







Scale-Aware Trident Networks for Object Detection论文研读
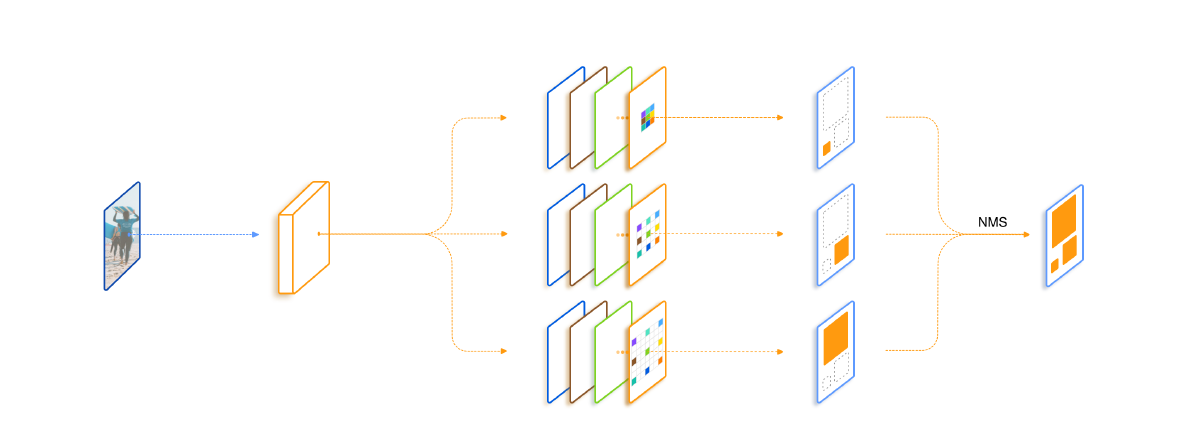
这篇文章主要要解决的问题是目标检测中尺寸变化问题。在标准的COCO benchmark上,使用ResNet101单模型可以得到MAP 48.4的结果。
论文地址:https://arxiv.org/abs/1901.01892
代码:https://git.io/fj5vR.
github:https://github.com/facebookresearch/detectron2/tree/master/projects/TridentNet
Abstract
在这项工作中,作者首先提出了一个控制变量实验来研究感受野对物体检测规模变化的影响。基于实验结果,作者提出了一种新的网络(TridentNet),旨在生成具有统一表示能力的尺度特征图。作者构建了一个并行的多分支架构,每个分支共享相同的权重参数,但感受野不同。然后,作者采用一种尺度感知(Scale-Aware)的训练方案,通过抽取合适尺度的对象实例进行训练,使每个分支专业化。在COCO数据集上,作者使用ResNet-101作为骨干网络的TridentNet实现了48.4 mAP的最先进的单模型结果。
Introduction
目前对于多尺度目标检测方法可总结为几类。
第一大类,也是从非Deep时代,乃至CV初期就被就被广泛使用的方法叫做image pyramid。在image pyramid中,作者直接对图像进行不同尺度的缩放,然后将这些图像直接输入到detector中去进行检测。虽然这样的方法十分简单,但其效果仍然是最佳,也后续启发了SNIP这一系列的工作。单论性能而言,multi-scale training/testing仍然是一个不可缺少的组件。然而其缺点也是很明显的,测试时间大幅度提高,对于实际使用并不友好。
另外一大类方法,也是Deep方法所独有的,也就是feature pyramid。最具代表性的工作便是经典的FPN了。这一类方法的思想是直接在feature层面上来近似image pyramid。非Deep时代在检测中便有经典的channel feature这样的方法,这个想法在CNN中其实更加直接,因为本身CNN的feature便是分层次的。从开始的MS-CNN直接在不同downsample层上检测大小不同的物体,再到后续TDM和FPN加入了新的top down分支补充底层的语义信息不足,都是延续类似的想法。然而实际上,这样的近似虽然有效,但是仍然性能和image pyramid有较大差距。

作者考虑对于一个detector本身而言,backbone有哪些因素会影响性能。总结下来,无外乎三点:network depth(structure),downsample rate和receptive field。对于前两者而言,其影响一般来说是比较明确的,即网络越深(或叫表示能力更强)结果会越好,下采样次数过多对于小物体有负面影响。但是没有工作单独分离出receptive field,保持其他变量不变,来验证它对detector性能的影响。
所以,作者做了一个验证性实验,分别使用ResNet50和ResNet101作为backbone,改变最后一个stage中每个3*3 conv的dilation rate。通过这样的方法,作者便可以固定同样的网络结构,同样的参数量以及同样的downsample rate,只改变网络的receptive field。作者很惊奇地发现,不同尺度物体的检测性能和dilation rate正相关!也就是说,更大的receptive field对于大物体性能会更好,更小的receptive field对于小物体更加友好。于是下面的问题就变成了,作者有没有办法把不同receptive field的优点结合在一起呢?
论文中对感受野进行了研究和实验对比发现两点结论:
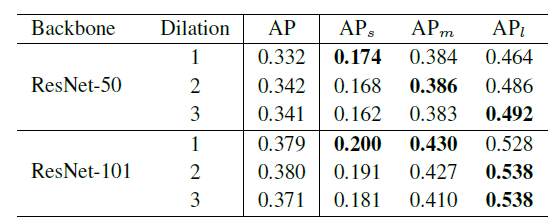
1、对不同尺度物体的表现受网络的感受野的影响。最适合的感受野与物体的大小有很强的相关性。
2、尽管ResNet-101在COCO中有足够大的理论感受野来覆盖大对象(大于96x96分辨率),但随着膨胀率的增大,大对象的性能仍然可以得到提高。有效感受野小于理论感受野。作者假设检测网络的有效感受野需要在大小物体之间保持平衡。通过强调大的物体,增加扩张速度扩大了有效的感受野,从而降低了小物体的表现。
基于以上实验和探究,作者提出了一种新的网络结构,Trident Network。
Trident Network
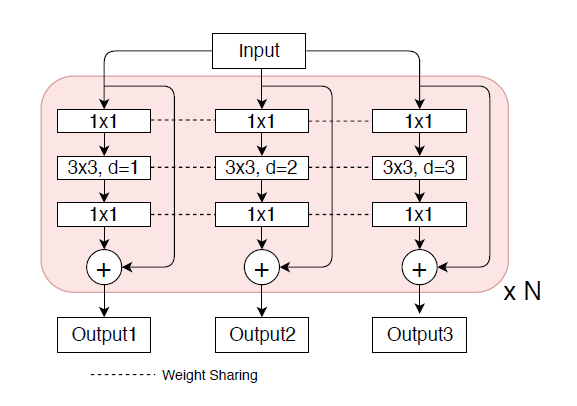
作者最开始的一个想法便是直接加入几支并行,但是dilation rate不同的分支,在文中作者把每一个这样的结构叫做trident block。这样一个简单的想法已经可以带来相当可观的性能提升。作者进一步考虑希望这三支的区别应该仅仅在于receptive field,它们要检测的物体类别,要对特征做的变换应该都是一致的。自然而然地想到对于并行的这几支可以share weight,作者共享了所有分支及其相关的RPN和R-CNN head的权重,只改变了每个分支的扩张率。 一方面是减少了参数量以及潜在的overfitting风险,另一方面充分利用了每个样本,同样一套参数在不同dilation rate下训练了不同scale的样本。最后一个设计则是借鉴SNIP,为了避免receptive field和scale不匹配的情况,作者对于每一个branch只训练一定范围内样本,避免极端scale的物体对于性能的影响。
共享权重会带来三种好处:
1、减少参数,防止过拟合。
2、不同尺度的物体应该通过相同的表征能力进行统一的转换。
3、相同的参数在不同的感受野下被训练成不同的尺度范围。
作者的TridentNet在原始的backbone上做了三点变化:第一点是构造了不同receptive field的parallel multi-branch,第二点是对于trident block中每一个branch的weight是share的。第三点是对于每个branch,训练和测试都只负责一定尺度范围内的样本,也就是所谓的scale-aware。这三点在任何一个深度学习框架中都是非常容易实现的。
在测试阶段,可以只保留一个branch来近似完整TridentNet的结果,后面作者做了充分的对比实验来寻找了这样single branch approximation的最佳setting,一般而言,这样的近似只会降低0.5到1点map,但是和baseline比起来不会引入任何额外的计算和参数。
scale-aware
scale-aware策略本身是控制不同尺度的分支负责训练其对应尺度的bbox,如下式,其中wh为bbox的宽高,l和u代表尺度范围,i代表分支号。尺度感知的训练设计避免了每个分支都有极端尺度的训练对象,但也可能导致有效样本减少导致每个分支的过拟合问题。
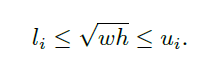
在正常推理过程中,作者生成所有分支的检测结果,然后过滤掉每个分支有效范围之外的方框。但是三个分支一起推理,速度比较慢,效率低。作者提出了一种快速的近似推理方法。三分支网络,作者使用中间的分支进行推理,因为它的有效范围涵盖了大大小小的对象。
为什么只用中间分支就能近似三个分支的推理效果呢?大家看一下作者中间分支的取值范围。
作者将三个分支的有效范围设为[0:90],[30:160]和[90:∞]。作者知道,coco数据集中有三个AP评价指标,分别为APs、APm和APl。分别统计小物体、中物体、大物体的AP情况,范围分别是(小于32x32)、中(32x32到96x96)和(大于96x96)。中间分支的尺寸刚好满足coco数据集中所有标准尺寸。
中间尺度的范围覆盖到了几乎所有尺度的样本。又因为是共享权重,所以推理的时候可以用中间尺度近似代替。其他两个分支类似于辅助训练的意思。
Ablation Studies
作者做了大量实验来确定分支的选择、scale-aware尺度的选择、以及trident block放在resnet的哪个stage、使用多少个trident block、每个分支的表现等。最后与当时sota算法进行了对比。
值得研究的是,作者在探索scale-aware的尺度选择时,使用中等分支进行推理验证,得到如下结论:
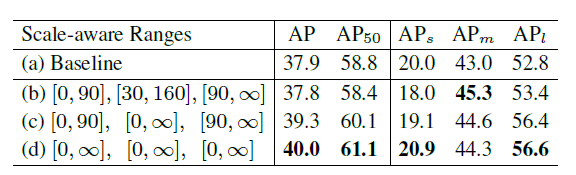
为什么所有scale全部放开限制,得到了相对来说更好的结果?
看表可知,所有scale全部放开限制,得到了相对来说更好的结果。作者认为,假设这可能是由于权重共享策略。
由于主要支路的权值在其他支路上共享,所以在尺度不可知的方案中训练所有支路相当于在网络内进行多尺度扩展。
个人认为是有道理的,虽然没有对图像或者feature做multi-scale,但是作者对感受野做了multi-scale。
最后看一下作者介绍的两个比较重要的ablation。
第一个是作者提出的这三点,分别对性能有怎样的影响。作者分别使用了两个很强的结构ResNet101和ResNet101-Deformable作为backbone。这里特地使用了Deformable的原因是,作者想要证明此方法和Deformable Conv这种 去学习adaptive receptive field的方法仍然相兼容。具体结果见下。
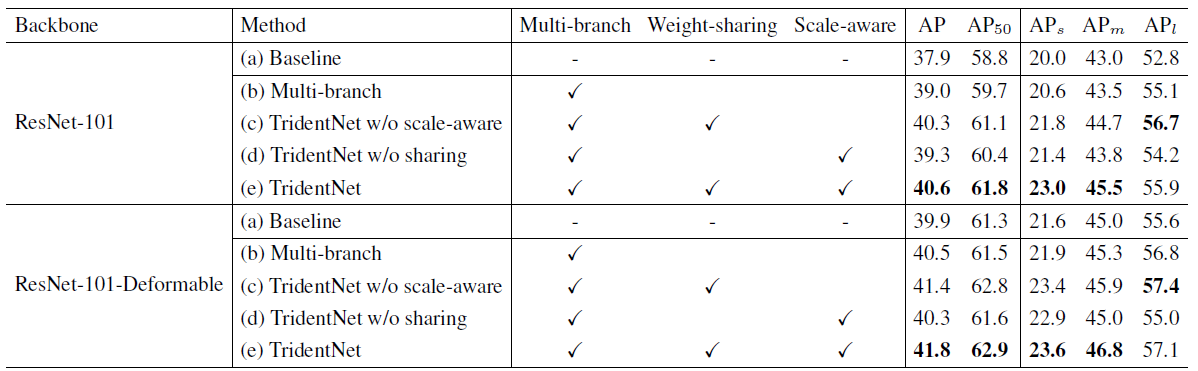
可以看到,在接近map 40的baseline上,作者提出的每一部分都是有效的,在这两个baseline上分别有2.7和1.9 map的提升。
另外一个值得一提的ablation是,对于作者上面提出的single branch approximation,如何选择合适的scale-aware training参数使得近似的效果最好。其实作者发现很有趣的一点是,如果采用single branch近似的话,那么所有样本在所有branch都训练结果最好。这一点其实也符合预期,因为最后只保留一支的话那么参数最好在所有样本上所有scale上充分训练。如果和上文40.6的baseline比较,可以发现作者single branch的结果比full TridentNet只有0.6 map的下降。**这也意味着作者在不增加任何计算量和参数的情况,仍然获得2.1 map的提升。**这对于实际产品中使用的detector而言无疑是个福音。
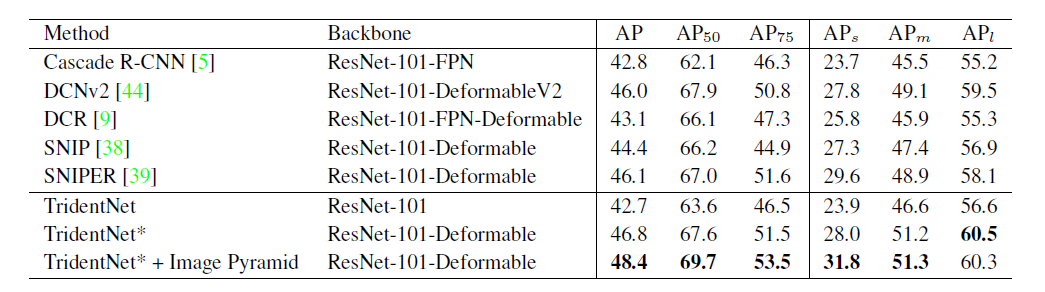
最后作者将方法和各paper中报告的最好结果相比较。但是其实很难保证绝对公平,因为每篇paper使用的trick都不尽相同。所以作者在这里报告了两个结果,一个是ResNet101不加入任何trick直接使用TridentNet的结果,一个是和大家一样加入了全部trick(包括sync BN,multi-scale training/testing,deformable conv,soft-nms)的结果。在这样的两个setting下,分别取得了在COCO test-dev集上42.7和48.4的结果。这应该分别是这样两个setting下目前最佳的结果。single branch approximation也分别取得了42.2和47.6的map,不过这可是比baseline不增加任何计算量和参数量的情况下得到的。
参考资料:
1、https://zhuanlan.zhihu.com/p/54334986
2、https://git.io/fj5vR.


















 609
609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











