






第一部分 Hadoop与spark的安装与配置实验
-
VMware安装Ubuntu,配置虚拟机
-
Java环境与Hadoop配置
-
spark安装
-
环境变量配置,没有的就补充上
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH #顶部 export HADOOP_HOME=/usr/local/hadoop export HADOOP_OPTS=-Djava.library.path=$HADOOP_HOME/lib export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH export SPARK_HOME=/usr/local/spark export PATH=$SPARK_HOME/bin:$PATH export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH #底部 -
配置Spark和Hadoop,确保Spark可以找到Hadoop的配置文件。将Hadoop的配置文件复制到Spark的conf目录下
cp $HADOOP_HOME/etc/hadoop/core-site.xml $SPARK_HOME/conf/ cp $HADOOP_HOME/etc/hadoop/hdfs-site.xml $SPARK_HOME/conf/
第二部分 HDFS的配置、启动和使用
- HDFS使用教程:大数据技术原理与应用 第三章 分布式文件系统HDFS 学习指南
-
向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件;
# hdfs dfs -test 是用来测试文件或目录的命令。 # -e 参数表示测试文件或目录是否存在 # hdfs dfs -copyFromLocal 是用来从本地文件系统复制文件到 HDFS 的命令。 # -f 参数表示强制覆盖目标文件(如果它已经存在)。 if $(hdfs dfs -test -e text.txt); then $(hdfs dfs -appendToFile /home/hadoop/MapReduce/myLocalFile.txt text.txt); else $(hdfs dfs -copyFromLocal -f /home/hadoop/MapReduce/myLocalFile.txt text.txt); fi -
从HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名;
if $(hdfs dfs -test -e file:///home/hadoop/MapReduce/text.txt); then $(hdfs dfs -copyToLocal text.txt /home/hadoop/MapReduce/text1.txt); else $(hdfs dfs -copyToLocal text.txt /home/hadoop/MapReduce/text.txt); fi -
将HDFS中指定文件的内容输出到终端中;
hdfs dfs -cat text.txt -
显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息;
# -h 以更人性化(human-readable)的格式显示文件大小 hdfs dfs -ls -h text.txt -
给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息;
# 参数解读: # -R 目录操作 hdfs dfs -ls -R -h /user/hadoop -
提供一个HDFS内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录不存在,则自动创建目录;
# 如果存在就创建文件,否则同时创建目录与文件 # -p 参数允许用户创建目录及其不存在的父目录。具体来说,如果指定的目录路径中某些目录不存在,-p 参数将自动创建这些目录,确保指定的整个目录路径都会被创建。 if $(hdfs dfs -test -d dir1/dir2); then $(hdfs dfs -touchz dir1/dir2/filename); else $(hdfs dfs -mkdir -p dir1/dir2 && hdfs dfs -touchz dir1/dir2/filename); fi # 删除文件 hdfs dfs -rm dir1/dir2/filename # 删除目录 hdfs dfs -rm -r dir1 -
提供一个HDFS的目录的路径,对该目录进行创建和删除操作。创建目录时,如果目录文件所在目录不存在则自动创建相应目录;删除目录时,由用户指定当该目录不为空时是否还删除该目录;
# 创建目录 hdfs dfs -mkdir -p dir1/dir2 # 删除目录(如果目录非空则会提示not empty,不执行删除) # 以下指令的执行结果: # rmdir: `dir1/dir2': Directory is not empty hdfs dfs -rmdir dir1/dir2 # 强制删除目录: # 在rm指令和cp指令中,-r参数和-R参数是可以互换使用的 hdfs dfs -rm -R dir1/dir2 -
向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾;
# 追加到文件末尾: # local.txt应该替换为本地目录中的本地文件 # 示例:hdfs dfs -appendToFile ~/MapReduce/text.txt text.txt hdfs dfs -appendToFile local.txt text.txt # 追加到文件开头: # (由于没有直接的命令可以操作,方法之一是先移动到本地进行操作,再进行上传覆盖) # get指令是将hdfs中制定的文件保存在本地的位置,并且不会删除text的内容 # 相关参数解读: # -f 覆盖目标 # -p 保留文件属性 # -crc 启动文件crc校验 hdfs dfs -get text.txt cat text.txt >> local.txt hdfs dfs -copyFromLocal -f text.txt text.txt -
删除HDFS中指定的文件;
# 删除文件 hdfs dfs -rm dir1/dir2/filename -
删除HDFS中指定的目录,由用户指定目录中如果存在文件时是否删除目录;
# 删除目录(如果目录非空则会提示not empty,不执行删除) # 以下指令的执行结果: # rmdir: `dir1/dir2': Directory is not empty hdfs dfs -rmdir dir1/dir2 # 强制删除目录: # 在rm指令和cp指令中,-r参数和-R参数是可以互换使用的 hdfs dfs -rm -R dir1/dir2 -
在HDFS中,将文件从源路径移动到目的路径。
hdfs dfs -mv text.txt text2.txt
第三部分 WordCount实验
-
启动spark
cd /usr/local/spark bin/spark-shell -
使用命令行执行scala代码,注意双引号格式,在spark-shell中读取Linux系统本地文件file:///home/stu/software/hadoop/README.txt, 统计“Hadoop”单词的个数。
val sc = new SparkContext() /* 但实际上,如果你是在命令行中使用 Scala 和 Spark 的交互式 shell,那么 Spark shell 会自动为你创建 SparkContext,并命名为 sc。在这种情况下,你无需手动创建 SparkContext,因为 Spark shell 已经帮你做好了初始化。 */ val textFile = sc.textFile("file:///usr/local/hadoop/README.txt") textFile.count()输出结果如下:

val linesWithHadoop = textFile.filter(line => line.contains("Hadoop")) linesWithHadoop.count()输出结果如下:

-
上面两条语句可以通过链式操作合并为:
val linesCountWithHadoop = textFile.filter(line => line.contains("Hadoop")).count()
-
在spark-shell中读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;
如果文件不存在的创建:
if $(hdfs dfs -test -e user/hadoop/test.txt); then $(hdfs dfs -appendToFile /home/hadoop/MapReduce/myLocalFile.txt test.txt); else $(hdfs dfs -copyFromLocal -f /home/hadoop/MapReduce/myLocalFile.txt test.txt); fival lines = sc.textFile("hdfs://localhost:9000/user/hadoop/test.txt") lines.count() -
使用命令行来实现wordcount,即统计文件中各个单词的计数:
val sc = new SparkContext() val textFile = sc.textFile("file:///usr/local/hadoop/README.txt") val wordCounts = textFile.flatMap(line => line.split("")).map(word => (word,1)).reduceByKey((a,b) => a+b) wordCounts.collect() wordCounts.foreach(println)
-
用scale语言实现wordcount
-
WordCount程序参考代码1:
import java.io.File import scala.io.Source object WordCountApp { def main(args: Array[String]): Unit = { //文件路径 val filePath = "file:///usr/local/hadoop/README.txt" val codec = "utf-8" //打开文件 val file = Source.fromFile(filePath, codec) val wc = file.getLines().flatMap(_.split("\t")).toList.map((_, 1)).groupBy((_._1)).mapValues(_.size) println(wc) // 关闭文件 file.close() } } -
WordCount程序参考代码2:
import java.io.File import scala.io.Source object WordCountApp { def main(args: Array[String]): Unit = { //文件路径 val filePath = "file:///usr/local/hadoop/README.txt" val codec = "utf-8" //打开文件 val file = Source.fromFile(filePath, codec) val wc = file.getLines().flatMap(_.split("\t")).toList.map((_, 1)).groupBy((_._1)).mapValues(_.size) println(wc) // 关闭文件 file.close() } }
- 试一试,是否还有其他的实现方式?
第四部分 PageRank实验
留一个参考链接:PageRank 算法在Hadoop和Spark上的实现-CSDN博客
采用的方案是在eclipse软件中编写Java工程文件实现PageRank。具体步骤如下。
-
安装eclipse
首先从官网下载eclipse软件(官网下载地址:Eclipse Downloads | The Eclipse Foundation),注意需要Download Package,具体的版本是linux x86_64。

接下来的操作在linux中完成。先放一份参考链接:使用Eclipse编译运行MapReduce程序)
首先将刚刚下载的包解压缩,放置在希望的安装目录(事实上,正是因为在ubuntu直接下载的eclipse安装在了只读的系统位置,才需要自主安装到所期望的位置的):
sudo tar -zxvf ~/下载/eclipse.tar.gz -C /usr/lib   -
安装 Hadoop-Eclipse-Plugin
要在 Eclipse 上编译和运行 MapReduce 程序,需要安装 hadoop-eclipse-plugin,可下载 Github 上的插件winghc/hadoop2x-eclipse-plugin,解压后将 release 中的 hadoop-eclipse-kepler-plugin-2.6.0.jar (还提供了 2.2.0 和 2.4.1 版本)复制到 Eclipse 安装目录的 plugins 文件夹中,运行
eclipse -clean重启 Eclipse 即可(添加插件后只需要运行一次该命令,以后按照正常方式启动就行了)。unzip -qo ~/下载/hadoop2x-eclipse-plugin-master.zip -d ~/下载 # 解压到 ~/下载 中 sudo cp ~/下载/hadoop2x-eclipse-plugin-master/release/hadoop-eclipse-plugin-2.6.0.jar /usr/lib/eclipse/plugins/ # 复制到 eclipse 安装目录的 plugins 目录下 /usr/lib/eclipse/eclipse -clean # 添加插件后需要用这种方式使插件生效 -
配置Hadoop-Eclipse-Plugin
注意这部分的内容:
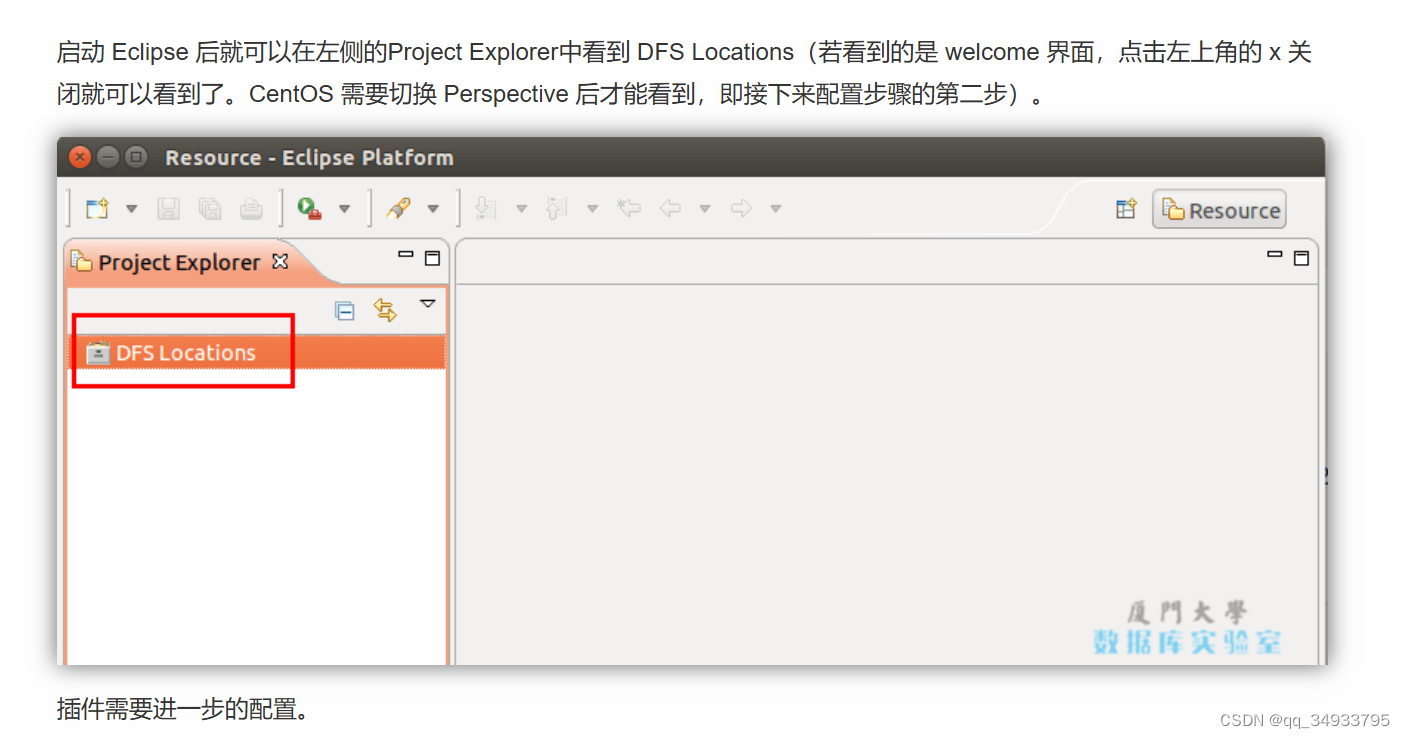
经实际操作,ubuntu实际上也需要切换才能看到,所以看不到没事,忽略这个问题。剩下的按照下述操作,也就是完成插件的进一步配置就可以了。完成之后应该能看到,还看不到就要重新配置了:(
-
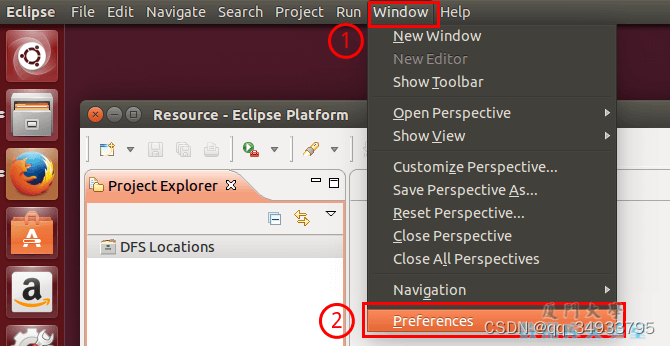
第一步:选择 Window 菜单下的 Preference。
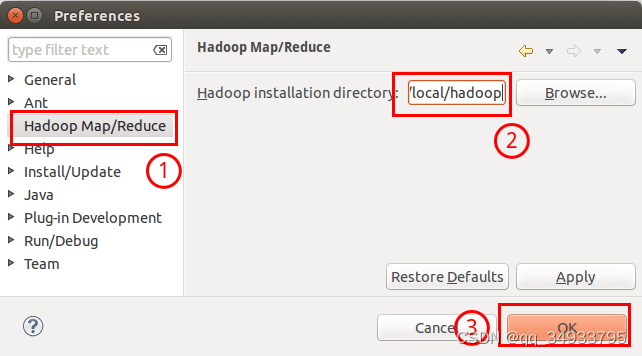
此时会弹出一个窗体,窗体的左侧会多出 Hadoop Map/Reduce 选项,点击此选项,选择 Hadoop 的安装目录(如/usr/local/hadoop,Ubuntu不好选择目录,直接输入就行)。
-
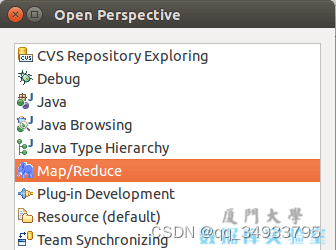
第二步:切换 Map/Reduce 开发视图,选择 Window 菜单下选择 Open Perspective -> Other(CentOS 是 Window -> Perspective -> Open Perspective -> Other),弹出一个窗体,从中选择 Map/Reduce 选项即可进行切换。
-
第三步:建立与 Hadoop 集群的连接,点击 Eclipse软件右下角的 Map/Reduce Locations 面板,在面板中单击右键,选择 New Hadoop Location。
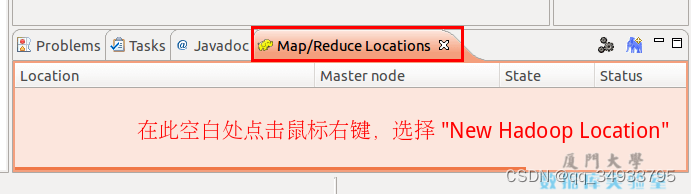
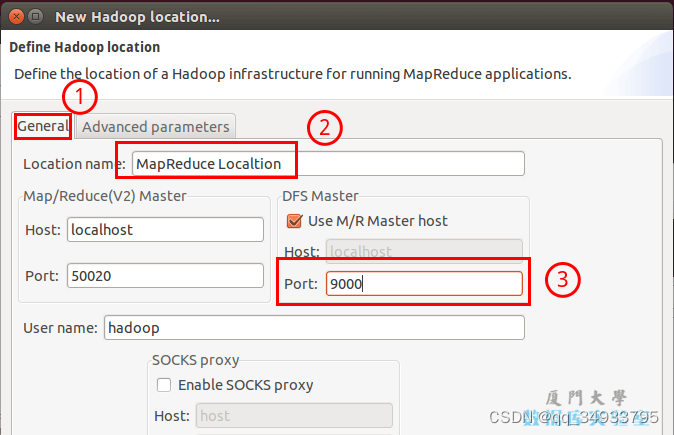
在弹出来的 General 选项面板中,General 的设置要与 Hadoop 的配置一致。一般两个 Host 值是一样的,如果是伪分布式,填写 localhost 即可,另外我使用的Hadoop伪分布式配置,设置 fs.defaultFS 为 hdfs://localhost:9000,则 DFS Master 的 Port 要改为 9000。Map/Reduce(V2) Master 的 Port 用默认的即可,Location Name 随意填写。
最后的设置如下图所示:
-
点击 finish,Map/Reduce Location 就创建好了。
-
-
在 Eclipse 中操作 HDFS 中的文件
直接看博客(其实不需要看也懂所以不说明了)
Tips: HDFS 中的内容变动后,Eclipse 不会同步刷新,需要右键点击 Project Explorer中的 MapReduce Location,选择 Refresh,才能看到变动后的文件。
-
创建MapReduce项目
基本的操作都是一样的,但有一点要注意:
创建class的时候,Package 处需要填写 org.apache.hadoop.examples。
剩下的就是枯燥的写代码时间了。忽略。
-
运行MapReduce项目
- 在运行 MapReduce 程序前,还需要执行一项重要操作(也即配置文件解决参数设置问题):将 /usr/local/hadoop/etc/hadoop 中将有修改过的配置文件(如伪分布式需要 core-site.xml 和 hdfs-site.xml),以及 log4j.properties 复制到 PageRank 项目下的 src 文件夹中:
cp /usr/local/hadoop/etc/hadoop/core-site.xml ~/eclipse-workspace/PageRank/src cp /usr/local/hadoop/etc/hadoop/hdfs-site.xml ~/eclipse-workspace/PageRank/src cp /usr/local/hadoop/etc/hadoop/log4j.properties ~/eclipse-workspace/PageRank/src-
之后刷新,要记得手动刷新项目,它不自动刷新:(
-
点击工具栏中的 Run 图标,或者右键点击 Project Explorer 中的 PageRank.java,选择 Run As -> Run on Hadoop,就可以运行 MapReduce 程序了。不过由于没有指定参数,运行时会提示 "Usage: wordcount ",需要通过Eclipse设定一下运行参数。
-
右键点击java文件,选择 Run As -> Run Configurations,在此处可以设置运行时的相关参数(如果 Java Application 下面没有 WordCount,那么需要先双击 Java Application)。切换到 “Arguments” 栏,在 Program arguments 处填写所需的输入输出文件。在这里就是"data.txt PageRank_out Sort_out"这三个。实际情况下,根据文件中所需的进行修改即可。
-
结果分析
-
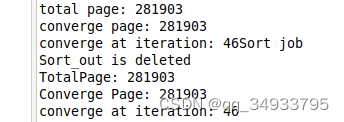
运行数据量很大,需要等大概半小时。完成后显示结果如下:
-
数据以PageRank_out文件夹中的信息保存了每一次迭代的日志信息,以Sort_out文件夹中的信息保存了最终按照权值排序的结果。Sort中结果如下:

- 可以观察到,大的值和小的值之间的差距是好几个数量级的。实验一第四部分完成:)
-
















 4427
4427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











