









评价指标
Recall
-
名称: 召回率(真阳性率)
-
意义:在推荐系统中,我们只关心正确推荐的有多少,也就是用户真实喜欢的,并不会关心推荐错的,所以我们用召回率,而不是准确率;
-
理解这个前提:混淆矩阵
混淆矩阵: 详细的可以自己去了解
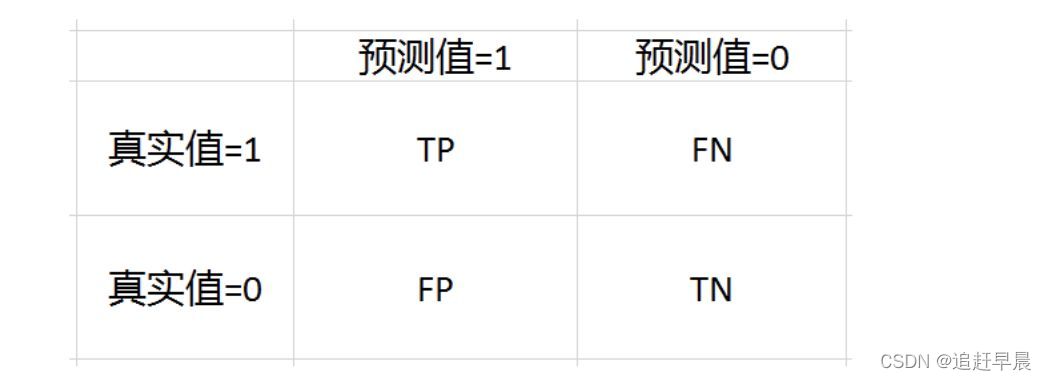
Recall = TP / (TP + FN)
也就是你所有预测为True的里面,到底有多少是真实值! -
Recall@n指的是推荐的前n个的召回率有多少
代码实现比较简单
ROC(AUC)
- 名称: Curve曲线, AUC是ROC下面的面积
- 意义:ROC的效果是看AUC的面积大小决定的; 如果AUC等于1,那么就是预测全部正确
- 要明白这个,必须知道混淆矩阵。
ROC的横坐标是FP,纵坐标是TP,一般而言,TP要大于FP,所以曲线是一个凸函数,而且AUC>0.5
AUC的面积越大,说明效果更好
def confusion_marix(predict_label, true_label):
true_lable = true_label
TP, TN, FP, FN = 0,0,0,0
for predict, true in zip(predict_label, true_lable):
if predict == true == 1:
TP += 1
elif predict == true == 0:
TN += 1 # 怎么写? 先写后面的 N和P,再写前面预测正确还是错误
elif predict == 1 and true == 0: # 预测为1,但是真实的是0,所以是错误的P
FP += 1
else: # predict == 0 and true == 1: # 预测为0,但是真实的是1,所以是错误的N
FN += 1
ACC = (TP + TN) / (len(true_lable))
TPR = TP / (TP + FN) # 召回率
PPV = FP / (TP + FP) # 精准率
F1 = 2 / (1 / TPR + 1 / PPV)
return ACC, TPR, PPV, F1
NGCG(Normalized Discounted Cummulative Gain)
-
名称:归一化折损累计增益
-
意义:在搜索和推荐任务中,系统常返回一个item列表。如何衡量这个返回的列表是否优秀呢?可以用于评价基于打分/评分的个性推荐系统。
-
要理解这个,得从点点了解开始; 相关性是人工打标签上去的,不要问为什么
NDCG
G-CG-DCG-NDCG -
G = Gain: 表示列表中每一个item的相关性分数
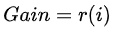
-
CG = Cumulative Gain:表示对K个item的相关性进行累加
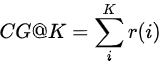
-
DCG = Discounted Cumulative Gain:考虑排序顺序的因素,使得排名靠前的item增益更高,对排名靠后的item进行log折损。
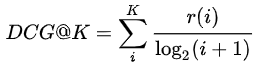
如果相关性分数r(i)只有(0,1)两种取值时,DCG@K有另一种表达。其实就是如果算法返回的排序列表中的item出现在真实交互列表中时,分子加1,否则跳过。
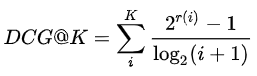
-
NDCG = Normalized Discounted Cumulative Gain:
DCG能够对一个用户的推荐列表进行评价,如果用该指标评价某个推荐算法,需要对所有用户的推荐列表进行评价,由于用户真实列表长度不同,不同用户之间的DCG相比没有意义。
所以要对不同用户的指标进行归一化,自然的想法就是计算每个用户真实列表(指的是groudtruth)的DCG分数,用IDCG表示,然后用每个用户的DCG与IDCG之比作为每个用户归一化后的分值,最后对每个用户取平均得到最终的分值,即NDCG。
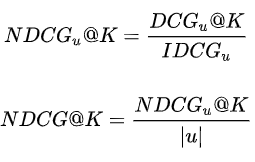
#coding=utf-8
import numpy as np
# 复现求和运算的公式
# 有求和运算的,K一般是传入的list的长度
# 单元素:一般是先处理求和符号右边的;
# 多元素:生成列表;
# 然后最后再聚合(np.sum)
# 1. 得到一个用户的DCG评分
# 这种是相关性分数是连续的
def getDCG_list(scores):
return np.sum([np.divide(score, np.log2(1+i)) for i, score in enumerate(scores)])
# 这种相关性分数是0和1
def getDCG2_list(scores):
return np.sum([np.divide(2 ** score - 1, np.log2(1+i)) for i, score in enumerate(scores, start=1)])
# 但是,其实np里面所有的加减乘除都是传播的,单个元素之间分别操作! 所以不用遍历
def getDCG(relavance):
return np.divide(relavance, np.log2(1 + np.arange(1, len(relavance) + 1)))
def getDCG2(scores): # 如果相关性只有0和1用这个
return np.divide(2 ** scores - 1, np.log2(1 + np.arange(1, scores.shape[0] + 1)))
# 2. DCG / IDCG 所有真实列表的全部
def getNDCG(predict_list, true_list, true_relavance, true_rel_dict):
# 结果为1的原因是因为代码里相关性得分的定义是只要出现在真实列表中就为1,推荐问题里这么设置是比较常见的
preict_relavance = np.asarray([true_rel_dict.get(it, 1.0) for it in predict_list], dtype=np.float32) # 获得precit的分数
idcg = getDCG(true_relavance)
dcg = getDCG(preict_relavance)
# if dcg == 0.0:
# return 0.0
ndcg = dcg / idcg
return ndcg
predict_list = [3, 2, 1] # 预测结果
true_list = [1, 2, 3] # 真实的结果
true_relavance = [i for i in range(3, 0, -1)]
true_rel_dict = {it: r for it, r in zip(true_list, true_relavance)} # 定义相关性字典,方便predict_item查找相应的分数
a = getNDCG(predict_list, true_list, true_relavance, true_rel_dict)
print(a)
Hit(Hit Ratio)
- 名称:击中率
- 意义:在top-K推荐中,HR是一种常用的衡量召回率的指标,而且只是在测试为用户推荐的items是不是在用户的真实集合中,并不在乎先后顺序!
- 计算公式为:
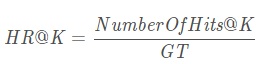
# coding=utf-8
# HR@K: 表示模型推荐的top-K中有几个被推荐了
# 可以发现是永远小于1的,而且应该是增长的! 不用质疑错没错,就是这么定义的
def hit(pred_items, gt_items): # 这里指的是一个用户的预测! 不在乎排序! 只要推荐了就行
hititems = [pred_item for pred_item in pred_items if pred_item in gt_items]
hr = len(hititems) / len(gt_items)
return hr, hititems
# 加入hit@5
pred_items = [3, 4, 2, 100, 1000]
gt_items = [1, 2, 3, 4, 5, 6, 7, 8]
hr, hititems = hit(pred_items, gt_items)
print(hr)
MAP(Mean Average Precision)
- 所有用户的平均命中率AP = MAP
- 意义: 仅仅是准确率(召回率或者是HR)是不行的,还得看你的推荐顺序,比如搜索引擎里的推荐TOPK,是不是把命中的的排序到前面,而未命中的排序到了后面(这里只有命中和非命中的顺序之分,而没有区分具体的每个item的顺序);
比如:【命中,命中,未命中,未命中,未命中】和【未命中,未命中,未命中,命中,命中】显然它们的准确率都是2/5,但是第一个更好。
注意: 预测的items只要在gt中有,那么就是命中了,我们关系的是命中的顺序,而不是精确的,物品2在gt中是第一个,那么预测的物品2也必须是第一个。
- 先看AP,一个用户的
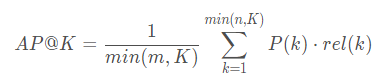
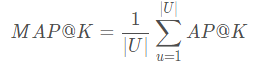
K
K
K表示推荐列表的长度;
U
U
U表示的用户数量;
m
m
m用户实际选择的物品数;
n
n
n是给用户推荐的项目数;
P
(
k
)
P(k)
P(k)指的是截止到第k个,有多少项目命中
如预测的第一个排名命中了,截止到第一个,命中率是1/1;
第二个排名没有命中,那么就是0;
第三个排名命中了,截止到第三个,有两个命中,命中率就是2/3
r
e
l
(
k
)
rel(k)
rel(k)指的是排名第k的项目是不是被用户实际选择;是为1,不是为0
所以对于推荐列表【命中,命中,未命中,未命中,未命中】,假设该用户在测试集中实际选择了3个项目,则

def AP(pred_items, gt_items):
cu_hits = 0 # 累计命中
cu_precision = 0 # 累加命中率
for i, pred_item in enumerate(pred_items, start=1):
if pred_item in gt_items:
cu_hits += 1
cu_precision += cu_hits / i # 每步一算
if cu_hits > 0:
return cu_precision / len(gt_items)
else:
return 0
pred_items = [3, 4, 2, 100, 1000]
gt_items = [1, 2, 3, 4, 5, 6, 7, 8]
AP = AP(pred_items, gt_items)
print(AP)
MRR(Mean Reciprocal Rank)
- 名称:平均倒数排序
- 意义: 要查询的结果值在返回的结果中的排名。)是一个国际上通用的对搜索算法进行评价的机制。(仅仅是排名)
可以用在序列推荐中
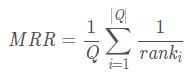
- 正确检索结果值在检索结果中的排名来评估检索系统的性能
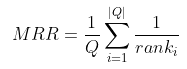
假如检索三次的结果如下,需要的结果(cat,torus,virus)分别排在3,2,1的话,排在results的第三个结果就是1/3,排在第二个则是1/2
(注意分母不是所有的结果的个数,而是排名)

def MRR(pred_items, gt_items):
rank = 0
for pred_item in pred_items:
if pred_item in pred_items:
rank = gt_items.index(pred_item) + 1
rank += 1/rank
return rank
pred_items = [3, 4, 2, 100, 1000]
gt_items = [1, 2, 3, 4, 5, 6, 7, 8]
MRR = MRR(pred_items, gt_items)
print(MRR)
ILS
- 意义:ILS 衡量推荐列表多样性的指标,计算公式
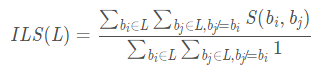
如果, S ( b i , b j ) S(b_i, b_j) S(bi,bj)计算的是 i i i和 j j j两个物品的相似性,如果推荐列表中的物品越不相似,ILS越小,那么推荐结果的多样性越好。
coverage
推荐系统能够推荐出来的物品占总物品集合的比例。
热门排行榜的推荐覆盖率是很低的! 因为热门物品占总体物品是很低的一部分


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









