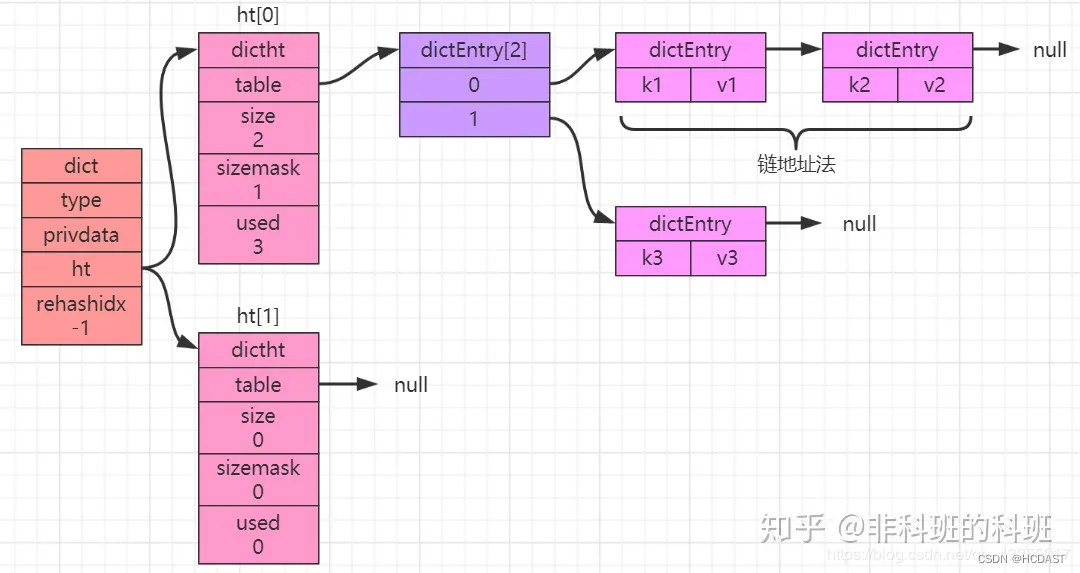
8、rehash与渐进式rehash
-
在字典的底层实现中,value对象以每一个dictEntry的对象进行存储,当hash表中的存放的键值对不断的增加或者减少时,需要对hash表进行一个扩展或者收缩。
在hash表结构定义中有四个属性分别是dictEntry **table、unsigned long size、unsigned long sizemask、unsigned long used,分别表示的含义就是「哈希表数组、hash表大小、用于计算索引值,总是等于size-1、hash表中已有的节点数」。
ht[0]是用来最开始存储数据的,当要进行扩展或者收缩时,ht[0]的大小就决定了ht[1]的大小,ht[0]中的所有的键值对就会重新散列到ht[1]中。
扩展操作:ht[1]扩展的大小是比当前 ht[0].used 值的二倍大的第一个 2 的整数幂;收缩操作:ht[0].used的第一个大于等于的 2 的整数幂。
当ht[0]上的所有的键值对都rehash到ht[1]中,会重新计算所有的数组下标值,当数据迁移完后ht[0]就会被释放,然后将ht[1]改为ht[0],并新创建ht[1],为下一次的扩展和收缩做准备。
-
假如在rehash的过程中数据量非常大,Redis不是一次性把全部数据rehash成功,这样会导致Redis对外服务停止,Redis内部为了处理这种情况采用「渐进式的rehash」。
Redis将所有的rehash的操作分成多步进行,直到都rehash完成,具体的实现与对象中的rehashindex属性相关,「若是rehashindex 表示为-1表示没有rehash操作」。
当rehash操作开始时会将该值改成0,在渐进式rehash的过程「更新、删除、查询会在ht[0]和ht[1]中都进行」,比如更新一个值先更新ht[0],然后再更新ht[1]。
而新增操作直接就新增到ht[1]表中,ht[0]不会新增任何的数据,这样保证「ht[0]只减不增,直到最后的某一个时刻变成空表」,这样rehash操作完成。















 640
640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









