







 本文介绍了Intel OpenVINO工具包中的预训练模型,包括目标检测、识别、分割等各类模型及其应用场景。并提供了模型下载及使用的具体步骤。
本文介绍了Intel OpenVINO工具包中的预训练模型,包括目标检测、识别、分割等各类模型及其应用场景。并提供了模型下载及使用的具体步骤。
OpenVINO 系列软件包预训练模型介绍
本文翻译自 Intel OpenVINO 的 "Overview of OpenVINO Toolkit Pre-Trained Models"
原文链接: https://docs.openvinotoolkit.org/latest/_models_intel_index.html
翻译:coneypo,working in Intel for IoT,有问题或者建议欢迎留言交流
Q&A
问:用 Pre-trained model 可以干什么?
答:我们可以用 Pre-trained 的模型直接输入数据进行 model inference / 推理,而不需要收集数据集自己 Train 一个 model,这些训练好的模型拿来即用,适合新手学习;
问:如何使用 OpenVINO 预训练模型进行推算?
答:
1. 先下载安装 OpenVINO 环境: https://docs.openvinotoolkit.org/cn/index.html;
2. OpenVINO 提供的 model zoo 的示例代码在这个 repo :
$ git clone https://github.com/opencv/open_model_zoo
$ cd /open_model_zoo/demos/python_demos/
3. 比如有一个 face_recognition_demo/ 文件夹,里面有个 README.md 告诉怎么配置参数:
python ./face_recognition_demo.py ^
-m_fd /face-detection-retail-0004.xml ^
-m_lm /landmarks-regression-retail-0009.xml ^
-m_reid /face-reidentification-retail-0095.xml ^
--verbose ^
-fg "C:/face_gallery"4. 下载模型
$ cd //deployment_tools/open_model_zoo/tools/downloader/
$ sudo ./downloader.py --name face-detection-retail-0004
$ sudo ./downloader.py --name landmarks-regression-retail-0009.xml
$ sudo ./downloader.py --name face-reidentification-retail-0095.xml
5. 运行 face_recognition_demo.py
这篇文章中会介绍如下模型:
- Object Detection Models / 目标检测模型
- Object Recognition Models / 目标识别模型
- Reidentification Models / 回归模型
- Semantic Segmentation Models / 语义分割模型
- Instance Segmentation Models / 实例分割模型
- Human Pose Estimation Models / 人类姿势识别模型
- Image Processing/ 图像处理
- Text Detection / 文本检测
- Text Recognition / 文本识别
- Text Spotting / 文本识别
- Action Recognition Models / 动作识别模型
- Image Retrieval / 图像检索
- Compressed models / 压缩模型
OpenVINO 软件包提供一系列预训练模型,你可以用来进行学习,或者进行参考设计;
OpenVINO 的版本会在 Github_open_model zoo 上面进行维护;
这些模型也可以通过模型下载器 (/deployment_tools/open_model_zoo/tools/downloader) 下载,或者在 01.org 进行手动下载;
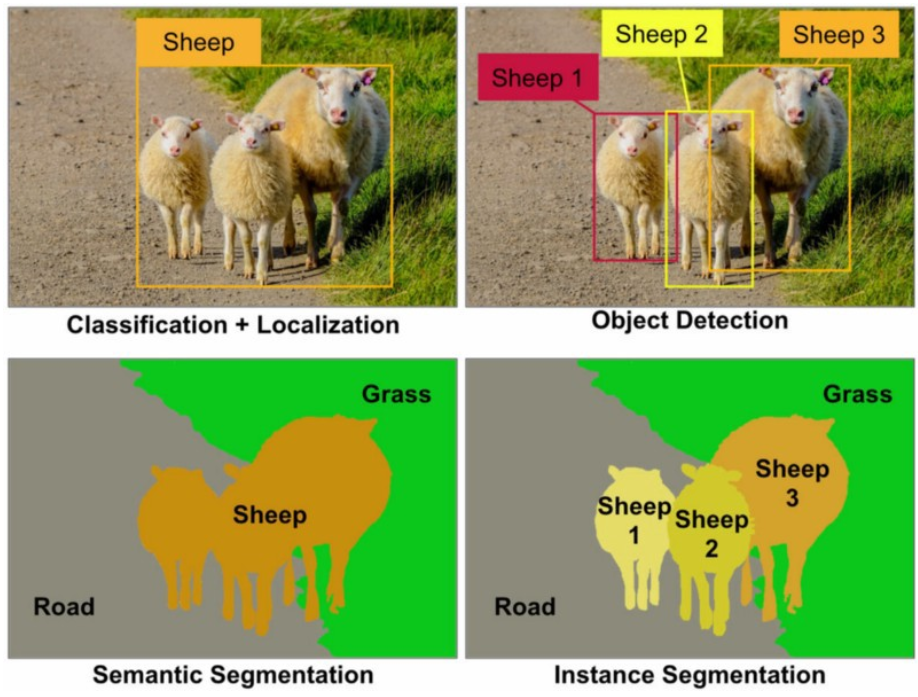
*(补充)Classification / 分类,Detection / 检测,Semantic Segmentation / 语义分割,Instance Segmentation / 实例分割 区别
Object Detection Models / 目标检测模型
OpenVINO 提供一系列热门目标,如人脸/人/汽车等等的检测模型;大多数网络都是基于 SSD (Single Shot MultiBox Detector),而且准确度和性能都不错;
针对于检测相同类型目标的网络(比如 face-detection-adas-0001 和 face-detection-retail-0004),能够以较小的性能代价,让我们达到更高的精度和更广的适用范围;
因此你可以期待一个更大的神经网络,来更好的检测相同类型的对象;
| 模型名称 | 复杂度 (GFLOPS) | 大小(MP) | 人脸 | 人 | 汽车 | 自行车 | 车牌 | 产品 |
|---|---|---|---|---|---|---|---|---|
| target="_blank">faster-rcnn-resnet101-coco-sparse-60-0001 | 364.21 | 52.79 | X | X | X | |||
| target="_blank">face-detection-adas-0001 | 2.835 | 1.053 | X | |||||
| target="_blank">face-detection-adas-binary-0001 | 0.819 | 1.053 | X | |||||
| target="_blank">face-detection-retail-0004 | 1.067 | 0.588 | X | |||||
| target="_blank">face-detection-retail-0005 | 0.982 | 1.021 | X | |||||
| target="_blank">face-detection-0100 | 0.785 | 1.828 | X | |||||
| target="_blank">face-detection-0102 | 1.767 | 1.842 | X | |||||
| target="_blank">face-detection-0104 | 2.405 | 1.851 | X | |||||
| target="_blank">face-detection-0105 | 2.853 | 2.392 | X | |||||
| target="_blank">face-detection-0106 | 339.597 | 69.920 | X | |||||
| person-detection-retail-0002 | 12.427 | 3.244 | X | |||||
| target="_blank">person-detection-retail-0013 | 2.300 | 0.723 | X | |||||
| target="_blank">person-detection-action-recognition-0005 | 7.140 | 1.951 | X | |||||
| target="_blank">person-detection-action-recognition-0006 | 8.225 | 2.001 | X | |||||
| target="_blank">person-detection-action-recognition-teacher-0002 | 7.140 | 1.951 | X | |||||
| target="_blank">person-detection-raisinghand-recognition-0001 | 7.138 | 1.951 | X | |||||
| target="_blank">pedestrian-detection-adas-0002 | 2.836 | 1.165 | X | |||||
| target="_blank">pedestrian-detection-adas-binary-0001 | 0.945 | 1.165 | X | |||||
| target="_blank">pedestrian-and-vehicle-detector-adas-0001 | 3.974 | 1.650 | X | X | ||||
| target="_blank">vehicle-detection-adas-0002 | 2.798 | 1.079 | X | |||||
| target="_blank">vehicle-detection-adas-binary-0001 | 0.942 | 1.079 | X | |||||
| target="_blank">person-vehicle-bike-detection-crossroad-0078 | 3.964 | 1.178 | X | X | X | |||
| target="_blank">person-vehicle-bike-detection-crossroad-1016 | 3.560 | 2.887 | X | X | X | |||
| target="_blank">vehicle-license-plate-detection-barrier-0106 | 0.349 | 0.634 | X | X | ||||
| target="_blank">product-detection-0001 | 3.598 | 3.212 | X | |||||
| target="_blank">person-detection-asl-0001 | 0.986 | 1.338 | X | |||||
| target="_blank">yolo-v2-ava-0001 | 29.38 | 48.29 | X | X | X | |||
| target="_blank">yolo-v2-ava-sparse-35-0001 | 29.38 | 48.29 | X | X | X | |||
| target="_blank">yolo-v2-ava-sparse-70-0001 | 29.38 | 48.29 | X | X | X | |||
| target="_blank">yolo-v2-tiny-ava-0001 | 6.975 | 15.12 | X | X | X | |||
| target="_blank">yolo-v2-tiny-ava-sparse-30-0001 | 6.975 | 15.12 | X | X | X | |||
| target="_blank">yolo-v2-tiny-ava-sparse-60-0001 | 6.975 | 15.12 | X | X | X |
Object Recognition Models / 目标识别模型
目标识别模型用来进行 Classification / 分类,Regression / 回归,Charcter recognition / 特征识别;
针对某种特征进行检测之后,再使用这些神经网络进行检测/识别(比如在人脸识别之后,再进行年龄/性别的识别);
| 模型名称 | 复杂度 (GFLOPS) | 大小 (MP) |
|---|---|---|
| target="_blank">age-gender-recognition-retail-0013 | 0.094 | 2.138 |
| target="_blank">head-pose-estimation-adas-0001 | 0.105 | 1.911 |
| target="_blank">license-plate-recognition-barrier-0001 | 0.328 | 1.218 |
| target="_blank">vehicle-attributes-recognition-barrier-0039 | 0.126 | 0.626 |
| target="_blank">emotions-recognition-retail-0003 | 0.126 | 2.483 |
| target="_blank">landmarks-regression-retail-0009 | 0.021 | 0.191 |
| target="_blank">facial-landmarks-35-adas-0002 | 0.042 | 4.595 |
| target="_blank">person-attributes-recognition-crossroad-0230 | 0.174 | 0.735 |
| target="_blank">gaze-estimation-adas-0002 | 0.139 | 1.882 |
Reidentification Models / 再识别模型
在视频中,进行精准的目标追踪是计算机视觉的典型应用场景;
它通常会因为一系列的事情而变得相对比较复杂,这些事情可以描述为 "Relatively long absence of an object" / 一个对象相对较长的缺失;
比如,可能由于 occlusion / 遮挡 或者 out-of-frame movement / 框外移动 导致的;
针对这种情况,最好将目标视为 "seen before" / 先前见过的,而不管其在图像中的当前位置,或者距离上次识别出位置经过多长时间;
下面的网络用在以上这种情况,这些网络获取一个人的图像,然后将这个人的特征在高维空间中进行评估;这些特征向量会进行进一步评估:通过比较欧式距离来确定是否是同一个人;
这里提供了几种模型,在性能和精确度之间进行权衡(模型更大,性能更好):
| 模型名称 | 复杂度 (GFLOPS) | 大小 (MP) | RANK-1 ON MARKET-1501 数据集 |
|---|---|---|---|
| target="_blank">person-reidentification-retail-0031 | 0.028 | 0.280 | 92.11% |
| target="_blank">person-reidentification-retail-0248 | 0.174 | 0.183 | 84.3% |
| target="_blank">person-reidentification-retail-0249 | 0.564 | 0.597 | 92.9% |
| target="_blank">person-reidentification-retail-0300 | 3.521 | 5.289 | 96.3% |
| 模型名称 | 复杂度 (GFLOPS) | 大小 (MP) | RANK-1 ON MARKET-1501 数据集 |
|---|---|---|---|
| target="_blank">face-reidentification-retail-0095 | 0.588 | 1.107 | 99.33% |
Semantic Segmentation Models / 语义分割模型
语义分割可以归为目标检测的拓展问题;
返回的不是特征框,语义分割模型返回输入图像(图像中每个像素的颜色代表着特定的类别)的 Painted version / 涂色块;
这些网络比目标检测网络要复杂的多,但是提供了一个像素级别的分类,属于同一类的像素会被归为一类(涂上相同颜色),而且可以检测到复杂图形中的空间(比如道路中的可用区域);
| 模型名称 | 复杂度(GFLOPS) | 大小 (MP) |
|---|---|---|
| target="_blank">road-segmentation-adas-0001 | 4.770 | 0.184 |
| target="_blank">semantic-segmentation-adas-0001 | 58.572 | 6.686 |
| target="_blank">unet-camvid-onnx-0001 | 260.1 | 31.03 |
| target="_blank">icnet-camvid-ava-0001 | 151.82 | 25.45 |
| target="_blank">icnet-camvid-ava-sparse-30-0001 | 151.82 | 25.45 |
| target="_blank">icnet-camvid-ava-sparse-60-0001 | 151.82 | 25.45 |
Instance Segmentation Models / 实例分割模型
实例分割模型是目标检测和语义分割的拓展;
实例分割模型不是对每个目标实例进行特征框预测分析,而是为每个实例生成像素级别的遮罩;
| 模型名称 | 复杂度 (GFLOPS) | 大小 (MP) |
|---|---|---|
| target="_blank">instance-segmentation-security-1025 | 30.146 | 26.69 |
| target="_blank">instance-segmentation-security-0050 | 46.602 | 30.448 |
| target="_blank">instance-segmentation-security-0083 | 365.626 | 143.444 |
| target="_blank">instance-segmentation-security-0010 | 899.568 | 174.568 |
Human Pose Estimation Models / 人类姿势估计模型
人体姿势估计任务用来预测姿势:对于输入的图像或者视频,推断出带有特征点和特征点之间连接的身体骨骼;特征点是身体器官:比如耳朵,眼睛,鼻子,胳膊,膝盖等等;
有两种主要的分类:top-down / 从上往下, bottom-up / 从下往上;
第一种方法在给定的帧中,检测出人,然后裁剪和调整,运行姿势估计网络为每个检测出来的人,这种方法很精确;
第二种找到给定的帧中,所有的特征点,然后根据人的实例进行分类,因此比第一种更快,因为网络只运行了一次;
| 模型名称 | 复杂度 (GFLOPS) | 大小 (MP) |
|---|---|---|
| target="_blank">human-pose-estimation-0001 | 15.435 | 4.099 |
Image Processing / 图像处理
深度学习模型在图像处理中应用来提高输出质量:
| 模型名称 | 复杂度 (GFLOPS) | 大小 (MP) |
|---|---|---|
| target="_blank">single-image-super-resolution-1032 | 11.654 | 0.030 |
| target="_blank">single-image-super-resolution-1033 | 16.062 | 0.030 |
| target="_blank">text-image-super-resolution-0001 | 1.379 | 0.003 |
Text Detection / 文本检测
深度学习模型在文本检测中进行应用:
| 模型名称 | 复杂度 (GFLOPS) | 大小 (MP) |
|---|---|---|
| target="_blank">text-detection-0003 | 51.256 | 6.747 |
| target="_blank">text-detection-0004 | 23.305 | 4.328 |
Text Recognition / 文本识别
深度学习模型在文本识别中应用;
| 模型名称 | 复杂度 (GFLOPS) | 大小 (MP) |
|---|---|---|
| target="_blank">text-recognition-0012 | 1.485 | 5.568 |
| target="_blank">handwritten-score-recognition-0003 | 0.792 | 5.555 |
| target="_blank">handwritten-japanese-recognition-0001 | 117.136 | 15.31 |
Text Spotting / 文本定位识别
深度学习模型用于文本检测识别;
| 模型名称 | 复杂度 (GFLOPS) | 大小 (MP) |
|---|---|---|
| target="_blank">text-spotting-0002-detector | 185.169 | 26.497 |
| target="_blank">text-spotting-0002-recognizer-encoder | 2.082 | 1.328 |
| target="_blank">text-spotting-0002-recognizer-decoder | 0.002 | 0.273 |
Action Recognition Models / 动作识别模型
动作识别模型对一个视频短片(通过堆叠来自输入视频的采样帧得到的张量)预测动作;
一些模型从不同的视频片段中提取(比如 driver-action-recognition-adas-0002 可能会使用预计算的高维度)特征(嵌入) 然后整合到一个临时模型中,用分类分数来预测一个向量;
计算嵌入的模型称为 encoder / 编码器,用来预测真实标签的模型称为 decoder / 解码器;
| 模型名称 | 复杂度 (GFLOPS) | 大小 (MP) |
|---|---|---|
| target="_blank">driver-action-recognition-adas-0002-encoder | 0.676 | 2.863 |
| target="_blank">driver-action-recognition-adas-0002-decoder | 0.147 | 4.205 |
| target="_blank">action-recognition-0001-encoder | 7.340 | 21.276 |
| target="_blank">action-recognition-0001-decoder | 0.147 | 4.405 |
| target="_blank">asl-recognition-0004 | 6.660 | 4.133 |
Image Retrieval / 图像检索
深度学习模型用来进行图像检索(根据相似度对图像进行排序);
| 模型名称 | 复杂度 (GFLOPS) | 大小 (MP) |
|---|---|---|
| target="_blank">image-retrieval-0001 | 0.613 | 2.535 |
Compressed Models / 压缩模型
深度学习压缩模型;
| 模型名称 | 复杂度 (GFLOPS) | 大小 (MP) |
|---|---|---|
| target="_blank">resnet50-binary-0001 | 1.002 | 7.446 |
| target="_blank">resnet18-xnor-binary-onnx-0001 | - | - |
欢迎使用 Intel OpenVINO Toolkit 进行 AI 开发,OpenVINO(SW)+ MyriadX VPU(HW) 主要侧重于 Inference 推算时的加速,借助 Intel VPU 可以对边缘端设备推演时进行加速;
我会在之后的 blog 里面更新详细的 sample code 的用法;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









