






写在前面
本人在喜播平台上关注学习到《说书的小马哥》评书,觉得十分精彩。奈于平台上作评文件不完整,于是联系到作者寻求完整的资源。
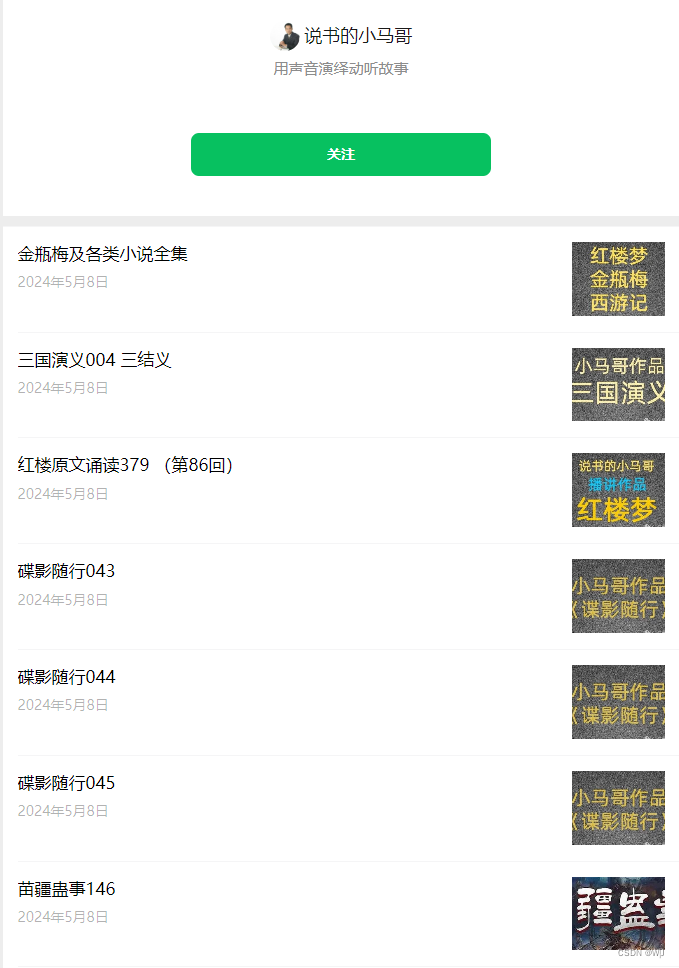
但公众号资源播放时候只能点进去不能连播,十分不方便。
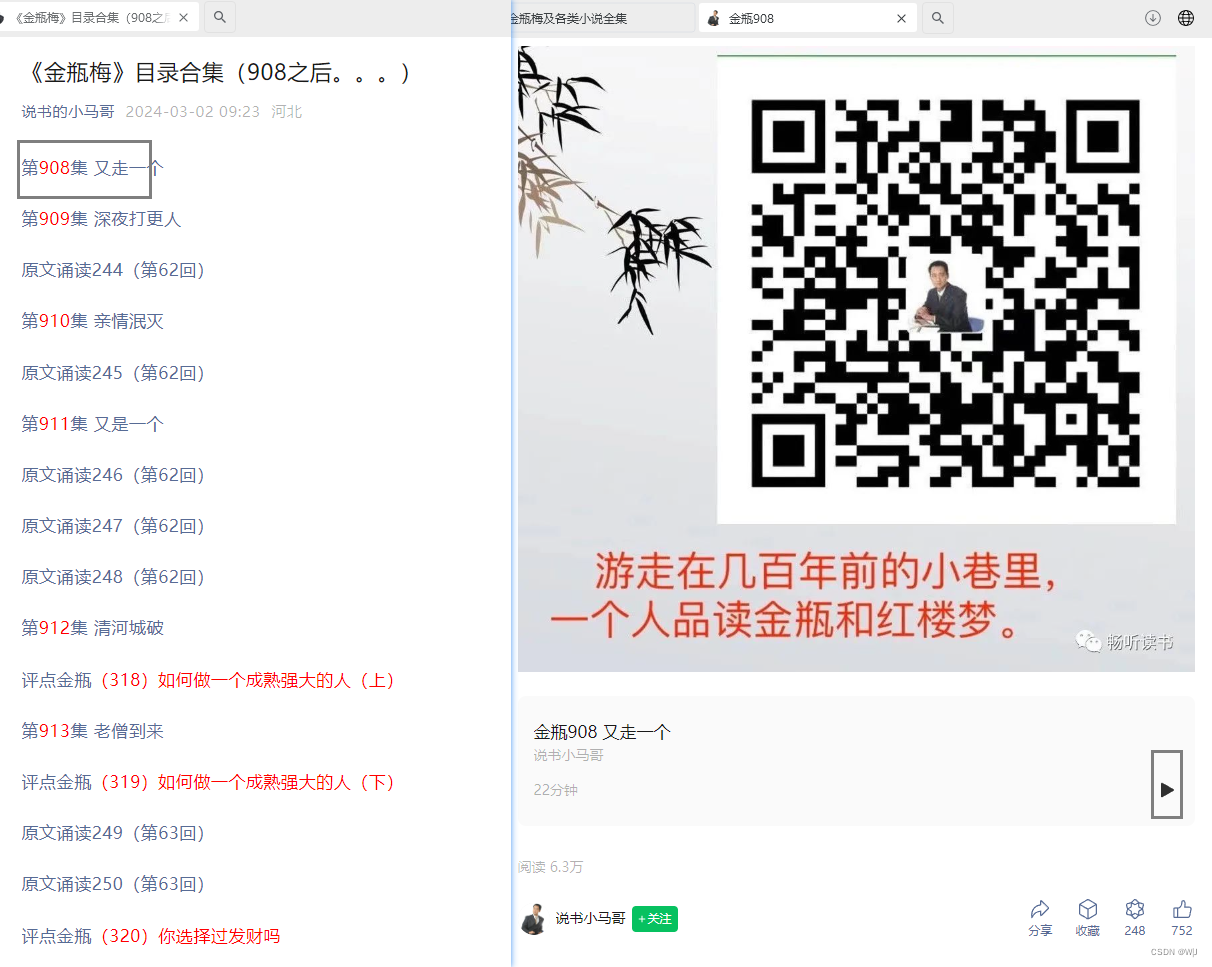
于是博主我苦练Python 大法,将音频文件下载到本地。这样就能连续的收听了。
Python 抓取
程序源码
给大家看看我的代码(需要有基础的编码能力)。如有不足之处还请批评指正。
import json
import os
import requests
from bs4 import BeautifulSoup
def extract_url(url):
# 使用requests获取网页内容
response = requests.get(url)
json_array = []
# 检查请求是否成功
if response.status_code == 200:
# 使用BeautifulSoup解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 查找所有的<a>标签
a_tags = soup.find_all('a')
# 说书
storytelling = []
# 点评
comment_on = []
# 原文诵读
original_text = []
# 遍历所有的<a>标签
for tag in a_tags:
# 获取标签内的文本
text = tag.get_text()
# 获取href属性的值
href = tag.get('href')
# 数据分组
name = tag.get_text()
if name.startswith("第"): # 判断是否以"第"开头
storytelling.append({"name": name, "href": href})
elif name.startswith("评点"): # 判断是否以"评点"开头
comment_on.append({"name": name, "href": href})
elif name.startswith("原文"): # 判断是否以"原文"开头
original_text.append({"name": name, "href": href})
json_array = json.dumps([storytelling, comment_on, original_text])
else:
print(f"Failed to retrieve the webpage. Status code: {response.status_code}")
print(f"html 解析完毕,数据共有 {len(storytelling) + len(comment_on) + len(original_text)}")
return json_array
def get_download_url(url):
# 使用requests获取HTML内容
response = requests.get(url)
html_content = response.text
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(html_content, 'html.parser')
# 找到所有的<mp>标签
mp_tags = soup.find_all('mpvoice')
# 遍历这些标签,找到含有 voice_encode_fileid 属性的标签
for mp_tag in mp_tags:
if mp_tag.has_attr('voice_encode_fileid'):
# 获取该属性的值
voice_encode_fileid = mp_tag['voice_encode_fileid']
return voice_encode_fileid
def save_file(audio_name, audio_url, progress):
if audio_url is None:
return
# 检查文件是否存在
# 打开文件准备写入二进制内容
mp3_file = "E:\\Users\\Music\\the_golden_lotus\\comment_on\\" + audio_name + ".mp3"
if not os.path.exists(mp3_file):
# 发送GET请求获取音频文件内容
url = "https://res.wx.qq.com/voice/getvoice?mediaid=" + audio_url
print(url)
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 如果文件不存在,执行保存文件的操作
with open(mp3_file, 'wb') as f:
f.write(response.content)
print(f"文件 {mp3_file} 已保存,当前进度:{progress}")
else:
print(f"无法获取音频文件,状态码: {response.status_code}")
else:
# 如果文件存在,则跳过保存
print(f"文件 {mp3_file} 已存在,跳过保存.")
def main():
# 要抓取的网页URL
url = 'https://mp.weixin.qq.com/s?__biz=Mzg5MTE0OTgxMA==&mid=2247554173&idx=1&sn=85c5d5cc1822b6418534d7d90f03fd62&scene=19#wechat_redirect'
json_array = extract_url(url)
array = json.loads(json_array)
# array[0] 是评书
size = len(array[1])
for index, item in enumerate(array[1]):
href = get_download_url(item['href'])
save_file(item['name'], href, ((index + 1) / size))
# 主程序
if __name__ == '__main__':
main()爬取思路
打开 古典名著有声小说目录合集,分析其html,
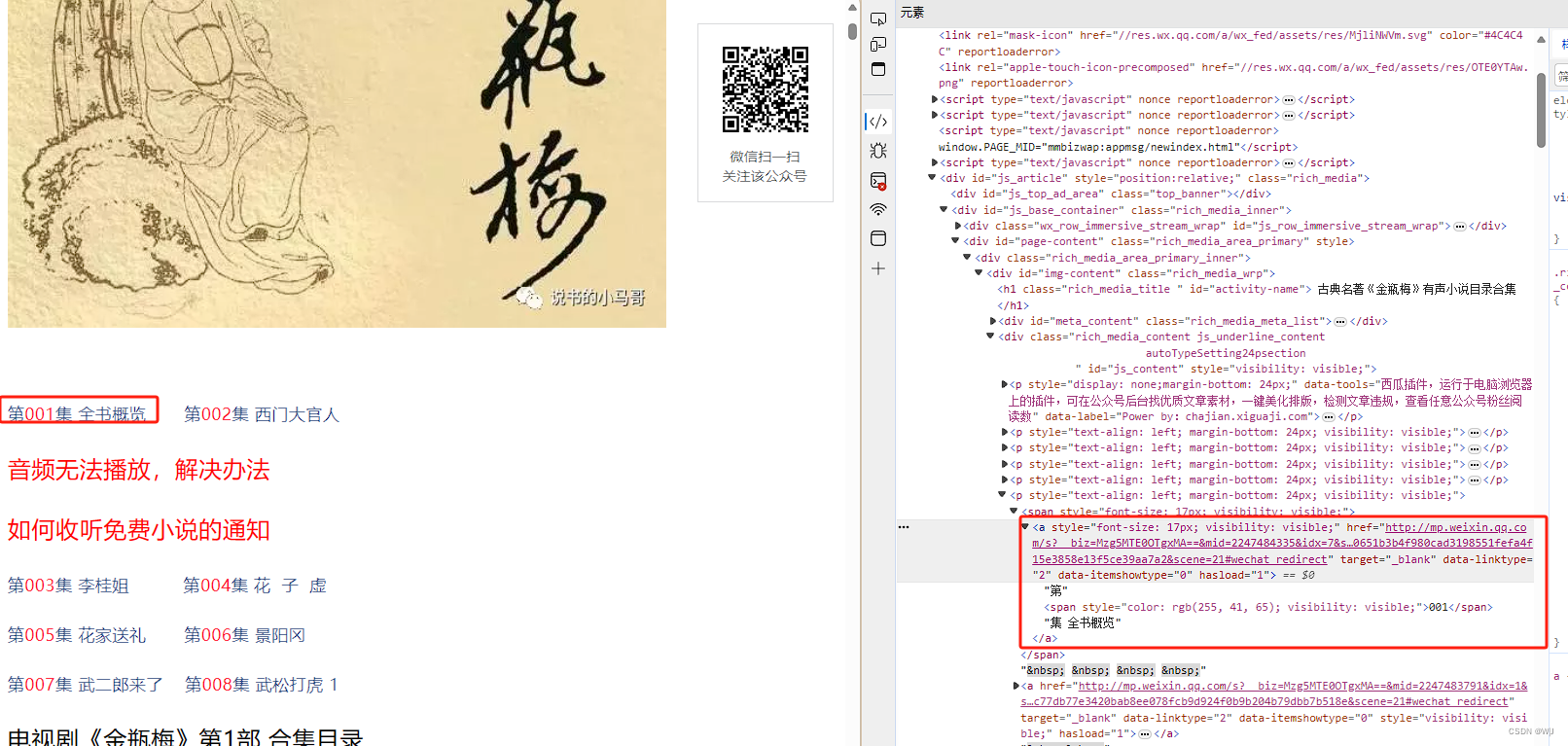
其音频名称是<a> 标签内的文字,音频的名称大致分为四类 "第 [] 集 ...","原文...","评点....","其他" 我们按照此方法分类,分别保存 音频的名称和<a>标签内的href,然后依次请求 <a>标签内的href,继续分析html
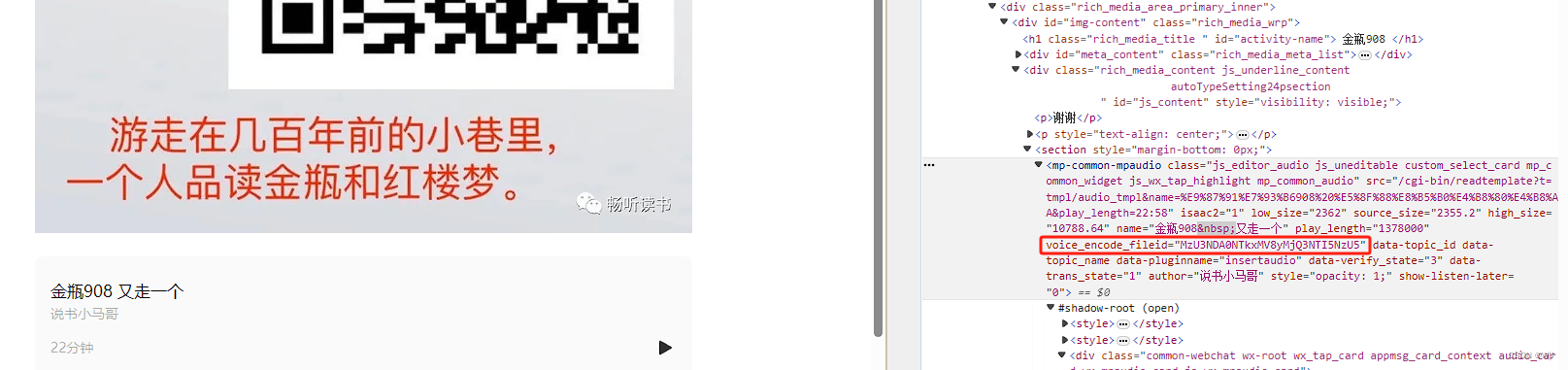
播放按钮中 mpvoice 标签内的 voice_encode_fileid 属性即是 音频文件 的 mediaid。
我们就可以请求 https://res.wx.qq.com/voice/getvoice?mediaid= ‘mediaid’ 然后保存其响应的content即可

在线代码运行项目
 https://lightly.teamcode.com/project/join?projectId=587288812335828994&code=3c968608
https://lightly.teamcode.com/project/join?projectId=587288812335828994&code=3c968608后续补充云盘地址...


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









