







一、项目分析
1、查询爬取网址 robots 权限
1、王者荣耀官网:https://pvp.qq.com/
2、访问王者荣耀官网 rbots 权限: https://pvp.qq.com/robots.txt,确定此网站没有设置 robots 权限,即证明此网站数据可以爬取。
2、查询主页和详情页面的关系
高清壁纸页面 url :https://pvp.qq.com/web201605/wallpaper.shtml
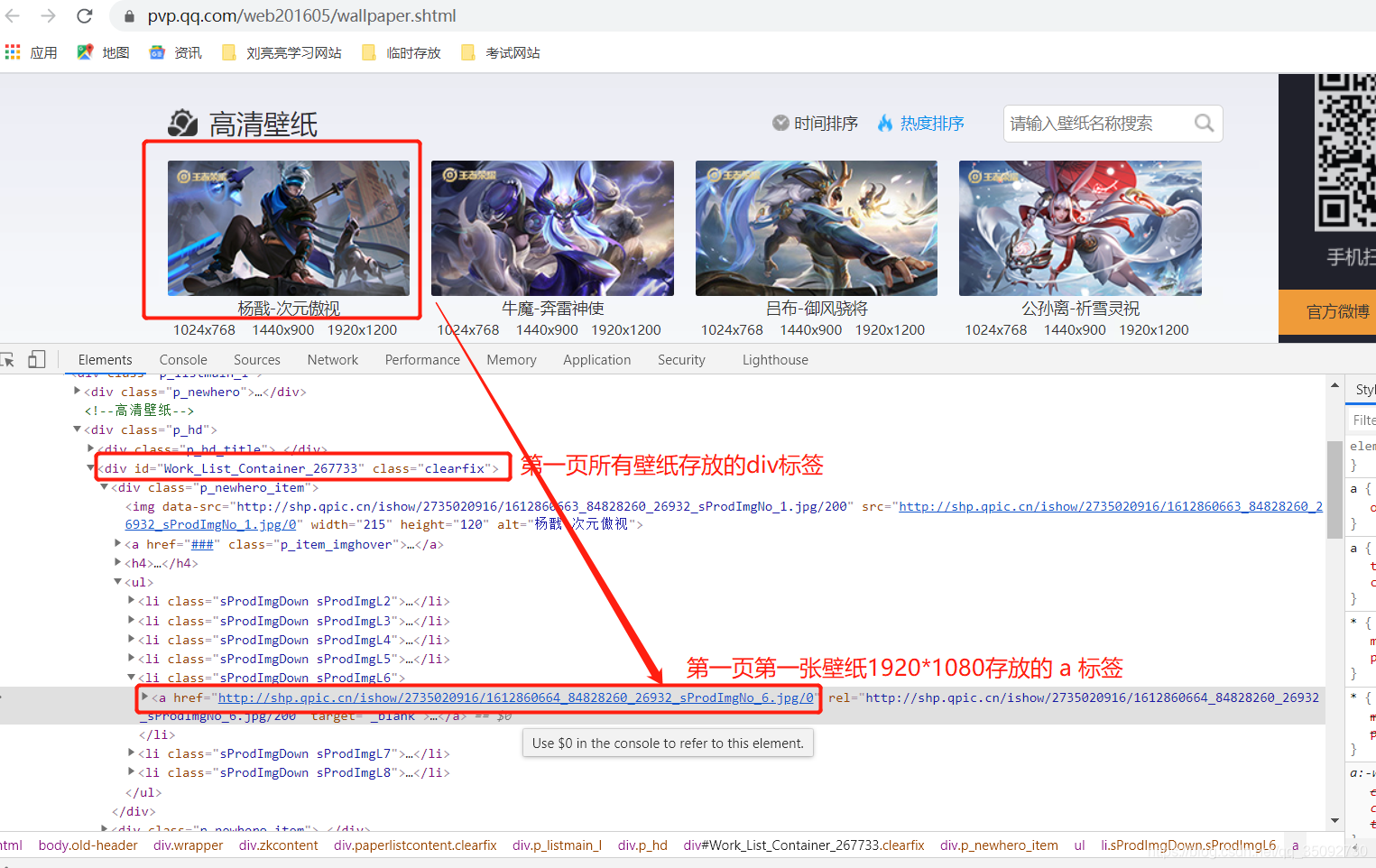
3、查看当前网页源代码
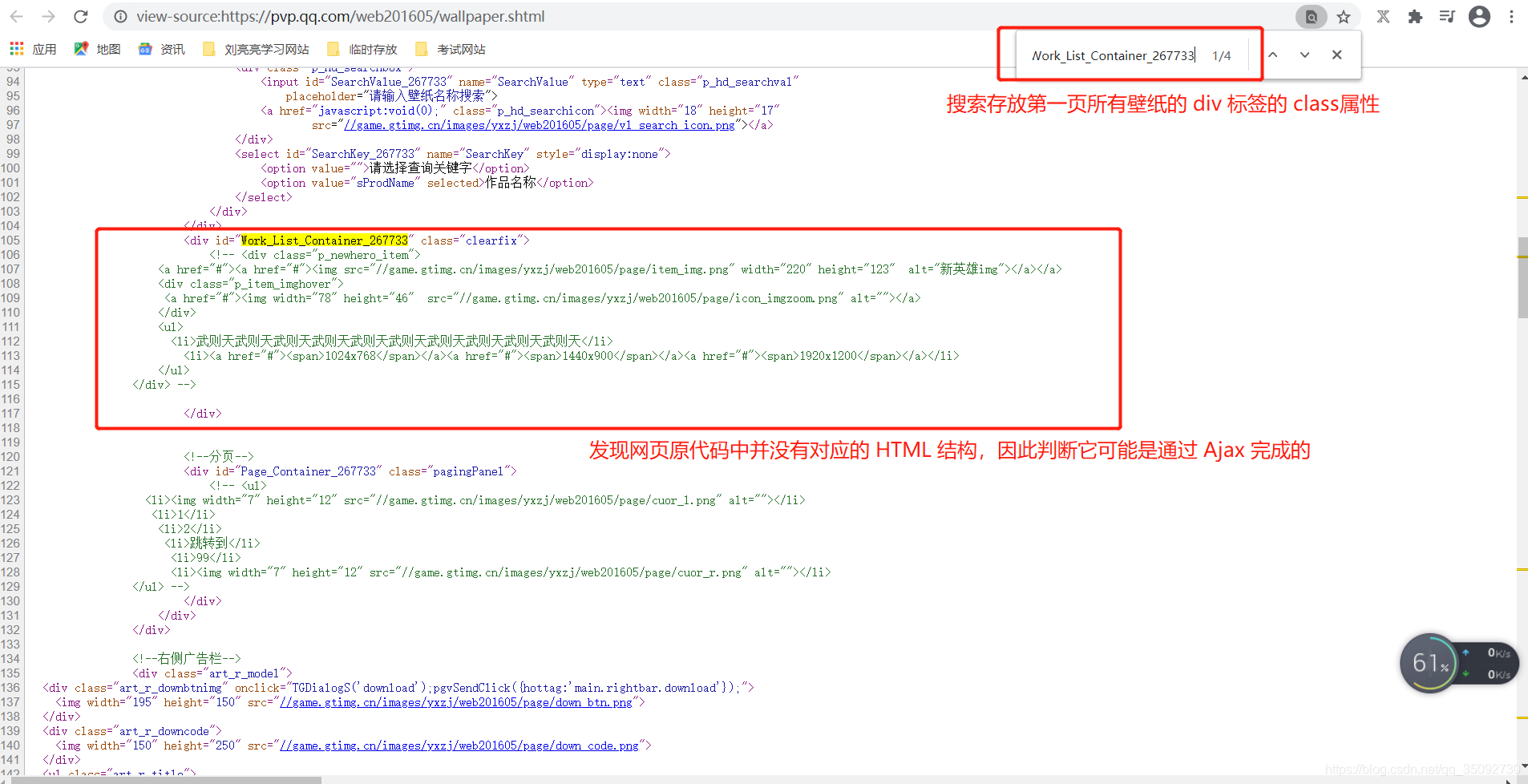
4、查询需要爬取的 HTML 结构对应的 js 请求
1、查询
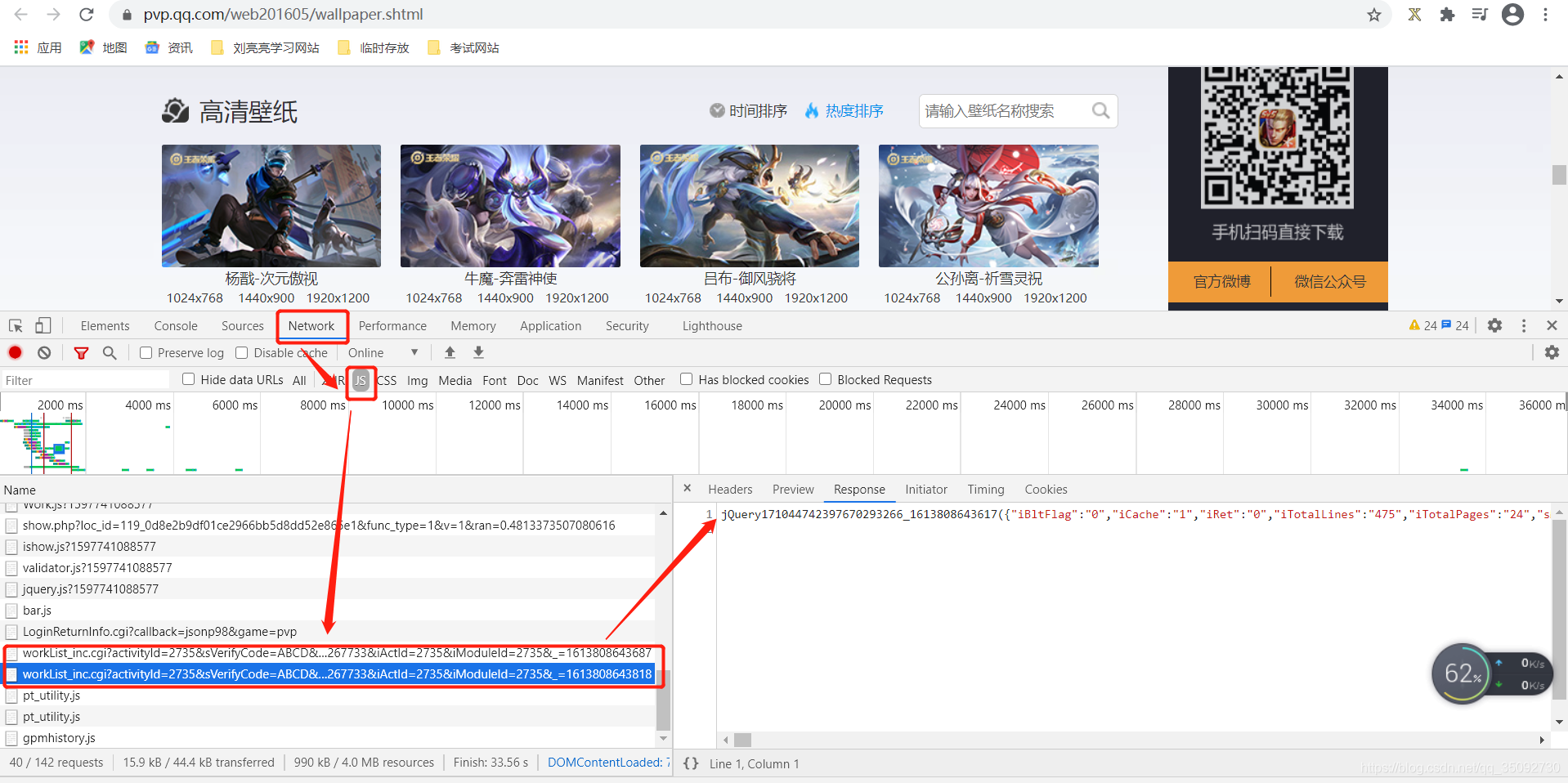
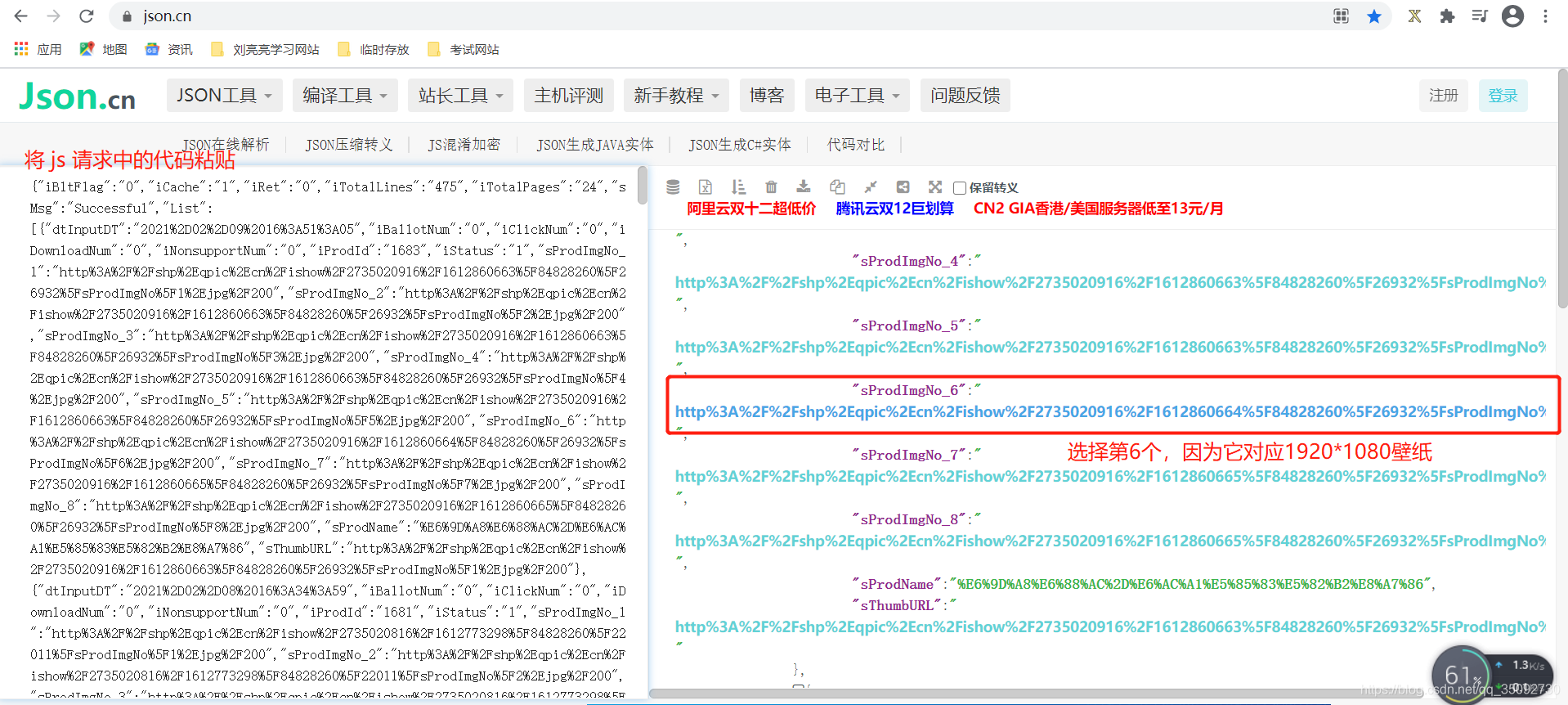
2、通过 https://www.json.cn/分析 json 数据:
3、解码验证
from urllib import parse
url = 'http%3A%2F%2Fshp.qpic.cn%2Fishow%2F2735020916%2F1612860664_84828260_26932_sProdImgNo_6.jpg%2F200' # json数据中第6个对应的 url
res = parse.unquote(url)
print(res)
运行结果:
http://shp.qpic.cn/ishow/2735020916/1612860664_84828260_26932_sProdImgNo_6.jpg/200
4、对比分析:
json 数据解码后的url:
http://shp.qpic.cn/ishow/2735020916/1612860664_84828260_26932_sProdImgNo_6.jpg/200
HTML 结构中的url:
http://shp.qpic.cn/ishow/2735020916/1612860664_84828260_26932_sProdImgNo_6.jpg/0
对比结果:最后的 200 改为 0 即可访问1920*1080的高清壁纸页面
5、确定需要爬取的网页 url
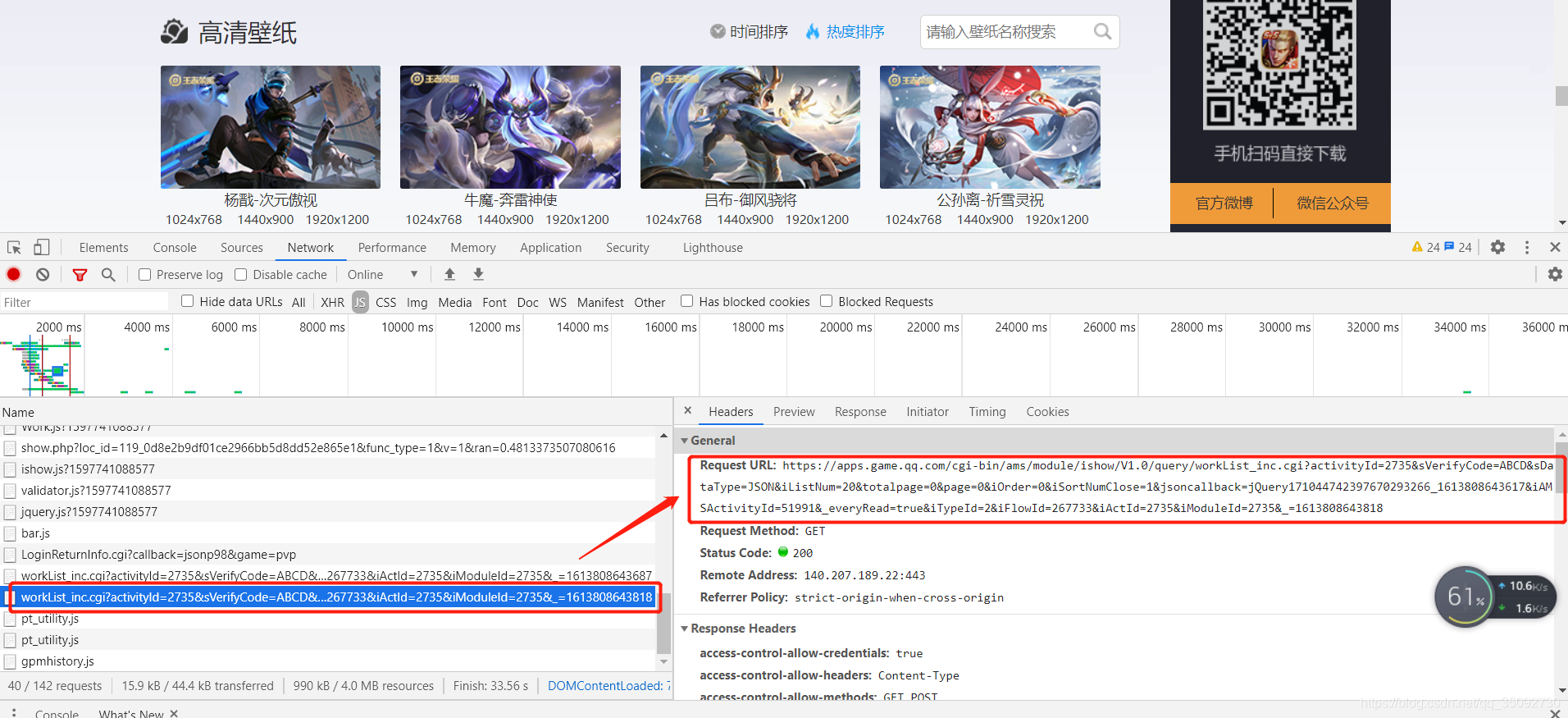
1、分析 url 规则
高清壁纸第一页的 url :
https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=0&iOrder=0&iSortNumClose=1&jsoncallback=jQuery171044742397670293266_1613808643617&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1613808643818
高清壁纸第二页的 url :

https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=1&iOrder=0&iSortNumClose=1&jsoncallback=jQuery17106284635932040199_1613809747608&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1613809773297
对比结果:代码片段中的 “page=0&page=0” 变为了“page=0&page=1”,因此要爬取多页的壁纸只需要修改 page 参数即可,根据 url 提示,一共24页,page的取值区间则为 0~23 。
二、爬虫编写
1、单线程爬取24页1920*1080高清壁纸
import requests
from urllib import parse
from urllib import request
import os
class BiZhiInfos:
def __init__(self):
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
}
self.page_urls = []
for i in range(24):
page_url = f'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page={i}&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1613808643818'
self.page_urls.append(page_url)
def parse_page_url(self, page_url):
resp = requests.get(page_url)
result = resp.json()
datas = result['List']
image_infos =[]
for data in datas:
image_info = parse.unquote(data['sProdImgNo_6']).replace('200', '0') + '|' + parse.unquote(data['sProdName'])
image_infos.append(image_info)
return image_infos
def run(self):
for page_url in self.page_urls:
image_infos = self.parse_page_url(page_url)
for image_info in image_infos:
image_url = image_info.split('|')[0]
image_name = image_info.split('|')[1]
request.urlretrieve(image_url, os.path.join('images', f'{image_name}.jpg'))
print(f'{image_name}已下载完成!')
def main():
bizhi = BiZhiInfos()
bizhi.run()
if __name__ == '__main__':
main()
2、多线程爬取24页1920*1080高清壁纸
import requests
from queue import Queue
from urllib import parse,request
from threading import Thread
import os
class Producer(Thread):
'''生产者负责生产每张图片的 url'''
def __init__(self, page_queue, images_queue, *args, **kwargs):
super(Producer, self).__init__(*args, **kwargs)
self.page_queue = page_queue
self.images_queue = images_queue
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
def run(self) -> None:
while not self.page_queue.empty():
page_url = self.page_queue.get()
resp = requests.get(page_url, headers=self.headers)
result = resp.json()
datas = result['List']
for data in datas:
image_infos = parse.unquote(data['sProdImgNo_6']).replace('200', '0') + '|' + parse.unquote(
data['sProdName'])
self.images_queue.put(image_infos)
class Consumer(Thread):
'''消费者负责下载图片'''
def __init__(self, images_queue, *args, **kwargs):
super(Consumer, self).__init__(*args, **kwargs)
self.images_queue = images_queue
def run(self) -> None:
while True:
try:
image_infos = self.images_queue.get()
image_url = image_infos.split('|')[0]
image_name = image_infos.split('|')[1].replace("1:1", "").strip()
try:
request.urlretrieve(image_url, os.path.join('images', f'{image_name}.jpg'))
print(f'{image_name}下载完成!')
except:
print(f'{image_name}下载失败!', '=='*30)
except:
break
if __name__ == '__main__':
# 创建每一页对应的 url 队列,一共24页
page_queue = Queue(24)
# 创建下载队列
images_queue = Queue(1000)
for i in range(24):
page_url = f'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page={i}&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1613808643818'
page_queue.put(page_url)
for i in range(3):
t = Producer(page_queue, images_queue, name=f'生产者{i}号')
t.start()
for i in range(5):
t = Consumer(images_queue, name=f'消费之{i}号')
t.start()
解释:定义3个生产者负责生产每张图片的 url 和 名字拼接的字符串,定义五个消费者
1、首先通过主线程将24页壁纸的 url 通过 page_queue 队列发送给生产者;
2、每个生产者线程同时取出 page_queue 队列中每一页的 url 取出,然后解析成每张图片的 url 和 名字拼接的字符串,通过 images_queue 队列发送给消费者;
3、每个消费者同时取出 images_queue 队列中的 url 和 名字拼接的字符串,然后下载并命名图片。















 271
271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









