







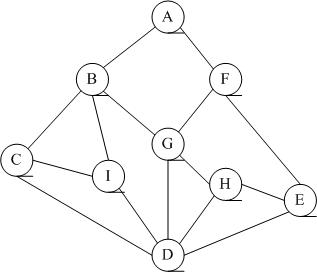
本文以邻接矩阵作为存储结构,用Java实现图的遍历,话不多说,先给出的图的结构,如下:
1、深度优先搜索遍历
思想:
沿着树的深度遍历树的节点,尽可能深的搜索树的分支。当节点v的所有边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。(百度百科)
代码如下:
package com.ds.graph;
public class DFSTraverse {
// 构造图的边
private int[][] edges = { { 0, 1, 0, 0, 0, 1, 0, 0, 0 },
{ 1, 0, 1, 0, 0, 0, 1, 0, 1 }, { 0, 1, 0, 1, 0, 0, 0, 0, 1 },
{ 0, 0, 1, 0, 1, 0, 1, 1, 1 }, { 0, 0, 0, 1, 0, 1, 0, 1, 0 },
{ 1, 0, 0, 0, 1, 0, 1, 0, 0 }, { 0, 1, 0, 1, 0, 1, 0, 1, 0 },
{ 0, 0, 0, 1, 1, 0, 1, 0, 0 }, { 0, 1, 1, 1, 0, 0, 0, 0, 0 } };
// 构造图的顶点
private String[] vertexs = { "A", "B", "C", "D", "E", "F", "G", "H", "I" };
// 记录被访问顶点
private boolean[] verStatus;
// 顶点个数
private int vertexsNum = vertexs.length;
public void DFSTra() {
verStatus = new boolean[vertexsNum];
for (int i = 0; i < vertexsNum; i++) {
if (verStatus[i] == false) {
DFS(i);
}
}
}
// 递归深搜
private void DFS(int i) {
System.out.print(vertexs[i] + " ");
verStatus[i] = true;
for (int j = firstAdjVex(i); j >= 0; j = nextAdjvex(i, j)) {
if (!verStatus[j]) {
DFS(j);
}
}
}
// 返回与i相连的第一个顶点
private int firstAdjVex(int i) {
for (int j = 0; j < vertexsNum; j++) {
if (edges[i][j] > 0) {
return j;
}
}
return -1;
}
// 返回与i相连的下一个顶点
private int nextAdjvex(int i, int k) {
for (int j = (k + 1); j < vertexsNum; j++) {
if (edges[i][j] == 1) {
return j;
}
}
return -1;
}
// 测试
public static void main(String[] args) {
new DFSTraverse().DFSTra();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
2、广度优先搜索遍历
思想:
从根节点开始,沿着树的宽度、按照层次依次遍历树的节点;
代码如下:
package com.ds.graph;
import java.util.LinkedList;
import java.util.Queue;
public class BFSTraverse_0100 {
// 构造图的边
private int[][] edges = { { 0, 1, 0, 0, 0, 1, 0, 0, 0 },
{ 1, 0, 1, 0, 0, 0, 1, 0, 1 }, { 0, 1, 0, 1, 0, 0, 0, 0, 1 },
{ 0, 0, 1, 0, 1, 0, 1, 1, 1 }, { 0, 0, 0, 1, 0, 1, 0, 1, 0 },
{ 1, 0, 0, 0, 1, 0, 1, 0, 0 }, { 0, 1, 0, 1, 0, 1, 0, 1, 0 },
{ 0, 0, 0, 1, 1, 0, 1, 0, 0 }, { 0, 1, 1, 1, 0, 0, 0, 0, 0 } };
// 构造图的顶点
private String[] vertexs = { "A", "B", "C", "D", "E", "F", "G", "H", "I" };
// 记录被访问顶点
private boolean[] verStatus;
// 顶点个数
private int vertexsNum = vertexs.length;
// 广搜
private void BFS() {
verStatus = new boolean[vertexsNum];
Queue<Integer> temp = new LinkedList<Integer>();
for (int i = 0; i < vertexsNum; i++) {
if (!verStatus[i]) {
System.out.print(vertexs[i] + " ");
verStatus[i] = true;
temp.offer(i);
while (!temp.isEmpty()) {
int j = temp.poll();
for (int k = firstAdjvex(j); k >= 0; k = nextAdjvex(j, k)) {
if (!verStatus[k]) {
System.out.print(vertexs[k] + " ");
verStatus[k] = true;
temp.offer(k);
}
}
}
}
}
}
// 返回与i相连的第一个顶点
private int firstAdjvex(int i) {
for (int j = 0; j < vertexsNum; j++) {
if (edges[i][j] > 0) {
return j;
}
}
return -1;
}
// 返回与i相连的下一个顶点
private int nextAdjvex(int i, int k) {
for (int j = (k + 1); j < vertexsNum; j++) {
if (edges[i][j] > 0) {
return j;
}
}
return -1;
}
// 测试
public static void main(String args[]) {
new BFSTraverse_0100().BFS();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
二:
- import java.util.*;
- /**
- * 这个例子是图的遍历的两种方式
- * 通过它,使我来理解图的遍历
- * Created on 2013-11-18
- * @version 0.1
- */
- public class DeptSearch
- {
- public static void main(String args[]){
- //构造需要点对象
- NodeT a=new NodeT("a");
- NodeT b=new NodeT("b");
- NodeT c=new NodeT("c");
- NodeT d=new NodeT("d");
- NodeT e=new NodeT("e");
- NodeT f=new NodeT("f");
- NodeT g=new NodeT("g");
- NodeT h=new NodeT("h");
- ArcT ab=new ArcT(a,b);
- ArcT ac=new ArcT(a,c);
- ArcT ad=new ArcT(a,d);
- ArcT ah=new ArcT(a,h);
- ArcT bc=new ArcT(b,c);
- ArcT de=new ArcT(d,e);
- ArcT ef=new ArcT(e,f);
- ArcT eg=new ArcT(e,g);
- ArcT hg=new ArcT(h,g);
- //建立它们的关系
- a.outgoing.add(ab);
- a.outgoing.add(ac);
- a.outgoing.add(ad);
- a.outgoing.add(ah);
- b.outgoing.add(bc);
- d.outgoing.add(de);
- e.outgoing.add(ef);
- e.outgoing.add(eg);
- h.outgoing.add(hg);
- //构造本对象
- DeptSearch search=new DeptSearch();
- //广度遍历
- System.out.println("广度遍历如下:");
- search.widthSearch(a);
- //深度遍历
- System.out.println("深度遍历如下:");
- List<NodeT> visited=new ArrayList<NodeT>();
- search.deptFisrtSearch(a,visited);
- }
- /*
- * 深度排序的方法
- * 这个方法的方式:按一个节点,一直深入的找下去,直到它没有节点为止
- * cur 当前的元素
- * visited 访问过的元素的集合
- */
- void deptFisrtSearch(NodeT cur,List<NodeT> visited){
- //被访问过了,就不访问,防止死循环
- if(visited.contains(cur)) return;
- visited.add(cur);
- System.out.println("这个遍历的是:"+cur.word);
- for(int i=0;i<cur.outgoing.size();i++){
- //访问本点的结束点
- deptFisrtSearch(cur.outgoing.get(i).end,visited);
- }
- }
- /**
- * 广度排序的方法
- * 这个方法的方式:按层次对图进行访问,先第一层,再第二层,依次类推
- * @param start 从哪个开始广度排序
- */
- void widthSearch(NodeT start){
- //记录所有访问过的元素
- Set<NodeT> visited=new HashSet<NodeT>();
- //用队列存放所有依次要访问元素
- Queue<NodeT> q=new LinkedList<NodeT>();
- //把当前的元素加入到队列尾
- q.offer(start);
- while(!q.isEmpty()){
- NodeT cur=q.poll();
- //被访问过了,就不访问,防止死循环
- if(!visited.contains(cur)){
- visited.add(cur);
- System.out.println("查找的节点是:"+cur.word);
- for(int i=0;i<cur.outgoing.size();i++){
- //把它的下一层,加入到队列中
- q.offer(cur.outgoing.get(i).end);
- }
- }
- }
- }
- }
- /**
- * 图的点
- */
- class NodeT
- {
- /* 点的所有关系的集合 */
- List<ArcT> outgoing;
- //点的字母
- String word;
- public NodeT(String word){
- this.word=word;
- outgoing=new ArrayList<ArcT>();
- }
- }
- /**
- * 单个图点的关系
- */
- class ArcT
- {
- NodeT start,end;/* 开始点,结束点 */
- public ArcT(NodeT start,NodeT end){
- this.start=start;
- this.end=end;
- }
- }















 1856
1856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









