







1.首先当然还是看官方文档了,这是最好的学习途径。
https://pytorch.org/docs/stable/index.html
2.本人nlp小白一枚,初入pytorch,经常对torch里面的函数搞得模棱两可,导致操作不规范,现在在这里总结下常用的方法,本人水平有限,若有错误希望大家积极指正,互相学习。
3.Tensor
3.1属性相关
torch.is_tensor(obj)用来判断obj是否为一个tensor变量。同样的还有torch.is_storage(obj)用于判断变量是否为一个storage变量。
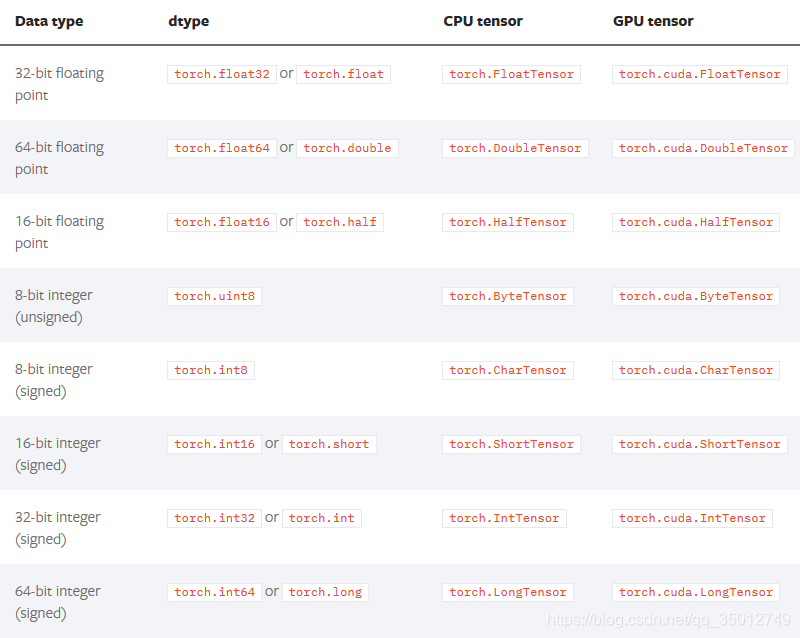
torch.set_default_dtype(d)用于改变tensor中数据的默认类型,如下面的例子:
>>> torch.tensor([1.2, 3]).dtype # initial default for floating point is torch.float32
torch.float32
>>> torch.set_default_dtype(torch.float64)
>>> torch.tensor([1.2, 3]).dtype # a new floating point tensor
torch.float64所有支持的数据类型如下表所示:
3.2Tensor生成
接下来几个是我经常用到的
赋值:
torch.tensor(data, dtype=None, device=None, requires_grad=False)全部生成为0 的tensor
torch.zeros(*sizes, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)这里的size要说一下,可以是任意维度。
>>> torch.zeros(2, 3)
tensor([[ 0., 0., 0.],
[ 0., 0., 0.]])
>>> torch.zeros(5)
tensor([ 0., 0., 0., 0., 0.])当然还有生成全部生成为1 的,具体就不多说了,还有很多,可以去文档看。
torch.ones(*sizes, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)接下来是tensor和numpy的转换
torch.from_numpy(ndarray)>>> a = numpy.array([1, 2, 3])
>>> t = torch.from_numpy(a)
>>> t
tensor([ 1, 2, 3])
>>> t[0] = -1
>>> a
array([-1, 2, 3])3.3Tensor的几个随机生成函数
1.均匀分布
torch.rand(*sizes, out=None) → Tensor
返回一个张量,包含了从区间[0, 1)的均匀分布中抽取的一组随机数。张量的形状由参数sizes定义。
torch.rand(2, 3)
0.0836 0.6151 0.6958
0.6998 0.2560 0.0139
[torch.FloatTensor of size 2x3]2.标准正态分布
torch.randn(*sizes, out=None) → Tensor
返回一个张量,包含了从标准正态分布(均值为0,方差为1,即高斯白噪声)中抽取的一组随机数。张量的形状由参数sizes定义。
torch.randn(2, 3)
0.5419 0.1594 -0.0413
-2.7937 0.9534 0.4561
[torch.FloatTensor of size 2x3]3.离散正态分布
torch.normal(means, std, out=None) → → Tensor
返回一个张量,包含了从指定均值means和标准差std的离散正态分布中抽取的一组随机数。
标准差std是一个张量,包含每个输出元素相关的正态分布标准差。
torch.normal(mean=0.5, std=torch.arange(1, 6))
-0.1505
-1.2949
-4.4880
-0.5697
-0.8996
[torch.FloatTensor of size 5]4.线性间距向量
torch.linspace(start, end, steps=100, out=None) → Tensor
返回一个1维张量,包含在区间start和end上均匀间隔的step个点。
输出张量的长度由steps决定。
torch.linspace(3, 10, steps=5)
3.0000
4.7500
6.5000
8.2500
10.0000
[torch.FloatTensor of size 5]4.各种基本操作
首先是一些小函数
-
torch.lerp(star, end, weight) : 返回结果是out= star t+ (end-start) * weight
-
torch.rsqrt(input) : 返回平方根的倒数
-
torch.mean(input) : 返回平均值
-
torch.std(input) : 返回标准偏差
-
torch.prod(input) : 返回所有元素的乘积
-
torch.sum(input) : 返回所有元素的之和
-
torch.var(input) : 返回所有元素的方差
-
torch.tanh(input) :返回元素双正切的结果
-
torch.equal(torch.Tensor(a), torch.Tensor(b)) :两个张量进行比较,如果相等返回true,否则返回false
-
torch.ge(input,other,out=none) 、 torch.ge(torch.Tensor(a),torch.Tensor(b))
-
torch.max(input): 返回输入元素的最大值
-
torch.min(input) : 返回输入元素的最小值
-
element_size() :返回单个元素的字节
比较频繁常用的:
1.expand(*sizes) → Tensor
返回tensor的一个新视图,单个维度扩大为更大的尺寸。tensor也可以扩大为更高维,新增加的维度将附在前面。 扩大tensor不需要分配新内存,只是仅仅新建一个tensor的视图,其中通过将stride设为0,一维将会扩展位更高维。任何一个一维的在不分配新内存情况下可扩展为任意的数值。
Example:
>>> x = torch.tensor([[1], [2], [3]])
>>> x.size()
torch.Size([3, 1])
>>> x.expand(3, 4)
tensor([[ 1, 1, 1, 1],
[ 2, 2, 2, 2],
[ 3, 3, 3, 3]])
>>> x.expand(-1, 4) # -1 means not changing the size of that dimension
tensor([[ 1, 1, 1, 1],
[ 2, 2, 2, 2],
[ 3, 3, 3, 3]])2.index_add_(dim, index, tensor) → Tensor
按参数index中的索引数确定的顺序,将参数tensor中的元素加到原来的tensor中。附属尺寸必须具有与索引长度相同的大小(必须是向量),所有其他维度必须与原tensor匹配,否则会引起错误。
Example:
>>> x = torch.ones(5, 3)
>>> t = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]], dtype=torch.float)
>>> index = torch.tensor([0, 4, 2])
>>> x.index_add_(0, index, t)
tensor([[ 2., 3., 4.],
[ 1., 1., 1.],
[ 8., 9., 10.],
[ 1., 1., 1.],
[ 5., 6., 7.]])3.repeat(*sizes) → Tensor
沿着指定的维度重复tensor。不同与expand(),本函数复制的是tensor中的数据。
Example:
>>> x = torch.tensor([1, 2, 3])
>>> x.repeat(4, 2)
tensor([[ 1, 2, 3, 1, 2, 3],
[ 1, 2, 3, 1, 2, 3],
[ 1, 2, 3, 1, 2, 3],
[ 1, 2, 3, 1, 2, 3]])
>>> x.repeat(4, 2, 1).size()
torch.Size([4, 2, 3])4.torch.reshape(input, shape) → Tensor
返回具有与输入相同的数据和元素数,但具有指定形状的新属性。如果可能的话,返回的回转接将是输入的视图。否则,它将是一个副本。具有兼容性的输入和输入可以在不进行复制的情况下进行调整,但是您不应该依赖于复制和查看行为。
Example:
>>> a = torch.arange(4.)
>>> torch.reshape(a, (2, 2))
tensor([[ 0., 1.],
[ 2., 3.]])
>>> b = torch.tensor([[0, 1], [2, 3]])
>>> torch.reshape(b, (-1,))
tensor([ 0, 1, 2, 3])5.torch.squeeze(input, dim=None, out=None) → Tensor
返回具有删除尺寸1的输入的所有尺寸的张量。这个非常好用,如果dim没指定的话那么所有尺寸的为1维度都将被压缩。
Example:
>>> x = torch.zeros(2, 1, 2, 1, 2)
>>> x.size()
torch.Size([2, 1, 2, 1, 2])
>>> y = torch.squeeze(x)
>>> y.size()
torch.Size([2, 2, 2])
>>> y = torch.squeeze(x, 0)
>>> y.size()
torch.Size([2, 1, 2, 1, 2])
>>> y = torch.squeeze(x, 1)
>>> y.size()
torch.Size([2, 2, 1, 2])6.torch.unsqueeze(input, dim, out=None) → Tensor
返回具有插入在指定位置的尺寸标注尺寸的新张量。返回的张量与该张量共享相同的基础数据。这是和torch.squeeze()对应的,但是这里的dim必须要赋值。
Example:
>>> x = torch.tensor([1, 2, 3, 4])
>>> torch.unsqueeze(x, 0)
tensor([[ 1, 2, 3, 4]])
>>> torch.unsqueeze(x, 1)
tensor([[ 1],
[ 2],
[ 3],
[ 4]])7.torch.transpose(input, dim0, dim1) → Tensor
给出的尺寸和对应的尺寸是相当的。输出结果与输入共享它的底层存储,因此更改其中一个的内容将改变另一个的内容。顾名思义,这就是矩阵的转置。
Example:
>>> x = torch.randn(2, 3)
>>> x
tensor([[ 1.0028, -0.9893, 0.5809],
[-0.1669, 0.7299, 0.4942]])
>>> torch.transpose(x, 0, 1)
tensor([[ 1.0028, -0.1669],
[-0.9893, 0.7299],
[ 0.5809, 0.4942]])8.torch.masked_select(input, mask, out=None) → Tensor
返回一个新的一维索引,它根据二进制掩码对输入进行索引,这是一个新的索引。这里注意下mask的格式必须是torch.uint8,而且input和mask必须符合“广播原则”。广播原则我会在另一篇文章详细介绍。
Example:
>>> x = torch.randn(3, 4)
>>> x
tensor([[ 0.3552, -2.3825, -0.8297, 0.3477],
[-1.2035, 1.2252, 0.5002, 0.6248],
[ 0.1307, -2.0608, 0.1244, 2.0139]])
>>> mask = x.ge(0.5)
>>> mask
tensor([[ 0, 0, 0, 0],
[ 0, 1, 1, 1],
[ 0, 0, 0, 1]], dtype=torch.uint8)
>>> torch.masked_select(x, mask)
tensor([ 1.2252, 0.5002, 0.6248, 2.0139])9.torch.cat(tensors, dim=0, out=None) → Tensor
在给定的维度中串接给定序列的序列张量。所有张量必须具有相同的形状(连接尺寸除外)或为空。说白了就是将tensor按照指定的维度拼接。torch.cat()相当于torch.split()和torch.chunk()的逆操作。
Example:
>>> x = torch.randn(2, 3)
>>> x
tensor([[ 0.6580, -1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497]])
>>> torch.cat((x, x, x), 0)
tensor([[ 0.6580, -1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497],
[ 0.6580, -1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497],
[ 0.6580, -1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497]])
>>> torch.cat((x, x, x), 1)
tensor([[ 0.6580, -1.0969, -0.4614, 0.6580, -1.0969, -0.4614, 0.6580,
-1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497, -0.1034, -0.5790, 0.1497, -0.1034,
-0.5790, 0.1497]])10.torch.chunk(tensor, chunks, dim=0) → List of Tensors
将张量拆分为特定数量的“块”。如果沿给定尺寸dim的张量尺寸不能被Chunks整除,则最后的Chunk将更小。
Example:
>>> a = torch.tensor([1, 2, 3])
>>> b = torch.chunk(a, 3, 0)
>>> print(b)
(tensor([1]), tensor([2]), tensor([3]))
>>> c = torch.chunk(a, 2, 0)
>>> print(c)
(tensor([1, 2]), tensor([3]))
>>>11.torch.narrow(input, dimension, start, length) → Tensor
返回一个新的张量,它是输入张量的变窄版本。尺寸dim从“开始”输入到“开始长度”。返回的张量和输入张量共享相同的基础存储。
Example:
>>> x = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
>>> torch.narrow(x, 0, 0, 2)
tensor([[ 1, 2, 3],
[ 4, 5, 6]])
>>> torch.narrow(x, 1, 1, 2)
tensor([[ 2, 3],
[ 5, 6],
[ 8, 9]])12.torch.stack(seq, dim=0, out=None) → Tensor
沿着一个新的维度的序列。所有的tensor都需要相同的尺寸。
Example:
>>> a = torch.tensor([[1, 2, 3], [11, 22, 33]])
>>> b = torch.tensor([[4, 5, 6], [44, 55, 66]])
>>> c = torch.stack([a, b], 0)
>>> d = torch.stack([a, b], 1)
>>> e = torch.stack([a, b], 2)
>>> print(c)
tensor([[[ 1, 2, 3],
[11, 22, 33]],
[[ 4, 5, 6],
[44, 55, 66]]])
>>> print(d)
tensor([[[ 1, 2, 3],
[ 4, 5, 6]],
[[11, 22, 33],
[44, 55, 66]]])
>>> print(e)
tensor([[[ 1, 4],
[ 2, 5],
[ 3, 6]],
[[11, 44],
[22, 55],
[33, 66]]])
>>>13.view(*shape) → Tensor
个人理解是把原先tensor中的数据按照行优先的顺序排成一个一维的数据(这里应该是因为要求地址是连续存储的),然后按照参数组合成其他维度的tensor。比如说是不管你原先的数据是[[[1,2,3],[4,5,6]]]还是[1,2,3,4,5,6],因为它们排成一维向量都是6个元素,所以只要view后面的参数一致,得到的结果都是一样的。
Example:
a=torch.Tensor([[[1,2,3],[4,5,6]]])
b=torch.Tensor([1,2,3,4,5,6])
print(a.view(1,6))
print(b.view(1,6))
得到的结果都是tensor([[1., 2., 3., 4., 5., 6.]])
另外,参数不可为空。参数中的-1就代表这个位置由其他位置的数字来推断,只要在不致歧义的情况的下,view参数就可以推断出来,也就是人可以推断出形状的情况下,view函数也可以推断出来。比如a tensor的数据个数是6个,如果view(1,-1),我们就可以根据tensor的元素个数推断出-1代表6。而如果是view(-1,-1,2),人不知道怎么推断,机器也不知道。
Example:
>>> x = torch.randn(4, 4)
>>> x.size()
torch.Size([4, 4])
>>> y = x.view(16)
>>> y.size()
torch.Size([16])
>>> z = x.view(-1, 8) # the size -1 is inferred from other dimensions
>>> z.size()
torch.Size([2, 8])















 4345
4345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









