






 本文介绍了希尔排序的分组插入思想,以及计数排序、桶排序和基数排序的具体步骤和优缺点,重点分析了它们的时间复杂度和空间复杂度。
本文介绍了希尔排序的分组插入思想,以及计数排序、桶排序和基数排序的具体步骤和优缺点,重点分析了它们的时间复杂度和空间复杂度。
一、希尔排序(Shell Sort)
希尔排序是和插入排序联合使用的,是一种分组插入排序算法,步骤如下:
1、首先取d1=len(lis)//2,将列表元素分为d1个组,每组间隔为d1,对每个组进行插入排序
2、再取d2=d1//2,将列表分为d2个组,每组间隔为d2,对每个组进行插入排序
3、重复上述步骤,直到d=1,那么列表就是一整个组,对其进行插入排序
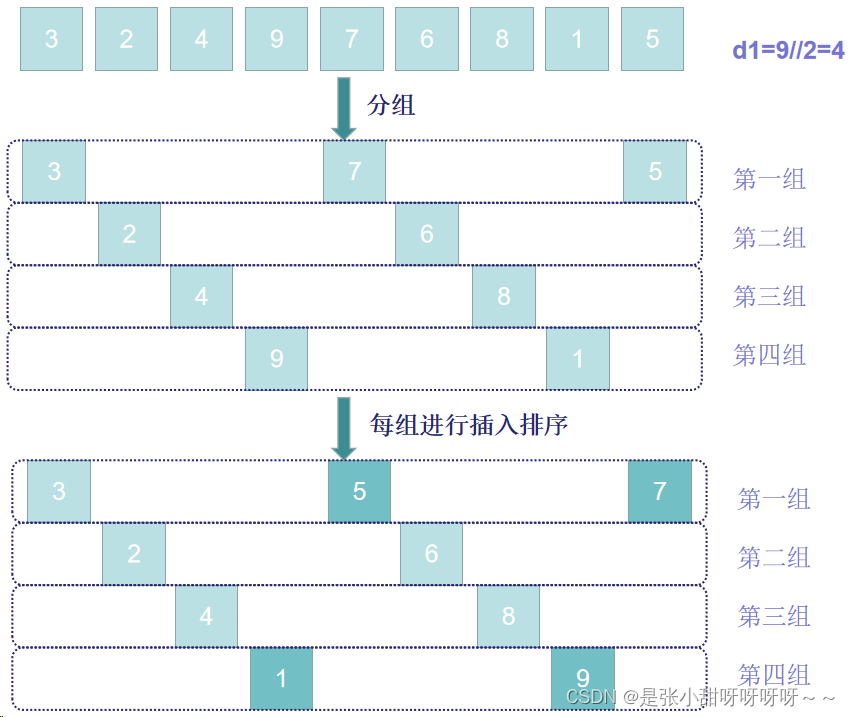
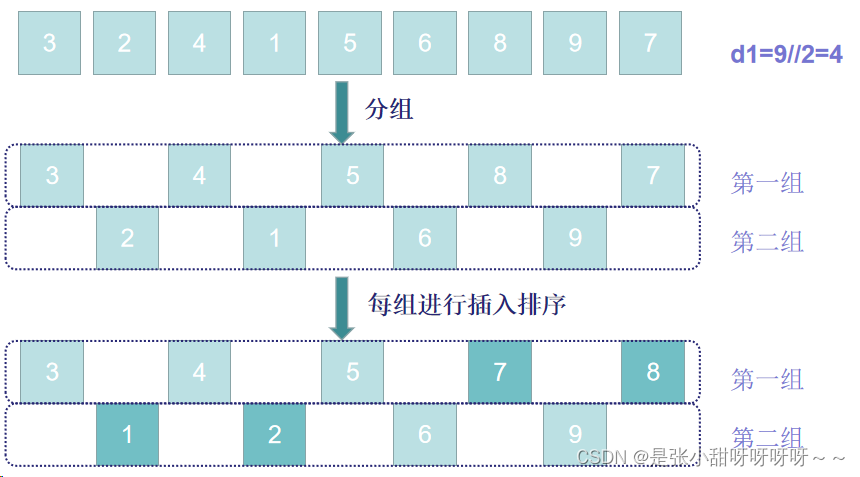
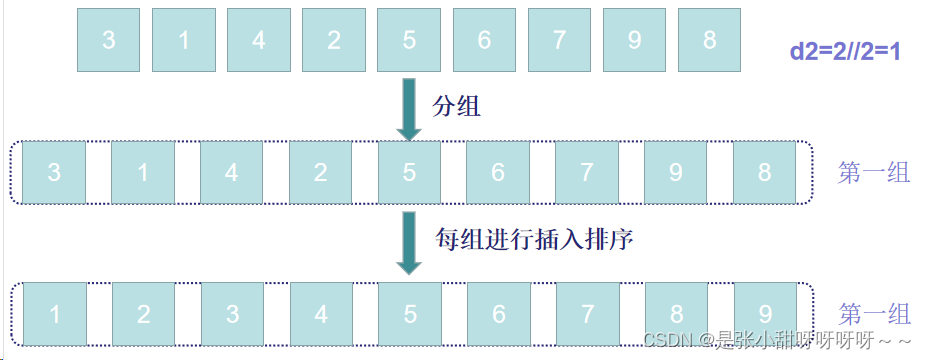
希尔排序每趟并不使元素有序,而是使整体数据越来越接近有序,最后一趟使得所有元素有序
我们对插入排序代码进行修改如下:
def insert_sort_gap(lis, gap):
for i in range(gap, len(lis)):
temp = lis[i]
j = i - gap
while lis[j] > temp and j >= 0:
lis[j + gap] = lis[j]
j -= gap
lis[j + gap] = temp
return lis希尔排序代码:
def shell_sort(lis):
d = len(lis) // 2 # gap
while d >= 1: # 当gap<1时,停止进行分组
insert_sort_gap(lis, d) # 对分好的组进行插入排序
d = d // 2
return lis
item = [i for i in range(99)]
random.shuffle(item)
print(item)
shell_sort(item)
print(item)运行结果:

希尔排序的时间复杂度与选取的gap有关,不好确定
二、计数排序
前提是知道这个列表的范围
假设已知列表lis的范围是0-100的数,对其进行排序
步骤:
1、新建一个全为0,且长度为100+1的列表count,其下标为0-100,
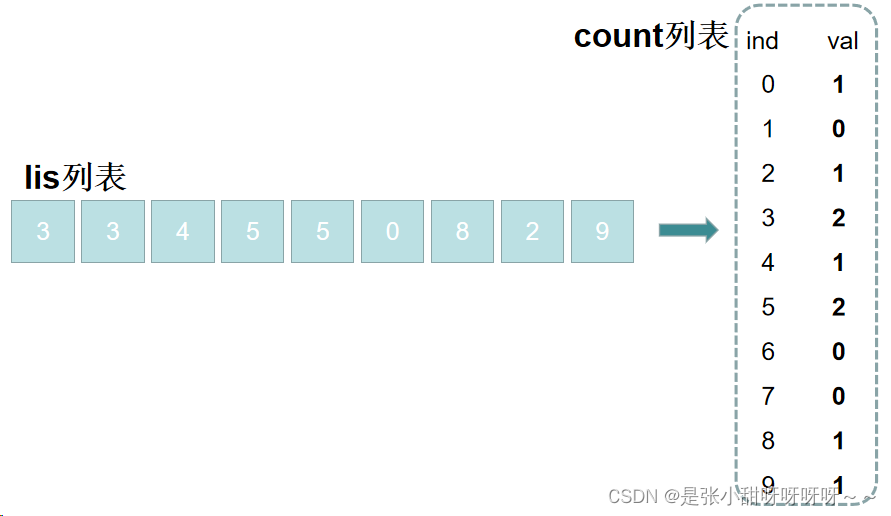
2、遍历lis,当val在列表中,count[val]就加一,这样count中存的就是lis中各个值的数量,且下标就是lis中的值,如下:
3、清空lis,之后遍历count,把值再依次放入lis
代码:
def count_sort(lis, max_count=100): # max_count指lis中最大的值
count = [0 for _ in range(max_count + 1)] # 创建一个全是0,长度为101的列表,这样列表的下标为0-100
for val in lis:
count[val] += 1 # 遍历lis列表,如果val在列表中,那么count列表对应下标上的值就+1
lis.clear()
for ind, val in enumerate(count): # 遍历count列表,把值依次放入list列表中
for i in range(val):
lis.append(ind)
item = [random.randint(0, 100) for _ in range(100)]
print(item)
count_sort(item)
print(item)结果:

时间复杂度:O(n)
第一个for循环时间复杂度为O(n),第二个嵌套for循环,因为是把列表中的值循环放入lis中,循环了n次,所以其时间复杂度也为O(n),两个O(n)就还是O(n)
优点:速度快
缺点:有限制,必须知道列表中的最大值,如果最大值很大,比如[50000,1000000,500,11111111]那么就要创建一个很大的列表,占用空间
三、桶排序(Bucket Sort)
若列表中的值的范围很大,比如0-10000直接,如何进行排序?
将元素分别放在不同的桶中,然后对桶中的元素进行排序,可以全放完了再对每个桶排序,也可以边放边排序
代码示例:
def bucket_sort(lis, max_num=10000, n=100): # 列表最大值为10000,分为100个桶
buckets = [[] for _ in range(n)] # 创建一个二维列表,列表中有n个小列表
for val in lis:
i = val // (max_num // n) # i表示val这个数放在第几个桶里
buckets[i].append(val)
for j in range(len(buckets[i]) - 1, 0, -1): # 对buckets[i]列表倒序遍历,从最后一个值遍历到第二个值
if buckets[i][j] < buckets[i][j - 1]: # 如果刚放进来的值比前一个值小,那么两个值互换,否则就放在原位而不动
buckets[i][j], buckets[i][j - 1] = buckets[i][j - 1], buckets[i][j]
else:
break
# 把所有桶按顺序合并
new_lis = []
for buck in buckets:
new_lis.extend(buck)
return new_lis
item = [random.randint(0, 10000) for _ in range(1000)]
print(item)
print(bucket_sort(item))结果:

总结:
上面的桶排序适合列表中的值的范围较大,且分布较均匀情况下,若数据分布不均匀,则需要采取不同的分桶策略
平均情况时间复杂度:O(n+k)
最坏情况时间复杂度:O(k)
空间复杂度:O(nk)
四、基数排序
把列表中的数按每位排序,先排个位,再排十位,再排百位。。。以此类推,如下:
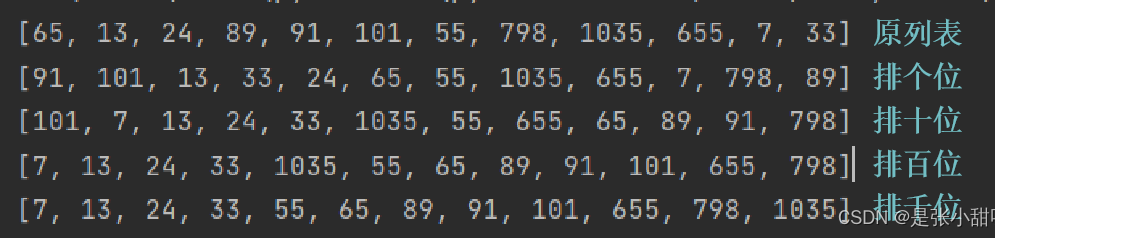
步骤:
1、找出列表中最大的数max_num
2、得出最大值的位数it(可转成str再求长度,也可直接求以10为底的对数,记为lgN)
3、循环it次,先对个位排序,再对十位排序.......
a. 对个位排序:把lis中的数循环放到10个桶中,0桶装个位数为0的数,1桶装个位数为1的数.......全部装完后,再依次从0桶到9桶放回到lis中,这样就对个位进行了依次排序
b.对十位排序:把lis中的数循环放到10个桶中,0桶装十位数为0的数,1桶装十位数为1的数.......全部装完后,再依次从0桶到9桶放回到lis中,这样就对十位进行了依次排序
......
4、输出lis
代码:
# 基数排序
def radix_sort(lis):
max_num = max(lis)
it = 0
while 10 ** it <= max_num:
buckets = [[] for _ in range(10)]
for val in lis:
i = (val // 10 ** it) % 10 # 求个、十、百....位的值,放到对应桶中
buckets[i].append(val)
lis.clear() # 先把lis清空,再把桶中的数挨个放回去
for buck in buckets:
lis.extend(buck)
it += 1
item = [random.randint(0, 10000) for _ in range(1000)]
print(item)
radix_sort(item)
print(item)
时间复杂度:O(kn)
空间复杂度:O(k+n)
----k指while循环执行的次数,即最大数字位数















 3037
3037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









