









跳表是建立在普通有序链表之上的一种一种概率数据结构。可以理解为加了索引的有序链表。
这里打个比方,假如把普通有序链表比作是普通公交车,因为每个公交站都停一下所以如果站比较多得时候肯定会很慢;那么跳表就相当于是特快大巴,它不会每个站都停,而是会跳过一些站点每隔几个站才停一下,显然特快大巴速度更快。
我们在一个有序链表中搜索一个元素的时候,即使链表已经排好序但是也不能使用二分查找法,必须挨个节点去遍历,算法复杂度是O(n),性能太低。而跳表就是为了解决这个问题, 它的搜索复杂度能达到O(log n),能够和红黑树相媲美。
跳表是在原始有序链表上构建一些索引层 ,索引层也是排好序的,每个索引层只包含一部分元素。之所以要加索引层是为了能使用二分查找原理来加速查找性能。下图是跳表的示意图,跳表每个结点不只包含一个指针,还可能包含若干个指向后继结点的指针,这样就可以跳过一些不必要的结点,从而加快查找、删除等操作。这些多出来的额外指针就是索引层。
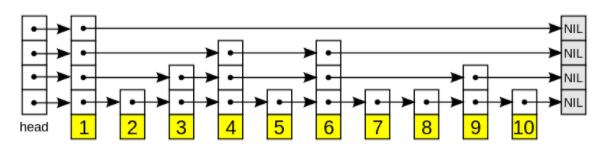
标准跳表有以下几个特点:
- keys是排好序的
- 包含n个元素的跳表层高是log n
- 每个高层包含的元素数量是下层的1/2
- 每层都有一个头节点和尾节点
- 节点的大小是可变,包含1到log n个指针,每个节点具体包含几个指针是随机的
查找

当查找k时:
- 如果 K = Key,搜素结束
- 如果 K < Next Key,进入下一层搜素
- 如果 K >= Next Key,往右到下一个节点
现在来简单看一下跳表的搜索过程,我们要在下面这个跳表中查找71。这个跳表总共有四层链表,先从最高的索引层开始,每一层的末尾填充的是一个无限大的值。

查找96:

插入


删除

















 307
307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









