







假设现在有一个这样的需求,我们想要实时统计有多少用户访问我们的网站。一个简单的解决方案是用一个set集合来存储用户ID,然后计算任意时刻集合中不同ID的个数即为网站实时访问量。这是一种简单可行的做法,但是假如这个网页访问量很大加上随着时间推移存储集合数据所需要的内存空间越来越大,所需要的统计成本也越来越高。举个例子,假如用一个int类型来保存用户id,当有一千万用户的时候,总共需要38M内存。为了省内存我们还有另一种方案,位图法,我们用bitmap来保存数据,用户访问的时候我们就把对应的bit置1,最后统计这个bitmap总共有几个bit为1来统计访问量。这样,一千万用户就需要一千万个bit,约为1.2M大小。假如我要统计网站每天的用户访问量,那就意味着需要很多个bitmap,每个1.2M还是太大了。那有没有其它更省内存的解决方案呢?这时候我们需要另外一种算法来解决这个问题--hyperloglog算法。redis 中的hyperloglog,不管你的访问量有多大,几千万还是几个亿,最多只需要约12k内存!
首先介绍一下概率论中伯努利试验:伯努利试验(Bernoulli experiment)是指在同样的条件下重复地、相互独立地进行的一种随机试验,其特点是该随机试验只有两种可能结果:发生或者不发生。比如抛硬币,只有正面反面两种结果。
在介绍 HyperLogLog 之前,我们可以考虑这样一个游戏:不断抛硬币,直到第一次出现正面朝上,记录总共抛了多少次。
这个游戏中,假如在某次场景下,前3次都是反面,第4次正面,问这个概率是多少?这个很简单,那么相当于平均需要玩
=16次这个游戏才会出现一次这种场景。反过来说,如果某次游戏要抛到第4次才第一次出现正面朝上,那么可以推出这个游戏已经玩了16回。这个就是hyperloglog的基本原理。
然后我们用“1”来表示正面朝上,“0”表示反面朝上。用“0”,“1”组成的序列来表示某次游戏的结果,比如上面这个例子要抛4次的序列是:0 0 0 1。如果要抛5次就是:0 0 0 0 1,以此类推。
简单来看,其实 HyperLogLog 的基数统计就使用了这样的思想,通过二进制中 ‘1’出现的第一个位置来估算整体的数量。
举个例子,假设上面那个游戏一共玩了N次,其中最多的一次抛了6次硬币才结束,那么它的结果序列是:0 0 0 0 0 1。我们可以推算N=,即总共玩了64次这个游戏。
这种方法根据某次的结果来估算游戏进行的次数毫无疑问误差会比较大。我们可以对每次游戏的结果求平均值提高估算的精度。
假如依次进行时五次游戏,结果分别是:
- "0 0 1",n1=3;
- "0 1',n2=2;
- "1",n3=1;
- "0 0 0 0 1",n4=5;
- "0 1",n5=2.
如果直接按n最大的一次计算的话,,32次,误差很大。
如果我们按五次游戏的平均值来算,,
=8,精度已经提高了很多。
我们还可以进一步提高精度,上面的均值用的是算术平均,现在我们改用调和平均来算一下.调和平均计算公式如下:
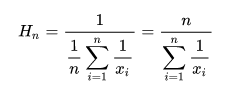
,
,精度又近了一步,由于算术平均值容易受极值影响,在一些极端场景下误差会比较大。再举一个例子,两次游戏:
- “0 0 0 0 0 0 0 0 0 0 0 0 0 0 1”,n1=15;
- "1",n2=1;
如果拿算术平均算的话是,误差非常大;如果是拿调和平均算,
,
,误差就小了很多。
关于调和平均和算术平均,再举一个例子:两个人,一个月薪1千,一个月薪十万,那么两人的算术平均工资是50500,调和平均工资是2000,可以明显看出调和平均对消除极值的影响效果更好,所以redis中hyperloglog的实现也是用的调和平均。
我们来进一步优化我们的方案,假设进行了n次游戏,然后把n次游戏分成若干各组,然后根据每个组中的最大抛硬币次数来估算n的值。
比如,一共进行16次游戏,分成2个组,然后估算游戏次数:
第一组8次分别是:“1”, “0 1”,“01” ,“0 01”,"1","0 0 1","0 1","1"那么最大抛币次数是3;
第二组分别是“01”,“0 0 0 01”,“1”, “0 1”,“0 01” ,“0 1”,“0” “01”,最大抛币次数是5.
然后对3和5计算平均值是4,估算结果是。当然,当数据量比较少的时候误差可能会比较大。根据伯努利大数定律,辛钦大数定律,切比雪夫大数定律,样本越多均值误差就越小。在redis的实现中,是总共分为16384个组。下面开始看一下redis中是如何实现的。
redis实现
redis中是通过pfadd 命令将所有元素参数添加到 HyperLogLog 数据结构中。假设用户ID为123456789的用户访问了www.HyperLogLog.com这个网站.我们可以用一下命令来进行统计
pfadd www.HyperLogLog.com 123456789然后redis开始对这个用户进行一次伯努利试验,具体做法通过一个hash函数来对123456789生成一个64bit的值,这里先假设是8888886666666660000,那么他的二进制表示是
0111101101011011101010110101001111110111010111110101000010100000
redis的hyperloglog数据结构中共有16384个桶来保存每次伯努利试验的结果。16384=,因此需要14个bit来保存 。对于每次hash生成的64位的整形数,取高12位来作为hash桶索引,剩下的50个bit用来作为伯努利试验结果。
上面这个例子中,高12位是0111 1011 0101 10,十进制是7894。低50位的伯努利试验结果中第一次出现1是在第6位,那么它的意思是说这次试验是属于7894组,那么我们就要把这次试验结果6保存到哈希表第7894个桶中。当要把试验结果保存的时候,我们要先看一下这次试验结果6是不是比桶中保存的结果大,只有大于才保存,因为我是用各个分组中最大的结果来进行求均值。对于每次试验,结果最大就是50,,就是用只需要用6个bit就可以保存这个试验结果。所以redis是用一个长度为16384*6个bit的数组来保存所有的试验结果,大小约为12k字节。
考虑这样一种场景,如果访问量只有几百几千,其实是不需要那么大空间来因为,因为这种情况下16384个桶会有很多桶是空的。比如有一千个连续的桶是空的,那么原本需要6000个bit去表示,占750字节。在redis里边其实只需两个字节就能保存这个信息。
| ZERO | 一个字节大小,高两位固定为00,剩下六位可以表示64个连续为0的空桶, |
| XZERO | 两个字节大小,高两位固定为01,剩下的14位可以表示16384个连续的空桶 |
| VAL | 一个字节,高一位固定为1,中间五位表示值大小,剩下两位表示连续几个相同值的桶 |
根据上表,如果要表示连续1000个空桶,可以用XZERO类型表示:01 000011 1110 1000,也就是0x01 00 03e8这个数。
以上只是hyperloglog的大致流程,redis在实际计算的时候是会加上一些修正的。
这个网站可以看hyperloglog的演示动画,可以加深理解:hyperloglog















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









