






python-pandas的基本总结
结合最近一段时间学习写的一个pandas总结。
一、Series对象的生成:
pd.Series(单个列表)
1、用数组生成,默认索引
例如:data = pd.Series([1, NA, 3.5, NA, 7])
二、DataFrame对象的生成:
1、pd.DataFrame(多个列表)
例如:data = pd.DataFrame([[1., 6.5, 3.], [1., NA, NA],[NA, NA, NA], [NA, 6.5, 3.]])
2、用矩阵生成
例如:data = pd.DataFrame(np.random.randn(7,3))
3、用字典生成
例如:data=pd.DataFrame({‘k1’: [‘one’, ‘two’] * 3 + [‘two’],‘k2’: [1, 1, 2, 3, 3, 4, 4]})

4、用index和columns生成
例如:data = pd.DataFrame(np.arange(12).reshape((3,4)),index = [‘Ohio’, ‘Colorado’, ‘New York’],columns = [‘one’, ‘two’, ‘three’, ‘four’])
例如:
data = {‘BoolCol’: [1, 2, 3, 3, 4], ‘attr’: [22, 33, 22, 44, 66], ‘BoolC’: [1, 2, 3, 3, 4], ‘att’: [22, 33, 22, 44, 66], ‘Bool’: [1, 2, 3, 3, 4]}
df = pd.DataFrame(data,index=[10,20,30,40,50])
三、DataFrame对象创建新的一列/行:
1、添加一列数据,,把dataframe如df1中的一列或若干列加入另一个dataframe,如df2
思路:先把数据按列分割,然后再把分出去的列重新插入
df1 = pd.read_csv(‘example.csv’)
(1)首先把df1中的要加入df2的一列的值读取出来,假如是’date’这一列
date = df1.pop(‘date’) ##使用pop后,df1中的‘date’列被取出,即df1中不存在该列
(2)将这一列插入到指定位置,假如插入到第一列
df2.insert(0,‘date’,date) ##将取出的列插入到df2中,并且列名为‘date’
(3)默认插入到最后一列
df2[‘date’] = date
2、直接使用列索引赋值的形式添加,这种方式直接加到末尾
data:
data:
例如:
data[‘d’] = [5,6]
data[‘c’] = ‘’ ##增加空列

3、在指定的位置添加新的一列,可以使用insert( )方法。
例如:
data.insert(2,‘c’,’’) #### 2:插入的列的位置(即第三列); ‘c’:待插入列的列名;‘ ’:插入的值,这里插入的是空值
data.insert(0,‘d’,[1,2]) ##在第一列插入‘d’列,值为[1,2]
4、在data后面添加多列,使用pd.concat 方法
例如:
data1=pd.concat([data, pd.DataFrame(columns=list(‘DE’))])
data1
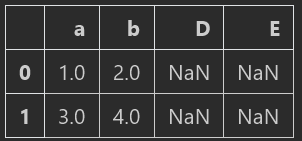
5、使用reindex方法,不仅可以增加列,还可以改变各列的相对位置,且保留原始列的数值
例如:
data2=data.reindex(columns=list(‘bCaDE’))
data2
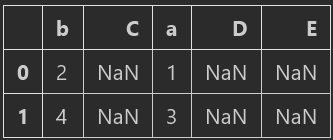
reindex 还有 fill_value 选项,可以填充NaN,
例如:
data2=data.reindex(columns=list(‘bCaDE’), fill_value=1)
data2
6、当列个数很多时,用上述方法不方便,可以采取list.insert的方法—先获取dataframe原列名集合, 赋值给新变量,然后 insert
例如:
col_name = data.columns.tolist() ##获取data原列名集合
col_name.insert(1,‘D’) ##使用list.insert(index, obj)方法:index – 对象obj需要插入的索引位置;obj – 要插入列表中的对象。刚插入时不会有值,整列都是NaN
data3=data.reindex(columns=col_name)

也可以不用数字索引,直接在某列前面或后面插入,利用 list.index的方法
例如:col_name.insert(col_name.index(‘B’),‘D’) # 在 B 列前面插入
例如:col_name.insert(col_name.index(‘B’)+1,‘D’) # 在 B 列后面插入
7、直接在末尾增加新的一行
例如:data.loc[‘3’] = [5,6]

8、使用append方法增加行
例如:
new_data = pd.DataFrame(columns=[‘a’,‘b’], data=[[5,6],[9,0]])
data4=data.append(new_data,ignore_index=True) # ignore_index=True,表示不按原来的索引,从0开始自动递增

三、用pandas中的DataFrame时选取行或列
data:
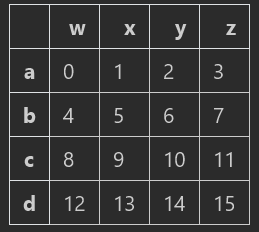
引用dataframe中的某一列的方法:
1、例如:data.w #选择表格中的’w’列,使用点属性,返回的是Series类型;
2、例如:data[‘w’] #选择表格中的’w’列,使用类字典属性,返回的是Series类型;
3、例如:data[[‘w’]] #选择表格中的’w’列,返回的是DataFrame属性;
4、例如data[[‘w’,‘z’]] #选择表格中的’w’、'z’列;
引用dataframe中的某一行的方法:
1、data[0:2] #返回第1行到第2行的所有行,前闭后开,包括前不包括后;
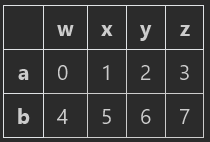
2、data[1:2] #返回第2行,从0计,返回的是单行,通过有前后值的索引形式,如果采用data[1]则报错;
##############data.ix[1:2] #返回第2行##############
3、data[‘a’:‘b’] #利用index值进行切片,返回的是前闭后闭的DataFrame, 即末端是包含的;
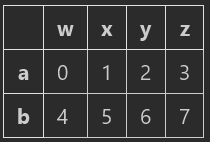
4、data.iloc[-1] #选取DataFrame最后一行,返回的是Series;
5、data.iloc[-1:] #选取DataFrame最后一行,返回的是DataFrame;
6、data.loc[‘a’] #选择表格中的’a’行,返回的是Series类型;
7、data.loc[‘a’:‘c’] ##选择表格中的’a’到’c’的连续多行,返回的是DataFrame

##############data.irow(0) #取data的第一行##############
loc和iloc的区别:loc是根据index来索引,比如data定义了一个index:[‘a’, ‘b’, ‘c’, ‘d’],那么loc就根据这个index来索引对应的行。iloc并不是根据index来索引,而是根据行号来索引,行号从0开始,逐次加1。
引用dataframe中的指定行指定列的方法:
1、data.loc[‘a’,[‘w’,‘x’]] #返回‘a’行’w’、'x’列,这种用于选取行索引列索引已知,返回的是Series;
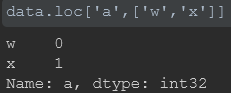
2、data.loc[[‘a’],[‘w’,‘x’]] #返回‘a’行’w’、'x’列,这种用于选取行索引列索引已知,返回的是DataFrame;

3、data.loc[‘a’:‘c’,[‘w’,‘x’]] #返回‘a’到’c’行’w’、'x’列,这种用于选取行索引列索引已知,返回的是DataFrame;

4、data.loc[‘a’:‘c’,‘w’:‘y’] ##读取’a’:'c’行,‘w’:'y’列的数据;
5、data.iloc[0:2,1:3] #返回第一行和第二行对应的第二列和第三列;

6、data.iloc[0,1:3] #读取第一行,第二列和第三列列的数据;
7、data.iloc[[0,2],1:3] #读取第一行第三行,第二列和第三列列的数据;

8、data.iat[1,1] #选取第二行第二列,用于已知行、列位置的选取

四、DataFrame删除列的方法:
1、使用drop方法
(1)已知列名
df.drop([“列名”],axis=1) 例子:df1.drop([“handsome”,“smart”],axis=1) #删除列名为handsome和smart的整列 df1.drop([0,1])#删除索引为0、1的整行
df.drop(columns=[“列名”]) 例子:df1.drop(columns=[“handsome”,“smart”])#删除列名为handsome和smart的整列
(2)列名未知,或无列名
将列索引读取出来,例如:
df:

columns=df.columns
df.drop(columns[0:2],axis=1)

将列索引读取为列表,利用该列表删除
例子(使用data_columns[0]删除第一列):

2、直接选择要保留下来的列
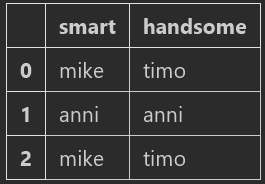
例如把‘beautiful’列删除并将‘handsome’和‘smart’两列交换
columns=df.columns
df1=df[[columns[1],columns[0]]]
3、直接del DF[‘column-name’]
五、DataFrame中apply函数的使用方法:
python中 apply()函数的用法 -------------apply()是python2中的全局函数,python3中已经不支持apply函数了
函数格式为:apply(func,*args,**kwargs)------当一个函数的参数存在于一个元组或者一个字典中时,用来间接的调用这个函数,并将元组或者字典中的参数按照顺序传递给参数。apply()的返回值就是func()的返回值,apply()的元素参数是有序的,元素的顺序必须和func()形式参数的顺序一致
DataFrame.apply(func, axis=0, broadcast=False, raw=False, reduce=None, args=(), **kwds)
1、该函数最有用的是第一个参数,这个参数是函数,相当于C/C++的函数指针。
2、这个函数需要自己实现,传入的函数具体是对每一行还是每一列进行操作,取决于apply传入的axis参数,默认axis=0,表示对每一列进行操作,axis=1,表示对每一行进行操作。
例子
df:

1、将函数应用到由各列或行形成的一维数组上。DataFrame的apply方法可以实现此功能:
默认情况下会以列为单位,分别对列应用函数
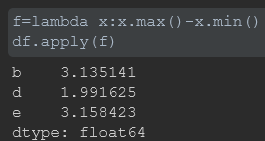
也可以通过axis=1对每一行进行操作:
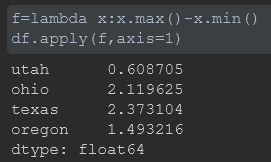
2、除标量外,传递给apply的函数还可以返回由多个值组成的Series
例子:
def f(x):
return pd.Series([x.min(),x.max()],index=[‘min’,‘max’])
df.apply(f)
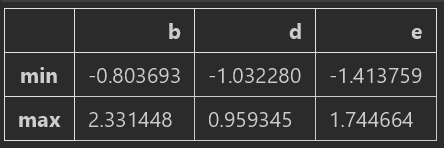
3、元素级的python函数,将函数应用到每一个元素
例子:DataFrame中的各个浮点值保留两位小数
f=lambda x: ‘%.2f’%x
df.applymap(f) #注意,这里之所以叫applymap,是因为Series有一个永远元素级函数的map方法

4、apply方法传入dataframe多列进行函数操作
df[‘a’] = df.apply(lambda row: row[‘b’] + 2 * row[‘d’], axis=1) ##axis=1表示对每一行进行操作,其中x带表当前行,通过下标进行索引。

另外一种方法通过定义带参数的函数实现:
def f(x,y):
return x+2*y
df['e']=df.apply(lambda row: f(row['b'],row['d']),axis=1)
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









