







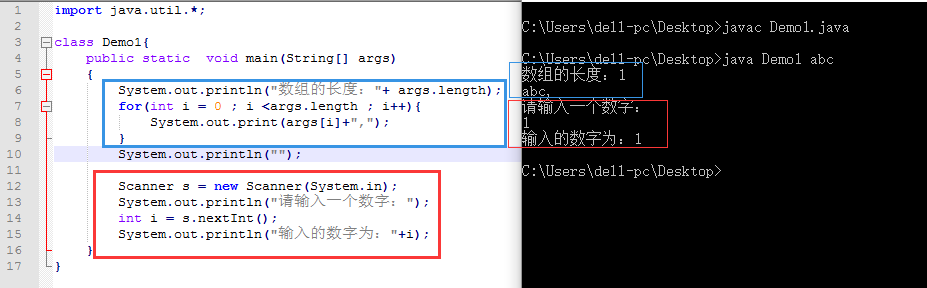
一、main函数的详解:
public static void main(String[] args){}1、public : 公共的。 权限是最大,在任何情况下都可以访问。 如果使用private 等,一旦超出了方法范围等就不能访问了 。
原因: 为了保证让jvm在任何情况下都可以访问到main方法。
2、static: 静态。静态可以让jvm调用main函数的时候更加的方便。不需要通过对象调用。
不使用static修饰带来的麻烦:
1)需要创建对象才能调用main方法
2)jvm不知道如何创建对象,因为创建对象时,有些构造方法是带参数的,而jvm不知道传递什么参数。
3、void: 没有返回值。 因为返回的数据是给jvm,而jvm使用这个数据是没有意义的。所以就不要了。
4、main: 函数名。
注意: main并不是关键字,只不过是jvm能识别的一个特殊的函数名而已。
5、arguments :担心某些程序在启动需要参数。

对比scanner:
二、单例设计模式:
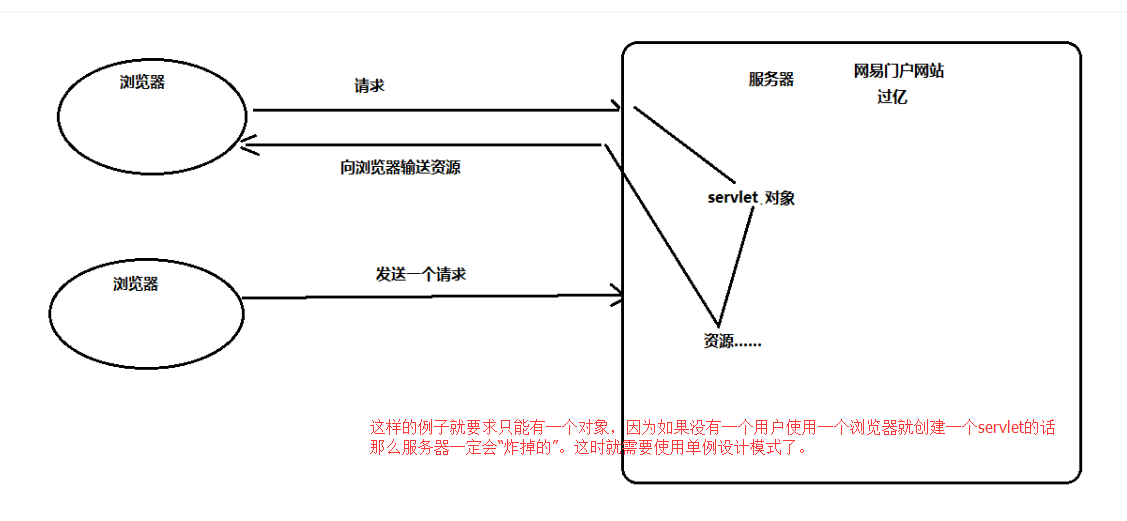
1、单例设计模式作用:保证一个类在内存中只有一个对象。
2、模式定义:模式就是解决一类问题的固定步骤 。
3、模式的概念最早起源于建筑行业,建房子的步骤都是一样子:
打地基—–> 浇柱子——->盖楼面———>砌墙———>封顶—->装修—–入住
4、软件行业中23种设计模式:
1)单例设计模式 2)模板设计模式 3)装饰者设计模式 4)观察者设计模式
5)工厂设计模式
5、单例设计模式分类及步骤:
1)饿汉单例设计模式
a)私有化构造函数。
b)声明本类的引用类型变量,并且使用该变量指向本类对象。
c)提供一个公共静态的方法获取本类的对象。
//饿汉单例设计模式 ----> 保证Single在在内存中只有一个对象。(不能私有化该类的方法。即private class Single{},这样的话其他人就无法访问这个类了)
class Single{
//声明本类的引用类型变量,并且使用该变量指向本类对象
//用static使其在内存中只存在一个s变量(即唯一对象),static的信息存储在方法区中,数据存储在方法区的静态数据共享区中
private static Single s = new Single();
//私有化构造函数
private Single(){}
//提供一个公共静态的方法获取本类的对象
//静态的原因:如果这个方法是非静态的,那么在Test中的main方法想要调用这个方法时,对象.getInstance(),但是这个方法就是要得到对象,所以必须要是静态的,类名.getInstance().
public static Single getInstance(){
return s;
}
}2)懒汉单例设计模式:
a)私有化构造函数。
b)声明本类的引用类型变量,但是不要创建对象,
c)提供公共静态的方法获取本类的对象,获取之前先判断是否已经创建了本类对象,如果已经创建了,那么直接返回对象即可,如果还没有创建,那么先创建本类的对象,然后再返回。
//懒汉单例设计模式 ----> 保证Single在在内存中只有一个对象。
class Single2{
//声明本类的引用类型变量,不创建本类的对象
//这点优于饿汉单例设计模式,节省内存
private static Single2 s;
//私有化了构造函数
private Single2(){}
//提供公共静态的方法获取本类的对象
public static Single2 getInstance(){
if(s==null){
s = new Single2();
}
return s;
}
}3)验证方法:
class Demo5
{
public static void main(String[] args)
{
Single2 s1 = Single2.getInstance();
Single2 s2 = Single2.getInstance();
System.out.println("是同一个对象吗?"+ (s1==s2));
}
}
//返回结果为true,证明了单例设计模型的可行性。3)推荐使用: 饿汉单例设计模式。 因为懒汉单例设计模式会存在线程安全问题,目前还不能保证一类在内存中只有一个对象。

三、扩展知识:
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。















 1417
1417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









