









论文:Integration of image quality and motion cues for face anti-spoofing: A neural network approach
翻译:摘要
针对人脸认证的安全性,提出了多种针对特征的人脸欺骗攻击策略。然而,目前还没有一种优越的人脸反欺骗技术来处理各种场景下的欺骗攻击。为了提高人脸抗欺骗方法的泛化能力,提出了一种基于层次神经网络的人脸抗欺骗扩展多线索集成框架,该框架能够融合图像质量线索和运动线索进行活度检测。利用Shearlet构造了一种基于图像质量的活性特征。利用密集光流提取基于运动的活性特征。瓶颈特征融合策略能够有效地融合不同的活性特征。在三个公共人脸抗欺骗数据库上对该方法进行了评估。在重放攻击数据库和3D-MAD数据库上,总错误率(HTER)为0%,平均错误率(EER)为0%。CASIA-FASD数据库的能效比为5.83%。
1. Introduction
人脸识别由于其非侵入性和自然交互的特点,在用户认证系统中得到了广泛的应用[1 3]。人脸认证的安全性要求非常高,因为只有摄影、视频回放或3Dmask才能很容易地欺骗人脸识别系统,非法访问安全信息[4]。有效用户的照片和视频很容易获得,尤其是通过社交网络。因此,除了人脸识别模块外,人脸抗欺骗干扰模块是人脸认证系统必不可少的。近年来,人脸欺骗攻击的防御策略受到了广泛的关注。基于不同的[5]方法,提出了多种人脸抗欺骗算法。建立了多个面向公众的反欺骗数据库[6 8]。针对人脸欺骗攻击的对策竞争促进了人脸活性检测的发展
人脸图像质量、人脸运动和风景运动为人脸抗欺骗提供了不同的活性线索。基于图像质量或基于运动的方面,如局部二值模式(LBP)和光流直方图(HOOF),已经提出了多种手工设计的特征来描述活性提示[10,11]。本文利用shearlet变换作为图像质量描述符,对真假人脸进行识别。与常用的局部纹理模式特征LBP相比,shearlet变换更有效地表示分布的不连续点,以方向小波[12]的形式在图像中提供多尺度、多方向的各向异性描述。在运动线索方面,将原始光流量(OFM)直接输入自编码神经网络,分别在裁剪后的人脸区域和整个场景中学习基于运动的活性特征。与以往基于运动的特征相比,本文没有使用运动假设或统计模型来设置运动先验。因此,提出的基于运动的活性特征可以在不同场景设置的人脸抗欺骗数据库中实现更广泛的泛化。
由于攻击场景和环境条件的不同,没有绝对优越的人脸抗欺骗技术。基于图像质量和基于运动的视觉线索的活性特征相结合,为提高人脸抗欺骗分类器的泛化和稳定性提供了一个有前途的方向。目前最先进的人脸欺骗干扰对策都采用特征融合或分数融合的方法,例如时空纹理描述符,在第二届二维对抗策略竞赛中获胜的算法面临欺骗干扰攻击[9],以及互补的对抗策略。目前,在特征层次上采用特征向量的直接拼接或在分数层次上采用融合的方法得到了广泛的应用。针对不同的视觉线索,提出了一种具有不同活性特征的融合策略。提出了一种基于神经网络的特征融合框架,用于对多类活动线索的特征进行融合。所采用的自编码神经网络不仅是一个有监督的分类器,而且可以生成瓶颈特征,即对神经网络[15]的原始输入进行压缩稀疏表示。瓶颈特征可以在单位尺度幅度[16]的降维中更有效地表示原始输入。因此,从不同的视觉线索中学习到的活性瓶颈特性可以不需要缩放就可以连接起来。融合后的瓶颈特征可以输入后续的神经网络进行最终的活性检测。该层次神经网络可以综合多种视觉线索的活性特征,学习一种互补的对抗欺骗攻击的策略。考虑到用户友好性和便捷性,本文没有讨论挑战响应和多模态方法,因为这里追求的是一种对用户透明的人脸抗欺骗方法
与以往工作相比,本文的贡献可以概括为:
(1)利用Shearlet变换进行人脸图像质量评价,比常用的LBP算法具有更好的图像质量描述
(2)利用神经网络分别从裁剪后的人脸区域和整个场景的原始光流信息中自动学习基于运动的活性特征。为了追求基于运动的特征的泛化,没有采用运动假设或场景模型进行人脸抗欺骗
(3)提出了一种基于层次神经网络的特征融合框架,用于融合基于图像质量和基于动作的活度线索。与现有方法相比,该方法具有较高的人脸抗欺骗分类精度
本文的其余部分组织如下。第二部分简要回顾了目前最先进的反欺骗干扰方法。第3节详细解释了提出的特征融合框架。第四部分介绍了本文使用的三个公共人脸抗欺骗数据库。在这三个公共数据库上进行了大量的实验,并在第5节中报告了相应的结果。最后,对全文进行了总结
第二部分就不翻译了,直接翻译第三部分
3 The proposed approach
提出的基于多线索融合的人脸抗欺骗方法结合了三个方面的活性特征:shearlet-based图像质量特性(SBIQF),光学flowbased面对运动特性,和光学流转场景运动特性,如流程图所示图1,X(i,k);我是第i个元素的输入向量k子提示,; X(i,k)1 是激活学习i主要特性的隐层k子 H(i)2是学习i主要功能激活第二个隐藏层的集成神经网络,和P(y=C|x)类的概率是(真/假),输入x。
首先,从归一化的人脸图像中提取SBIQF向量。使用Viola Jones人脸检测器确定人脸坐标,并与眼睛位置[29]对齐。利用图1中的第一个子网络,得到了SBIQF的瓶颈表示。其次,使用与前一步相同的人脸坐标和归一化过程采集人脸视频。计算了具有固定间距的人脸帧间的密集光流。通过对人脸视频中的OFM信息进行平均,得到了描述人脸运动模式的平均OFM图。将该平均面OFM映射映射到第二个子网络中,提取瓶颈表示。第三,从场景视频中计算出m地图的平均场景,即提取人脸视频的原始视频,利用场景OFM映射作为第三个子网络的输入,得到一个瓶颈表示,最后,将来自三种不同活性线索的三种瓶颈表示形式串联为融合的瓶颈特征,并将其输入后续的神经网络进行活性检测。最后使用两类softmax分类器确定活性状态。如图1所示,隐藏层II之前的三个子网络分别与来自三个不同视觉线索的输入进行局部连接。三个子网络分别训练。在隐藏层II,融合瓶颈特征与以下网络完全连接。使用隐含层i对隐含层II进行分层智能训练。流程图中核心模型的详细介绍如下:
3.1. Autoencoder and softmax classifier
自动编码器是一种神经网络,它试图学习对恒等函数的逼近,从而输出类似于x[15]的^x,如图2所示。给出了优化自动编码器的代价函数
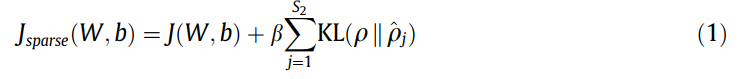
J(W,b)的成本函数是autoencoder学习恒等函数,Jsparse(W;b)Þautoencoder的稀疏约束成本函数,p是稀疏参数,问p(j) 是平均激活隐藏的单元,KL是Kullback Leibler散度函数来衡量p之间的区别和p(j) S2是隐层神经元的数量,β是稀疏惩罚项的重量。通过放置降维隐层和稀疏约束,可以得到输入的压缩稀疏表示,作为瓶颈表示。然后,将学习到的瓶颈表示作为软最大分类器的输入,构建分类神经网络,如图3所示。
通过使用标记数据集的反向传播对整个神经网络进行全局微调。自编码训练可以看作是一个预训练过程,为神经网络优化提供了一个良好的初始解。然后利用标记数据对自动编码器和softmax分类器的参数进行微调,进一步改善了活度分类的瓶颈表示,减少了训练时间。本文采用先训练后微调的方法对三种视觉线索的三个子网络和特征融合网络进行训练。具有多个隐藏层的堆叠自动编码器可以分层进行明智的训练。并利用带标签的数据和软最大分类器对展开的叠置自编码器进行微调。深度学习[30]的核心思想是分层预训练和微调。由于神经网络中使用的乙状元活动函数,瓶颈表示被自动缩放到0到1之间,适用于融合不同尺度的多线索特征
3.2. Shearlet-based image quality feature
由于缺乏方向描述符,传统的小波分析方法不能有效地逼近图像中的曲线奇异性。为了克服小波变换的缺点,近年来提出了shearlet算法,该算法能够有效地捕获多维数据[12]的各向异性特征。Shearlet变换作为一种最先进的[31]方法,已成功地用于非参考图像质量评价。与真实人脸相比,欺骗人脸可能具有锐度降低、纹理差异、附加噪声和伪影,这些都是由于欺骗干扰介质上的人脸复制造成的。与LBP和DoG相比,shearlet能更好地描述曲线奇异性



包括边缘、纹理和工件。基于shearlet的图像质量评估在检测欺骗人脸的模糊边缘和扭曲纹理、人脸复制(视频编码、打印等)引起的各向异性伪影、真实人脸皮肤与欺骗介质之间的纹理差异等方面具有优势,同时,shearlet还可以描述欺骗面各向同性噪声和伪影。因此,提出的基于图像质量的活性特征是基于剪切的。对于二维图像中,具有复合膨胀的仿射系统是形式的集合

Aa为各向异性膨胀矩阵,Bs为剪切矩阵。由于与shearlet变换相关的分析函数是各向异性的,并且定义在不同的尺度、位置和方向上,shearlet能够检测方向信息并解释多维函数的几何。从人脸图像的剪切变换为不同的子带开始,总结了SBIQF的计算过程如图4所示。子带中red1框中的每个元素定义为

当a=1…,A为尺度指数(不含最粗尺度),s=1…,S为方向指数,b=1…(M/m)的平方 是每个副环带的块索引。M为正方形图像的大小,m为每个红色块的大小。SH φ(a,s,b);代表每个红色方块的剪切系数。在每个红色块中执行剪切系数的平均池化。合并后的值被连接为一个矢量,服从对数非线性
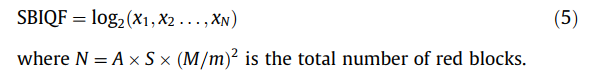
3.3. Optical flow-based motion feature
光流可以根据给定图像序列的局部导数描述局部图像运动。在假定光强恒定和空间平滑的前提下,通过求解运动约束方程可以计算出光流

I 是在(x,y,t)的图像强度;V(x)和V(y)是光流的x和y分量,描述局部的像素翻译。本文采用了一种基于迭代重加权最小二乘法(IRLS)的密集光流技术。光流同时描述了运动方向和运动幅度。这里只使用运动幅度信息
与之前相比手工各自面临活性特性,提出了基于流的运动光学特性不依赖于任何预定义的模型或假设之前,但等真正面临[24],非刚性的面部表情[25],平面运动模式摄影脸上[26],和低运动一致性真正的脸和背景[27],由于在不同的欺骗场景下,很难建立通用的运动模型来描述人脸反欺骗的运动线索。OFM地图可以捕捉面部或场景中的每一个动作。神经网络善于学习内隐模式,通过适当的训练,能够识别人脸活动检测的运动线索。因此,选择OFM映射来描述基于动作的线索,以便学习如何处理不同的欺骗攻击。

在活体检测过程中,会录制一个短视频(62秒)。然后,使用一个简单的眼睛位置归一化方法提取人脸视频。在固定间隔的两帧之间进行密集光流计算,得到一种描述两帧之间像素级运动轨迹的OFM图。利用密集光流方法,利用人脸视频中的帧对生成多个人脸OFM图。利用这些人脸OFM地图的平均值来记录人脸的运动模式,如图5(a)所示。从全帧视频中计算出m地图的平均场景,如图5(b)所示。在m地图的平均场景中,可以记录背景中的景物运动线索。人脸区域或身体区域不排除用于计算场景OFM地图,因为在人脸抗欺骗中很难定义统一的前景/背景模型。将平均人脸/场景OFM图分别列化为基于人脸运动的子神经网络和基于场景运动的子神经网络的两个输入向量。
基于欺骗干扰介质对人脸的表示方式,二维人脸欺骗攻击可以分为两类:特写欺骗和风景欺骗。特写式恶搞只描述了呈现给传感器的面部区域,在此过程中,照片/屏幕边缘和攻击者的手在现场都是可见的。与近距离恶搞相比,风景脸恶搞在恶搞中融入了背景场景。在传感器附近放置一张假脸,以隐藏中间的边界或人手。
人脸欺骗攻击中会出现一些典型的运动模式,这与真实访问中的运动模式是有区别的。例如,图6(a)显示了真实面部的平均OFM映射,其中非刚性局部面部运动集中于面部组件。由于不自觉的握手,在相纸上显示的人脸会产生全球性的运动。然后在人脸和人脸周围的背景上都可以观察到相似的OFM,如图6(b)所示。在视频回放设备的镜面屏幕上经常出现镜面反射,利用OFM图也可以检测到镜面反射,如图6©所示。
口罩会覆盖除眼睛运动外的局部面部运动,并在口罩上记录均匀的运动模式OFM图,如图6(d)所示。一个清晰的人脸轮廓出现在m地图的场景中,以便真实访问,如图7(A)所示。风景优美的恶搞,如果不支持显示介质稳定,对面的一个全球运动帧可以检测到如图7所示(b)。特写恶搞,可疑的手和边界的运动录像回放设备现场胶卷暗盒地图上可以观察到,如图7所示©。



下面是介绍的数据集,我就不翻译了
接下来是实验结果


这篇论文就翻译到这吧,论文全是用的有道词典翻译的,大家可以适当的修改,谢谢大家的观看。















 313
313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









