






注:使用拉普拉斯修正的朴素贝叶斯分类器的目的是为了避免其他属性携带的信息被训练集中未出现的属性值抹去的情况。
文章目录
1. 贝叶斯公式
1.1 先验概率和后验概率
- 先验概率:由以往的数据分析得到的概率,P(A)是A的先验概率或边缘概率
- 后验概率:在得到信息之后再重新加以修正的概率,P(A|B)是已知B发生后A的条件概率,也由于得知B的取值而被称为A的后验概率。
1.2 贝叶斯公式
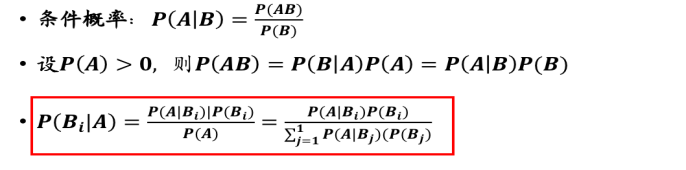
2. 代码实现西瓜书
2.1 数据来源与处理
通过西瓜书数据3.0来预测第一行西瓜的好坏
编号,色泽,根蒂,敲声,纹理,脐部,触感,密度,含糖率,好瓜
1,青绿,蜷缩,浊响,清晰,凹陷,硬滑,0.697,0.46,是
2,乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,0.774,0.376,是
3,乌黑,蜷缩,浊响,清晰,凹陷,硬滑,0.634,0.264,是
4,青绿,蜷缩,沉闷,清晰,凹陷,硬滑,0.608,0.318,是
5,浅白,蜷缩,浊响,清晰,凹陷,硬滑,0.556,0.215,是
6,青绿,稍蜷,浊响,清晰,稍凹,软粘,0.403,0.237,是
7,乌黑,稍蜷,浊响,稍糊,稍凹,软粘,0.481,0.149,是
8,乌黑,稍蜷,浊响,清晰,稍凹,硬滑,0.437,0.211,是
9,乌黑,稍蜷,沉闷,稍糊,稍凹,硬滑,0.666,0.091,否
10,青绿,硬挺,清脆,清晰,平坦,软粘,0.243,0.267,否
11,浅白,硬挺,清脆,模糊,平坦,硬滑,0.245,0.057,否
12,浅白,蜷缩,浊响,模糊,平坦,软粘,0.343,0.099,否
13,青绿,稍蜷,浊响,稍糊,凹陷,硬滑,0.639,0.161,否
14,浅白,稍蜷,沉闷,稍糊,凹陷,硬滑,0.657,0.198,否
15,乌黑,稍蜷,浊响,清晰,稍凹,软粘,0.36,0.37,否
16,浅白,蜷缩,浊响,模糊,平坦,硬滑,0.593,0.042,否
17,青绿,蜷缩,沉闷,稍糊,稍凹,硬滑,0.719,0.103,否

- 在这里使用pandas库来读取数据集,将第一个数据作为测试集,其他数据作为样本集。
df = pd.read_csv('watermelon_4_3.csv')
data = df.values[:, 1:-1]
test = df.values[0,1:-1]
labels = df.values[:,-1].tolist()
2.2 具体实现
2.2.1 计算先验概率P©
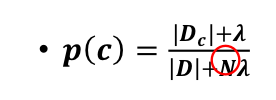
prob_good = log((8 + 1) / float(17 + 2))
prob_bad = log((9 + 1) / float(17 + 2))
2.2.2 计算条件概率P(Xi | c)
这里计算每一个特征对应的条件概率,面对离散和连续的特征分别给出两种方法
- 离散
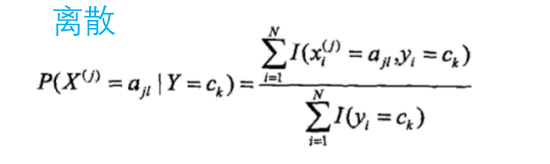
离散步骤的实现代码:
count_good = 0
count_bad = 0
for column in range(len(data)):
if test[i] == data[column,i]:
if labels[column] == 1:
count_good += 1
if labels[column] == 0:
count_bad += 1
prob_good += log(float(count_good + 1) / (8 + class_number(i)))
prob_bad += log(float(count_bad + 1) / (9 + class_number(i)))
- 连续

在这里我们假定满足正态分布P(Xi | c) ~ N(μ,σ^2),上面表达式对应中的μ,σ, 就是第c类样本在第i个属性上面的均值和方差
def continue_para(num, index):
ave = 0.0
var = 0.0
count = 0
for column in range(len(data)):
if labels[column] == num:
count += 1
ave += data[column,index]
ave = ave / count # 求均值
for column in range(len(data)):
if labels[column] == num:
var += (data[column,index] - ave) * (data[column,index] - ave)
var = var / count # 求方差
return ave,var
prob_good = log((8 + 1) / float(17 + 2))
prob_bad = log((9 + 1) / float(17 + 2))
for i in range(len(data[0])):
if type(test[i]).__name__ == 'float': # 当特征是连续的时候
ave0, var0 = continue_para(0, i)
ave1, var1 = continue_para(1, i)
# 带入到连续的公式中
prob0 = exp(- pow(test[i] - ave0, 2) / (2 * var0)) / sqrt(2 * pi * var0)
prob1 = exp(- pow(test[i] - ave1, 2) / (2 * var1)) / sqrt(2 * pi * var1)
prob_good += log(prob1)
prob_bad += log(prob0)
2.2.3 输出结果
比价不同的分类对应的概率大小,最大的就是估计的输出结果
代码实现:
print('probability of good watermelon : %f' % prob_good)
print('probability of bad watermelon : %f' % prob_bad)
if prob_good >= prob_bad:
print('final result: good watermelon')
else:
print('final result: bad watermelon')
3. 代码呈现
# 使用拉普拉斯修正的朴素贝叶斯分类器,这种情况是对第一行的数据进行测试
import numpy as np
import pandas as pd
from math import log, exp, pow, sqrt, pi
# exp(x):e的x次方;pow(x,y):x的y次方
df = pd.read_csv('watermelon_4_3.csv')
data = df.values[:, 1:-1]
test = df.values[0,1:-1]
labels = df.values[:,-1].tolist()
def class_number(index):
class_number = {}
for column in data:
if column[index] not in class_number.keys():
class_number[column[index]] = 0
class_number[column[index]] += 1
num = len(class_number)
return num
def continue_para(num, index):
ave = 0.0
var = 0.0
count = 0
for column in range(len(data)):
if labels[column] == num:
count += 1
ave += data[column,index]
ave = ave / count # 求均值
for column in range(len(data)):
if labels[column] == num:
var += (data[column,index] - ave) * (data[column,index] - ave)
var = var / count # 求方差
return ave,var
prob_good = log((8 + 1) / float(17 + 2))
prob_bad = log((9 + 1) / float(17 + 2))
for i in range(len(data[0])):
if type(test[i]).__name__ == 'float': # 当特征是连续的时候
ave0, var0 = continue_para(0, i)
ave1, var1 = continue_para(1, i)
# 带入到连续的公式中
prob0 = exp(- pow(test[i] - ave0, 2) / (2 * var0)) / sqrt(2 * pi * var0)
prob1 = exp(- pow(test[i] - ave1, 2) / (2 * var1)) / sqrt(2 * pi * var1)
prob_good += log(prob1)
prob_bad += log(prob0)
else:
count_good = 0
count_bad = 0
for column in range(len(data)):
if test[i] == data[column,i]:
if labels[column] == 1:
count_good += 1
if labels[column] == 0:
count_bad += 1
prob_good += log(float(count_good + 1) / (8 + class_number(i)))
prob_bad += log(float(count_bad + 1) / (9 + class_number(i)))
print('probability of good watermelon : %f' % prob_good)
print('probability of bad watermelon : %f' % prob_bad)
if prob_good >= prob_bad:
print('final result: good watermelon')
else:
print('final result: bad watermelon')
结果展示:

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









