







mybatis缓存机制一
mybatis提供了对缓存的支持,分为一级缓存和二级缓存
一级缓存
一级缓存在mybatis中是默认开启的,是以hashMap为数据结构的缓存形式。
如何验证一级缓存?
以下示例通过两次(也可以是多次,两次就够了)查询同一条数据,来查看日志是否是进行了两次数据库查询。
//验证 一级缓存
@Test
public void FirstLevelCache() {
//第一次查询User
User user1 = mapper.findUserById(1);
//第二次查询User
User user2 = mapper.findUserById(1);
System.out.println(user2 == user3);
sqlSession.close();
}
日志打印:
15:10:28,480 DEBUG PooledDataSource:406 - Created connection 903268937.
15:10:28,480 DEBUG JdbcTransaction:101 - Setting autocommit to false on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@35d6ca49]
15:10:28,484 DEBUG findUserById:159 - ==> Preparing: select * from user where id= ?
15:10:28,524 DEBUG findUserById:159 - ==> Parameters: 1(Integer)
15:10:28,545 DEBUG findUserById:159 - <== Total: 1
true
从以上日志打印(debug模式)上看从创建数据库连接开始,就只有第一次查询的时候进行了日志打印,第二次就直接从内存里直接取数据,不进行数据库查询。并且查询后的两个对象地址值为true,可见是内存中同一对象。
如何刷新一级缓存?
以下示例通过两次查询中间穿插一次更新操作。
//验证 一级缓存
@Test
public void FirstLevelCache() {
//第一次查询User
User user1 = mapper.findUserById(1);
//更新用户
User user = new User();
user.setUsername("zhansan");
user.setId(2);
mapper.update(user);
sqlSession.commit();
//第二次查询User
User user2 = mapper.findUserById(1);
//第3次查询User
User user3 = mapper.findUserById(1);
System.out.println(user1 == user2);
System.out.println(user2 == user3);
sqlSession.close();
}
第一次查询日志
15:06:38,336 DEBUG PooledDataSource:406 - Created connection 424732838.
15:06:38,337 DEBUG JdbcTransaction:101 - Setting autocommit to false on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@1950e8a6]
15:06:38,340 DEBUG findUserById:159 - ==> Preparing: select * from user where id= ?
15:06:38,386 DEBUG findUserById:159 - ==> Parameters: 1(Integer)
15:06:38,417 DEBUG findUserById:159 - <== Total: 1
更新操作日志
15:06:38,419 DEBUG update:159 - ==> Preparing: update user set username= ? where id = ?
15:06:38,419 DEBUG update:159 - ==> Parameters: zhansan(String), 2(Integer)
15:06:38,421 DEBUG update:159 - <== Updates: 1
15:06:38,422 DEBUG JdbcTransaction:70 - Committing JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@1950e8a6]
第二次查询日志
15:06:38,424 DEBUG findUserById:159 - ==> Preparing: select * from user where id= ?
15:06:38,424 DEBUG findUserById:159 - ==> Parameters: 1(Integer)
15:06:38,426 DEBUG findUserById:159 - <== Total: 1
输出结果
false
true
从以上日志发现,如果两次查询中间有更新操作,第二次查询就会去查询数据库,可见更新操作刷新了缓存。 这里有一个注意的点,更新操作之后进行了事务提交,如果只做更新操作不进行事务提交,缓存依旧被刷新。
注意:当然缓存的刷新不止是更新才会有,插入、删除、回滚、事务提交、关闭sqlsession(close方法)、手动刷新(clearCache方法)等操作都会进行一级缓存的刷新。
一级缓存是什么?在什么时候创建的?一级缓存的工作流程是什么样的
我们从SqlSession这个接口入手去看,看看这个接口中有哪些方法是跟一级缓存有关系的.
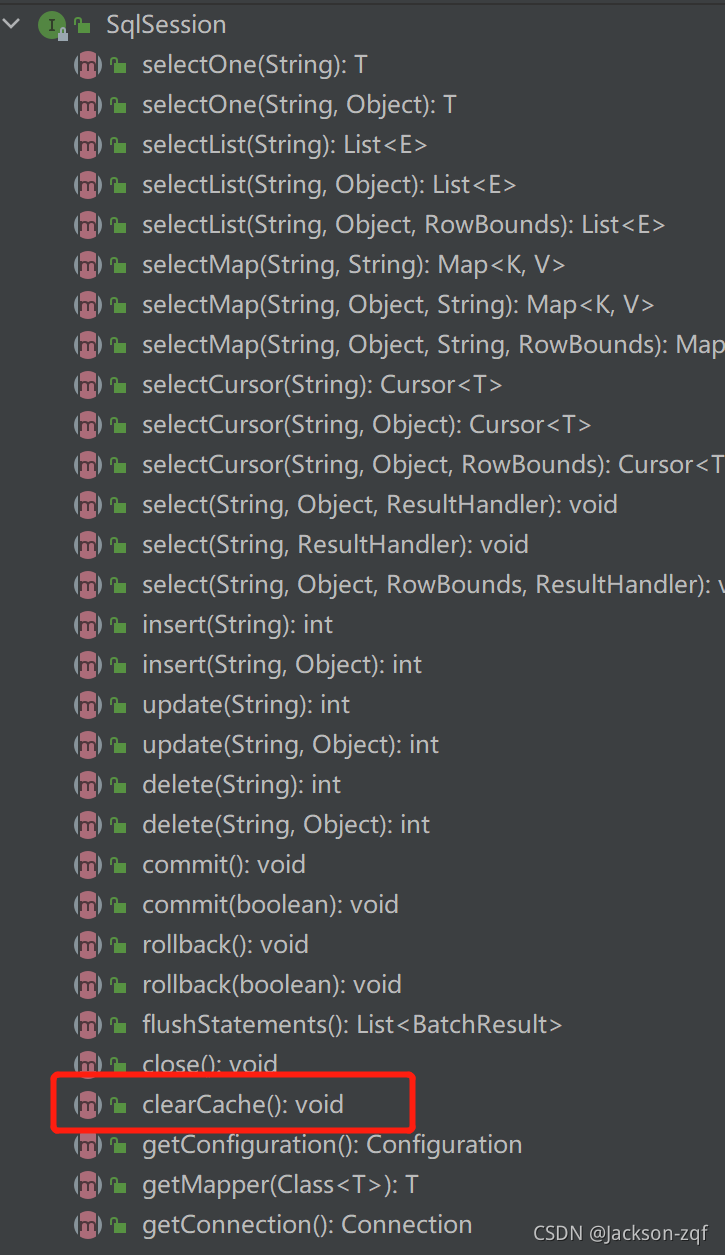
从上面的图中可以看到SqlSession中只有 clearCache方法跟缓存有关系。
顺着这个方法找下去,找到其实现类DefaultSqlSession(这里只copy部分代码):
private final Executor executor;
@Override
public void clearCache() {
executor.clearLocalCache();
}
这里的方法是调用了执行器Executor的方法,进到实现类BaseExecutor中:
protected PerpetualCache localCache;
@Override
public void clearLocalCache() {
if (!closed) {
localCache.clear();
localOutputParameterCache.clear();
}
}
这里的loacalCache.clear()方法调用了 PerpetualCache 的方法,再来看看PerpetualCache这个类:
private Map<Object, Object> cache = new HashMap<Object, Object>();
@Override
public void clear() {
cache.clear();
}
从PerpetualCache来看,mybatis将一级缓存封装成了PerpetualCache对象,PerpetualCache类中使用HashMap的数据结构来存储数据。
所以从以上源码的跟踪,可以得出mybatis的一级缓存底层就是个HashMap数据结构。
再让我们来看看这个一级缓存是如何创建的的,在执行器Executor中,
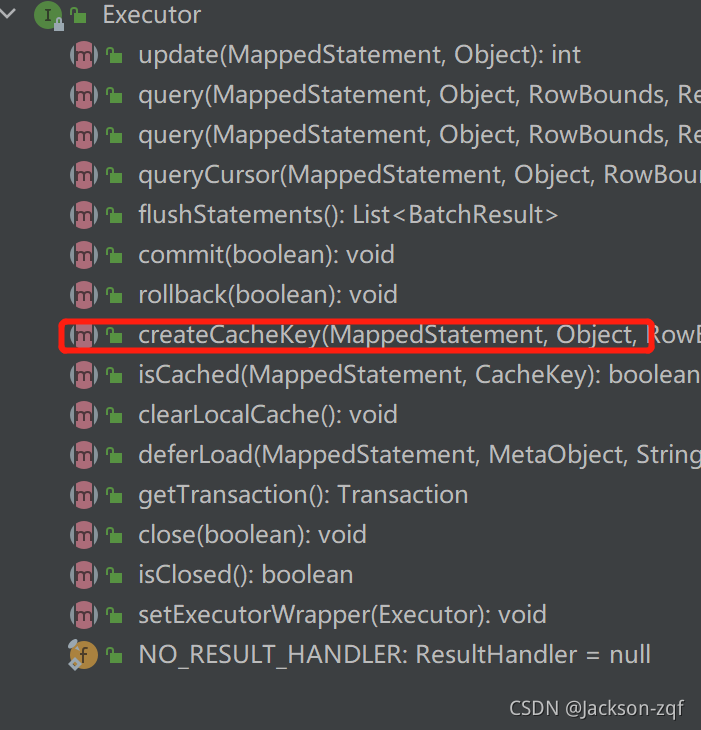
从图中可以看出有一个createCacheKey方法,很明显是创建cacheKey的,也就是hashmap中的key的值的创建。
下面来看看createCacheKey方法:
从方法定义上看是一共有四个入参
MappedStatement ms: MappedStatement对象,其封装了id、sql、Configuration等信息。
Object parameterObject: 执行sql传入的参数。
RowBounds rowBounds: 分页对象,封装了分页的相关信息
BoundSql boundSql: sql对象,封装sql语句和参数等信息。
@Override
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if (closed) {
throw new ExecutorException("Executor was closed.");
}
//创建了一个cacheKey,这个cachekey就是一级缓存的key值。
CacheKey cacheKey = new CacheKey();
//下面的代码逻辑都是对cachekey的一个赋值
cacheKey.update(ms.getId());
cacheKey.update(rowBounds.getOffset());
cacheKey.update(rowBounds.getLimit());
cacheKey.update(boundSql.getSql());
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
// mimic DefaultParameterHandler logic
for (ParameterMapping parameterMapping : parameterMappings) {
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
cacheKey.update(value);
}
}
if (configuration.getEnvironment() != null) {
// issue #176
cacheKey.update(configuration.getEnvironment().getId());
}
return cacheKey;
}
从上面的源码中,还有一个很重要的对象就是Cache对象,这个对象就是一级缓存作为hashmap的key值。从代码中可以看出多次调用了cacheKey.update的方法, 让我们看看这个update方法:
//定义一个集合对象,这个对象就是所谓的一级缓存的key值。
private transient List<Object> updateList;
public CacheKey() {
this.hashcode = DEFAULT_HASHCODE;
this.multiplier = DEFAULT_MULTIPLYER;
this.count = 0;
//这个集合就是个ArrayList
this.updateList = new ArrayList<Object>();
}
public void update(Object object) {
int baseHashCode = object == null ? 1 : ArrayUtil.hashCode(object);
count++;
checksum += baseHashCode;
baseHashCode *= count;
hashcode = multiplier * hashcode + baseHashCode;
//传入的参数都被添加到这个集合中
updateList.add(object);
}
从上述源码分析可以得出一级缓存的key值,其底层就是个ArrayList,通过CacheKey这个类封装之后使用。
分析完一级缓存是如何创建的,在来分析一下一级缓存何时创建的,在本文介绍一级缓存中,已经验证了一级缓存的存在,所以我们来思考一下,是不是在执行查询结果后,mybatis将查询结果返回之前已经将数据放到了缓存中,这个思路没有问题,而mybatis的curd操作都是在执行器Executor中进行,所以我们从Executor的query方法入手,看看何时创建的缓存。
BaseExecutor类(只摘取部分分析的代码):
//一级缓存对象
protected PerpetualCache localCache;
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
//根据参数获取BoundSql对象
BoundSql boundSql = ms.getBoundSql(parameter);
//创建CacheKey
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
@SuppressWarnings("unchecked")
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
//结果集
List<E> list;
try {
queryStack++;
//从localCache中根据key值获取数据,这一步就是尝试从一级缓存中获取数据。
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
//如果在一级缓存中没有拿到数据,则就去数据库中查询.
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
//执行数据库查询
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
//将查询的结果放到一级缓存中。
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
很明显,在调用query的时候就已经创建好了CacheKey对象了,并且在后续的查询中会从一级缓存localCache中取数据,如果没有取到数据,则去数据库中查询,从数据库中查询成功后,将数据缓存到一级缓存localCache中去。
以上是对一级缓存机制的详细解析,随后会更新二级缓存的详细解析。
如果哪里写的有争议,请大家多多指教!














 606
606











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









