







能单独和finally语句一起使用的块是( )
正确答案: A 你的答案: B (错误)
try
catch
throw
throws
解析:处理异常常用的两种方式:
1、try…catch(捕获处理机制);
2、throws(冒泡处理机制).
注意细节:使用try…catch块捕获时可以没有catch块,但当没用catch块的时候必须得有finally块.故选A)
在java中重写方法应遵循规则的包括()
正确答案: B C 你的答案: B D (错误)
访问修饰符的限制一定要大于被重写方法的访问修饰符
可以有不同的访问修饰符
参数列表必须完全与被重写的方法相同
必须具有不同的参数列表
总结来说为:
方法名相同,参数类型相同
子类返回类型等于父类方法返回类型,
子类抛出异常小于等于父类方法抛出异常,
子类访问权限大于等于父类方法访问权限。
详细的说明为:
重写是子类对父类的允许访问的方法的实现过程进行重新编写, 返回值和形参都不能改变。 即外壳不变,核心重写!
重写的好处在于子类可以根据需要,定义特定于自己的行为。 也就是说子类能够根据需要实现父类的方法。
重写方法不能抛出新的检查异常或者比被重写方法申明更加宽泛的异常。例如: 父类的一个方法申明了一个检查异常IOException,但是在重写这个方法的时候不能抛出Exception异常,因为Exception是IOException的父类,只能抛出IOException的子类异常。
方法的重写规则
1)参数列表必须完全与被重写方法的相同;
2)返回类型必须完全与被重写方法的返回类型相同;(备注:这条信息是标准的重写方法的规则,但是在java 1.5 版本之前返回类型必须一样,1.5(包含)j 版本之后ava放宽了限制,返回类型必须小于或者等于父类方法的返回类型 )。才有了
子类返回类型小于等于父类方法返回类型。在java里面这个怎么样都是正确的,请小伙伴谨记。
3)访问权限不能比父类中被重写的方法的访问权限更低。例如:如果父类的一个方法被声明为public,那么在子类中重写该方法就不能声明为protected。
4)父类的成员方法只能被它的子类重写。
5)声明为final的方法不能被重写。
6)声明为static的方法不能被重写,但是能够被再次声明。
7)子类和父类在同一个包中,那么子类可以重写父类所有方法,除了声明为private和final的方法。
8)子类和父类不在同一个包中,那么子类只能够重写父类的声明为public和protected的非final方法。
9)重写的方法能够抛出任何非强制异常,无论被重写的方法是否抛出异常。但是,重写的方法不能抛出新的强制性异常,或者比被重写方法声明的更广泛的强制性异常,反之则可以。
10)构造方法不能被重写。
11)如果不能继承一个方法,则不能重写这个方法。
来自:http://www.runoob.com/java/java-override-overload.html
byte b1=1,b2=2,b3,b6,b8;
final byte b4=4,b5=6,b7;
b3=(b1+b2); /*语句1*/
b6=b4+b5; /*语句2*/
b8=(b1+b4); /*语句3*/
b7=(b2+b5); /*语句4*/
System.out.println(b3+b6);下列代码片段中,存在编辑错误的语句是()
正确答案: B C D 你的答案: D (错误)
语句2
语句1
语句3
语句4
本题答案应为:B、C、D
————知识点————
**Java表达式转型规则由低到高转换:
1、所有的byte,short,char型的值将被提升为int型;
2、如果有一个操作数是long型,计算结果是long型;
3、如果有一个操作数是float型,计算结果是float型;
4、如果有一个操作数是double型,计算结果是double型;
5、被fianl修饰的变量不会自动改变类型,当2个final修饰相操作时,结果会根据左边变量的类型而转化。**
————–解析————–
语句1错误:b3=(b1+b2);自动转为int,所以正确写法为b3=(byte)(b1+b2);或者将b3定义为int;
语句2正确:b6=b4+b5;b4、b5为final类型,不会自动提升,所以和的类型视左边变量类型而定,即b6可以是任意数值类型;
语句3错误:b8=(b1+b4);虽然b4不会自动提升,但b1仍会自动提升,所以结果需要强转,b8=(byte)(b1+b4);
语句4错误:b7=(b2+b5); 同上。同时注意b7是final修饰,即只可赋值一次,便不可再改变。
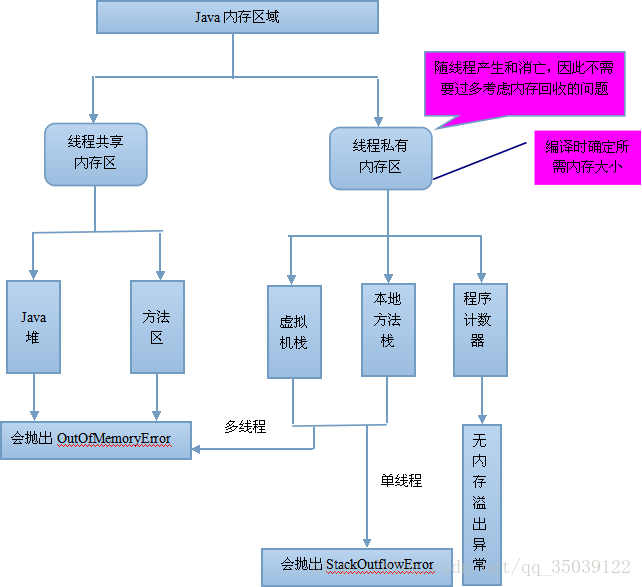
下面有关JVM内存,说法错误的是?
正确答案: C 你的答案: D (错误)
程序计数器是一个比较小的内存区域,用于指示当前线程所执行的字节码执行到了第几行,是线程隔离的
虚拟机栈描述的是Java方法执行的内存模型,用于存储局部变量,操作数栈,动态链接,方法出口等信息,是线程隔离的
方法区用于存储JVM加载的类信息、常量、静态变量、以及编译器编译后的代码等数据,是线程隔离的
原则上讲,所有的对象都在堆区上分配内存,是线程之间共享的
大多数 JVM 将内存区域划分为 Method Area(Non-Heap)(方法区) ,Heap(堆) , Program Counter Register(程序计数器) , VM Stack(虚拟机栈,也有翻译成JAVA 方法栈的),Native Method Stack ( 本地方法栈 ),其中Method Area 和 Heap 是线程共享的 ,VM Stack,Native Method Stack 和Program Counter Register 是非线程共享的。为什么分为 线程共享和非线程共享的呢?请继续往下看。
首先我们熟悉一下一个一般性的 Java 程序的工作过程。一个 Java 源程序文件,会被编译为字节码文件(以 class 为扩展名),每个java程序都需要运行在自己的JVM上,然后告知 JVM 程序的运行入口,再被 JVM 通过字节码解释器加载运行。那么程序开始运行后,都是如何涉及到各内存区域的呢?
概括地说来,JVM初始运行的时候都会分配好 Method Area(方法区) 和Heap(堆) ,而JVM 每遇到一个线程,就为其分配一个 Program Counter Register(程序计数器) , VM Stack(虚拟机栈)和Native Method Stack (本地方法栈), 当线程终止时,三者(虚拟机栈,本地方法栈和程序计数器)所占用的内存空间也会被释放掉。这也是为什么我把内存区域分为线程共享和非线程共享的原因,非线程共享的那三个区域的生命周期与所属线程相同,而线程共享的区域与JAVA程序运行的生命周期相同,所以这也是系统垃圾回收的场所只发生在线程共享的区域(实际上对大部分虚拟机来说知发生在Heap上)的原因。
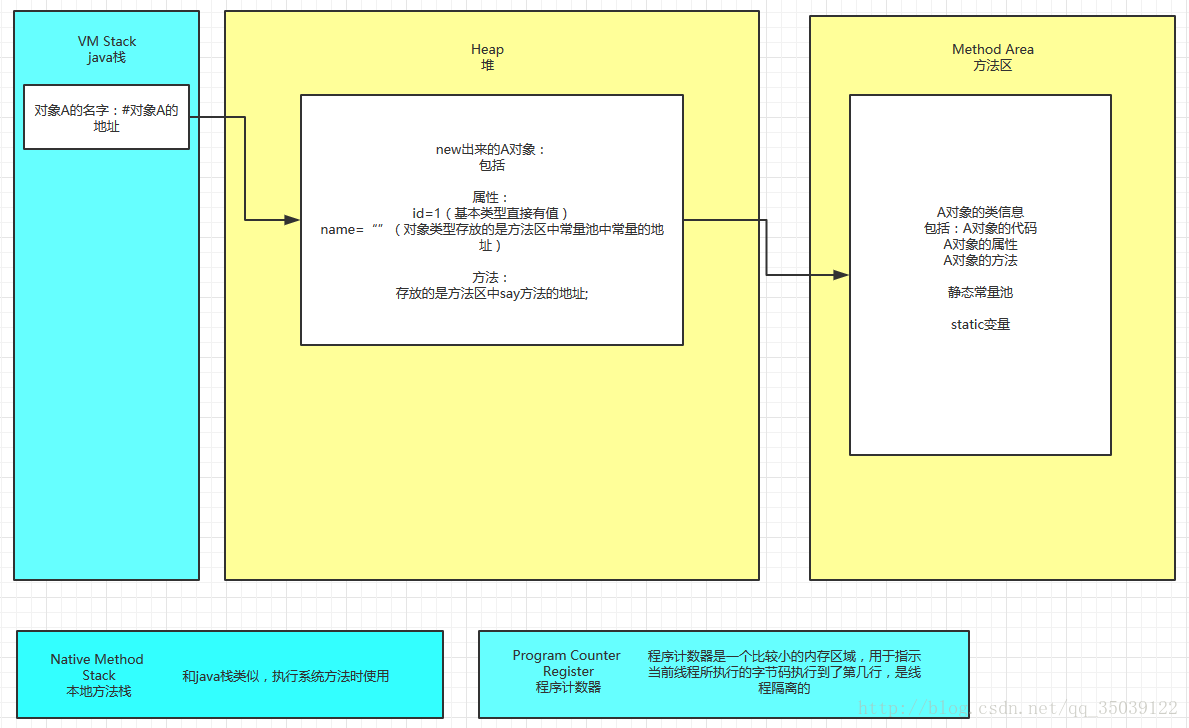
方法区域存放了所加载的类的信息(名称、修饰符等)、类中的静态变量、类中定义为final类型的常量、类中的Field信息、类中的方法信息,当开发人员在程序中通过Class对象中的getName、isInterface等方法来获取信息时,这些数据都来源于方法区域,同时方法区域也是全局共享的,在一定的条件下它也会被GC,当方法区域需要使用的内存超过其允许的大小时,会抛出OutOfMemory的错误信息
可以参考如下的链接:
http://www.cnblogs.com/sunada2005/p/3577799.html
http://blog.csdn.net/ns_code/article/details/17565503
What will happen when you attempt to compile and run the following code?
public class Test{
static{
int x=5;
}
static int x,y;
public static void main(String args[]){
x--;
myMethod( );
System.out.println(x+y+ ++x);
}
public static void myMethod( ){
y=x++ + ++x;
}
}正确答案: D 你的答案: A (错误)
compiletime error
prints:1
prints:2
prints:3
prints:7
prints:8
D
1.静态语句块中x为局部变量,不影响静态变量x的值
2.x和y为静态变量,默认初始值为0,属于当前类,其值得改变会影响整个类运行。
3.java中自增操作非原子性的
main方法中:
执行x–后 x=-1
调用myMethod方法,x执行x++结果为-1(后++),但x=0,++x结果1,x=1 ,则y=0
x+y+ ++x,先执行x+y,结果为1,执行++x结果为2,得到最终结果为3
D.
1.JVM加载class文件时,就会执行静态代码块,静态代码块中初始化了一个变量x并初始化为5,由于该变量是个局部变量,静态代码快执行完后变被释放。
2.申明了两个静态成员变量x,y,并没有赋初值,会有默认出值,int类型为0,
3.执行x–操作,变量单独进行自增或自减操作x–和–x的效果一样,此时x变为了-1
4.调用MyMethod()方法,在该方法中对x和y进行计算,由于x和y都是静态成员变量,所以在整个类的生命周期内的x和y都是同一个
5.y=x++ + ++x可以看成是y=(x++)+(++x),当++或者–和其它变量进行运算时,x++表示先运算,再自增,++x表示先自增再参与运算
所以就时x为-1参与运算,然后自增,x此时为0,++x后x为1,然后参与运算,那么y=-1+1就为0,此时x为1
6.执行并打印x+y + ++x运算方式和第5步相同,最后计算结果就为3.
1
2
3
变量a是一个64位有符号的整数,初始值用16进制表示为:0Xf000000000000000;
变量b是一个64位有符号的整数,初始值用16进制表示为:0x7FFFFFFFFFFFFFFF。
则a-b的结果用10进制表示为多少?()
正确答案: C 你的答案: B (错误)
1
-(2^62+2^61+2^60+1)
2^62+2^61+2^60+1
2^59+(2^55+2^54+…+2^2+2^1+2^0)
0Xf000000000000000补码为1111000000000000000000000000000000000000000000000000000000000000(初始值就是补码)
0x7FFFFFFFFFFFFFFF补码为0111111111111111111111111111111111111111111111111111111111111111
a-b=a+(-b)=
1111000000000000000000000000000000000000000000000000000000000000+
1000000000000000000000000000000000000000000000000000000000000001=
10111000000000000000000000000000000000000000000000000000000000001(高位溢出舍去)
则结果为
0111000000000000000000000000000000000000000000000000000000000001=
2^62+2^61+2^60+1
答案为C
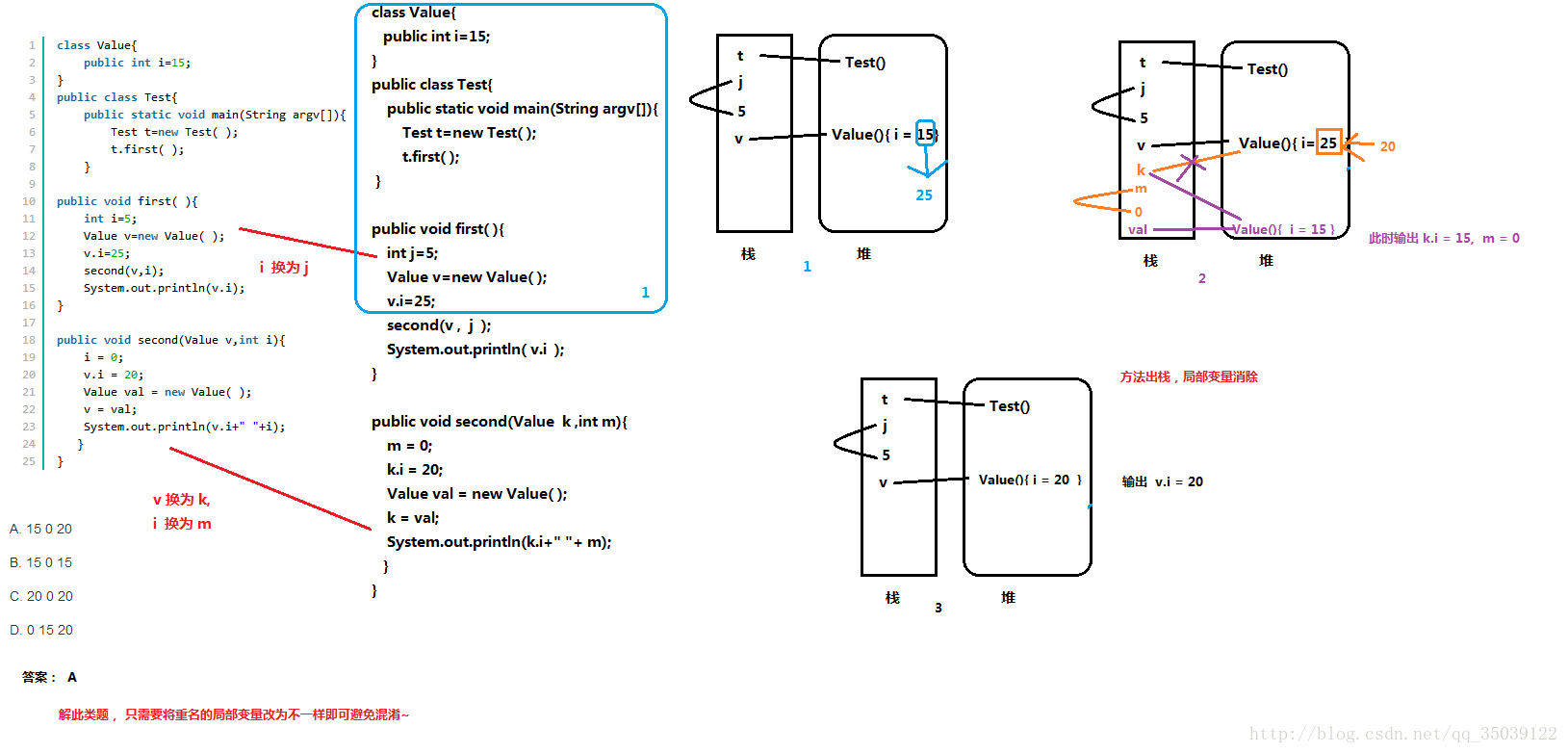
given the following code,what will be the output?
class Value{
public int i=15;
}
public class Test{
public static void main(String argv[]){
Test t=new Test( );
t.first( );
}
public void first( ){
int i=5;
Value v=new Value( );
v.i=25;
second(v,i);
System.out.println(v.i);
}
public void second(Value v,int i){
i = 0;
v.i = 20;
Value val = new Value( );
v = val;
System.out.println(v.i+" "+i);
}
}正确答案: A 你的答案: A (正确)
15 0 20
15 0 15
20 0 20
0 15 20
可能有人会选择B,包括我刚开始也是。总以为v不是已经指向了val了吗??为什么还是20呢?不应该是15吗?
其实,原因很简单。现在我们把second()换一下
publicvoidsecond(Value tmp,inti){
i = 0;
tmp.i = 20;
Value val = newValue( );
tmp = val;
System.out.println(tmp.i+” “+i);
}
这个tmp其实相当于是一个指向原来first中的V这个对象的指针,也就是对v对象的引用而已。但是引用是会改变所指的地址的值的。
所以在second中当tmp.i= 20的时候,就把原来first中的v的i值改为20了。接下来,又把tmp指向了新建的一个对象,所以在second中的tmp
现在指的是新的对象val,i值为15.
当执行完毕second后,在first中在此输出v.i的时候,应为前面second中已经把该位置的i的值改为了20,所以输出的是20.
至于疑惑v指向了val,其实只是名字的问题,在second中的v实践也是另外的一个变量,名字相同了而已,这个估计也是纠结的重点。
简单的总结,不对希望可以提出来,谢谢!
What results from the following code fragment?
int i = 5;
int j = 10;
System.out.println(i + ~j);正确答案: C 你的答案: B (错误)
Compilation error because”~”doesn’t operate on integers
-5
-6
15
计算机中以补码存储。
正数的原码/反码/补码相同,所以
10存储为00000000 00000000 00000000 00001010
~10的原码为11111111 11111111 11111111 11110101(10取反)
~10的反码为10000000 00000000 00000000 00001010(最高位符号位,不变,其余位取反)
~10的补码为10000000 00000000 00000000 00001011(负数的补码=反码+1)
所以~10 = -11
void waitForSignal()
{
Object obj = new Object();
synchronized(Thread.currentThread())
{
obj.wait();
obj.notify();
}
}Which statement is true?
正确答案: A 你的答案: D (错误)
This code may throw an InterruptedException
This code may throw an IllegalStateException
This code may throw a TimeOutException after ten minutes
This code will not compile unless”obj.wait()”is replaced with”(Thread)obj).wait()”
Reversing the order of obj.wait()and obj.notify()may cause this method to complete normally
引自:https://translate.google.com/translate?hl=zh-CN&sl=zh-TW&u=http://yaya741228.pixnet.net/blog/post/78949696-%25E4%25B8%2580%25E5%25A4%25A9%25E4%25BA%2594%25E9%25A1%258Cscjp(11~15)&prev=search
解析:
这题有两个错误的地方,第一个错误是 wait() 方法要以 try/catch 包覆,或是掷出 InterruptedException 才行
因此答案就是因为缺少例外捕捉的 InterruptedException
第二个错误的地方是, synchronized 的目标与 wait() 方法的物件不相同,会有 IllegalMonitorStateException ,不过 InterruptedException 会先出现,所以这不是答案
最后正确的程式码应该是这样:
void waitForSignal() {
Object obj = new Object();
synchronized (obj) {
try {
obj.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
obj.notify();
}
}下面哪种情况会导致持久区jvm堆内存溢出?
正确答案: C 你的答案: C
循环上万次的字符串处理
在一段代码内申请上百M甚至上G的内存
使用CGLib技术直接操作字节码运行,生成大量的动态类
不断创建对象
堆内存设置:
原理
JVM堆内存分为2块:Permanent Space 和 Heap Space。
Permanent 即 持久代(Permanent Generation),主要存放的是Java类定义信息,与垃圾收集器要收集的Java对象关系不大。
Heap = { Old + NEW = {Eden, from, to} },Old 即 年老代(Old Generation),New 即 年轻代(Young Generation)。年老代和年轻代的划分对垃圾收集影响比较大。
年轻代
所有新生成的对象首先都是放在年轻代。年轻代的目标就是尽可能快速的收集掉那些生命周期短的对象。年轻代一般分3个区,1个Eden区,2个Survivor区(from 和 to)。
大部分对象在Eden区中生成。当Eden区满时,还存活的对象将被复制到Survivor区(两个中的一个),当一个Survivor区满时,此区的存活对象将被复制到另外一个Survivor区,当另一个Survivor区也满了的时候,从前一个Survivor区复制过来的并且此时还存活的对象,将可能被复制到年老代。
2个Survivor区是对称的,没有先后关系,所以同一个Survivor区中可能同时存在从Eden区复制过来对象,和从另一个Survivor区复制过来的对象;而复制到年老区的只有从另一个Survivor区过来的对象。而且,因为需要交换的原因,Survivor区至少有一个是空的。特殊的情况下,根据程序需要,Survivor区是可以配置为多个的(多于2个),这样可以增加对象在年轻代中的存在时间,减少被放到年老代的可能。
针对年轻代的垃圾回收即 Young GC。
年老代
在年轻代中经历了N次(可配置)垃圾回收后仍然存活的对象,就会被复制到年老代中。因此,可以认为年老代中存放的都是一些生命周期较长的对象。
针对年老代的垃圾回收即 Full GC。
持久代
用于存放静态类型数据,如 Java Class, Method 等。持久代对垃圾回收没有显著影响。但是有些应用可能动态生成或调用一些Class,例如 Hibernate CGLib 等,在这种时候往往需要设置一个比较大的持久代空间来存放这些运行过程中动态增加的类型。
所以,当一组对象生成时,内存申请过程如下:
JVM会试图为相关Java对象在年轻代的Eden区中初始化一块内存区域。
当Eden区空间足够时,内存申请结束。否则执行下一步。
JVM试图释放在Eden区中所有不活跃的对象(Young GC)。释放后若Eden空间仍然不足以放入新对象,JVM则试图将部分Eden区中活跃对象放入Survivor区。
Survivor区被用来作为Eden区及年老代的中间交换区域。当年老代空间足够时,Survivor区中存活了一定次数的对象会被移到年老代。
当年老代空间不够时,JVM会在年老代进行完全的垃圾回收(Full GC)。
Full GC后,若Survivor区及年老代仍然无法存放从Eden区复制过来的对象,则会导致JVM无法在Eden区为新生成的对象申请内存,即出现“Out of Memory”。
OOM(“Out of Memory”)异常一般主要有如下2种原因:
1. 年老代溢出,表现为:java.lang.OutOfMemoryError:Javaheapspace
这是最常见的情况,产生的原因可能是:设置的内存参数Xmx过小或程序的内存泄露及使用不当问题。
例如循环上万次的字符串处理、创建上千万个对象、在一段代码内申请上百M甚至上G的内存。还有的时候虽然不会报内存溢出,却会使系统不间断的垃圾回收,也无法处理其它请求。这种情况下除了检查程序、打印堆内存等方法排查,还可以借助一些内存分析工具,比如MAT就很不错。
- 持久代溢出,表现为:java.lang.OutOfMemoryError:PermGenspace
通常由于持久代设置过小,动态加载了大量Java类而导致溢出 ,解决办法唯有将参数 -XX:MaxPermSize 调大(一般256m能满足绝大多数应用程序需求)。将部分Java类放到容器共享区(例如Tomcat share lib)去加载的办法也是一个思路,但前提是容器里部署了多个应用,且这些应用有大量的共享类库
语句:char foo=’中’,是否正确?(假设源文件以GB2312编码存储,并且以javac – encoding GB2312命令编译)
正确答案: A 你的答案: B
正确
错误
Java语言中,中文字符所占的字节数取决于字符的编码方式,一般情况下,采用ISO8859-1编码方式时,一个中文字符与一个英文字符一样只占1个字节;采用GB2312或GBK编码方式时,一个中文字符占2个字节;而采用UTF-8编码方式时,一个中文字符会占3个字节。















 1625
1625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









