









学习内容
前情提要
BERT与芝麻街
这些都是BERT的组件
BERT与进击的巨人
BERT(340 M 参数)
ELMO(94M)
GPT-2(1542M)
Megatron(8B)
T5(11B)
Turing NLG(17 billion)
GPT-3(170 billion)
Bert的基本知识
前提
监督学习: 有标签
自监督学习:由于没有标签,我们需要将文章的某一部分作为特征,另一部分作为标签,使得特征经过模型后和标签距离更近;
无监督学习: 就是没有标签喽!
Masking Input
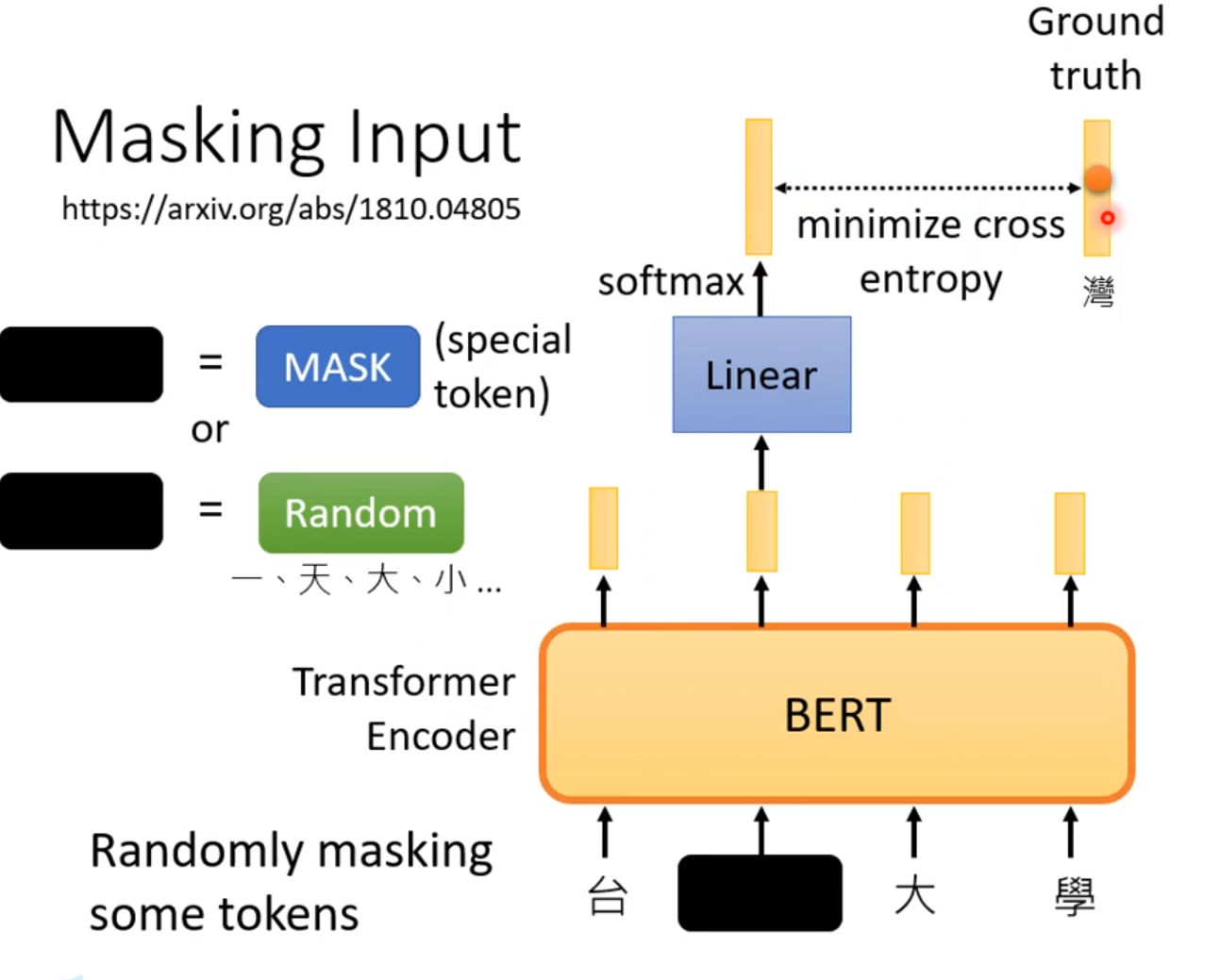
BERT就是输入一些字符,输出一些字符;
Mask Input有两种:第一种是盖住; 第二种是替换;
但是在输出结果后还是要和GT标签计算距离!
Next sentence Prediction (观察两个数据是相连还是不相连)
方法:
输入两个句子,输出vector
sep: 两个句子的分隔符;
CLS: 输出这两个句子是不是相连接的,连接 = True; 不连接=Flase;
评价:
没有用,这个Next sentence Prediction是没用的
其它:
SOP: sentence order prediction
Used in ALBERT
那Bert有什么用? 填空题?
其它应用?
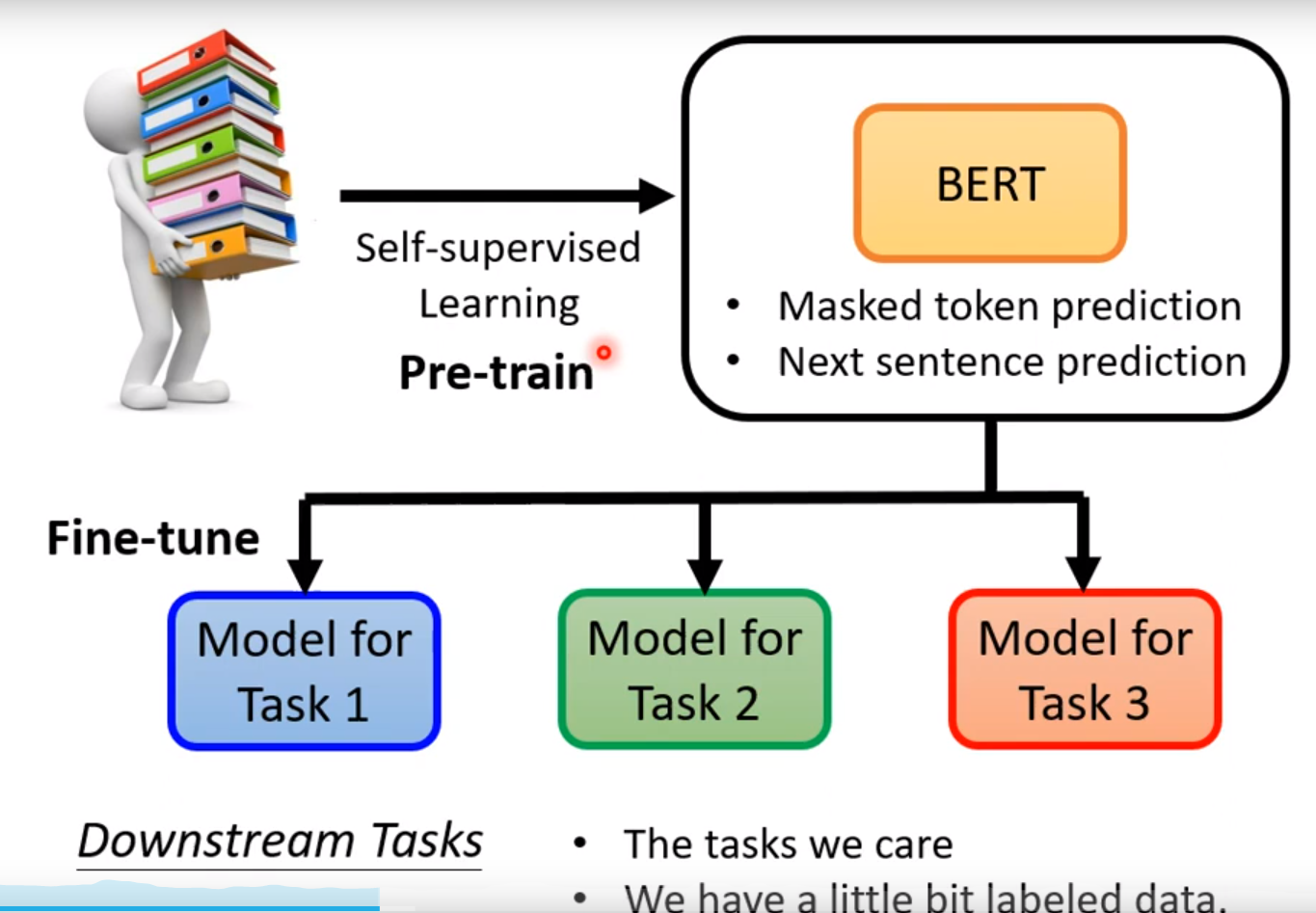
下游任务! 我们需要Bert进行pre-train,类似胚胎干细胞,fine-tune成不同的Model
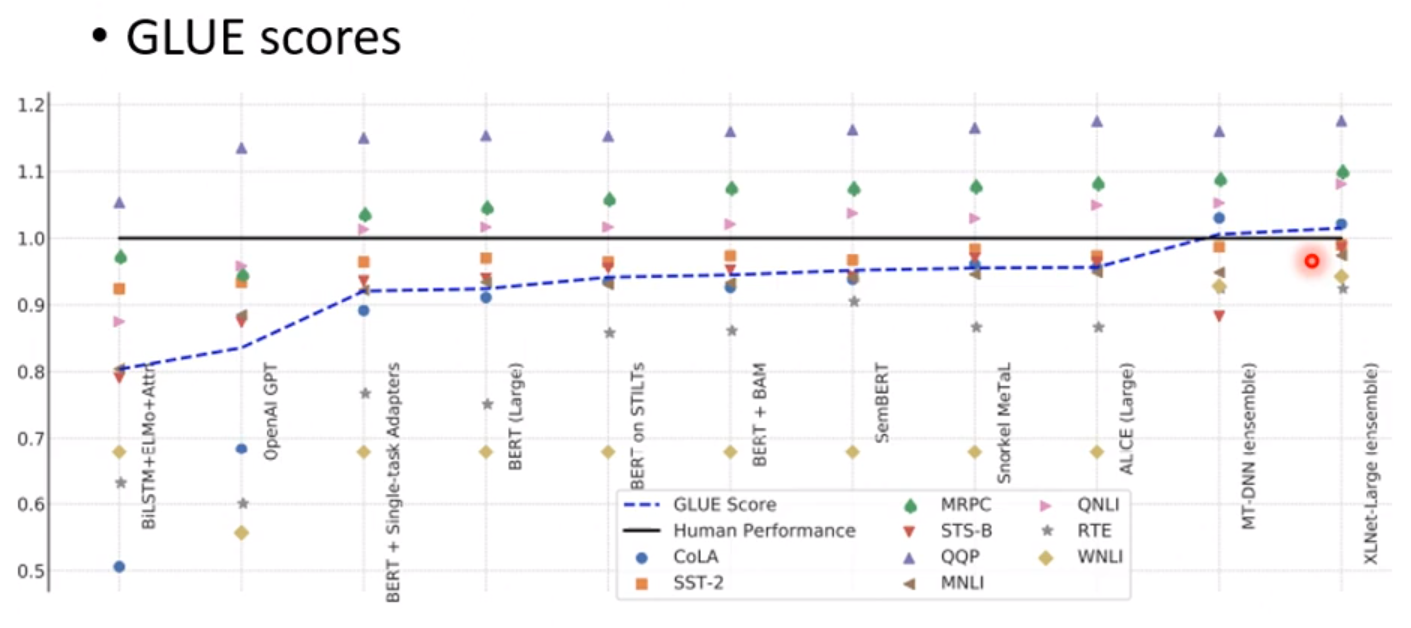
GLUE
判断一个模型好与不好,需要在公开模型中判断,GLUE就是一个标杆;
GLUE中包含了各种数据集,从而测试不同模型的不同的性能。下图中是各个子任务达到的SOTA和人类能力的比对。
实例
Case 1: 情感分析
图片1
线性层是需要随机初始化的! 而BERT是预训练的模型(会做填空题的BERT), CLS输出该句子的情感。
随机初始化的效果要差!
Case 2:POS(词性标注) 输入一个句子输出一样长度的句子
图片2
这里的CLS就没啥用了,因为我们输出的是三个
Case3: NLI(自然语言逻辑判断)
查看两句话的逻辑是否相通,能否通过前提推出假设! 是不是矛盾的!
图片3
用在哪? 比如论文和某个人的评论,到底是合理的还是不合理的!
输入两个句子,输出CLS
Case4: QA(问答系统)
让机器读后,你提出问题,让他给你一个答案!
题目: 图片1
怎么使用BERT: 图片2
你唯一需要训练的向量就是两个随机初始化的向量,这两个向量的大小和BERT的产出向量是同样大小到 !怎么使用这两个向量呢? 我们先用橙色的向量与右边的文件向量做Inner Product,查看和document哪个单词的内积更高,那么s 就等于几; 蓝色的同理,代表了答案结束的向量,d就等于几。答案= s - d
问题1: 输入长度有限制吗?
答: 长度不是无限长的
问题2: 和填空题的区别
答:
训练Bert 是很困难的
需要3billions单词, 3000倍哈利波特。
Google的ALBERT;
Bert Embryology 胚胎学
Bert增强= MASS/BART
将Encoder的输入弄坏!也就是添加Mask,旋转等 ; 而Decoder需要还原Encoder弄坏的单词;
T5-Comparison
有这么多弄坏的方法,哪些更好呢? 谷歌T5已经做了! 它是在C4(公开资料集 7T )上计算的。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









