







一、工作表计数
二、从多个工作表中连接(concat)数据
三、批量计算工作簿和工作表总数和均值
原数据下载
一、工作表计数
计算当前目录下所有的 excel 数量,并显示 sheet row colum 等详细信息
注意 高版本的 xlrd 不支持 .xlsx 格式。会报错 xlrd.biffh.XLRDError: Excel xlsx file; not supported
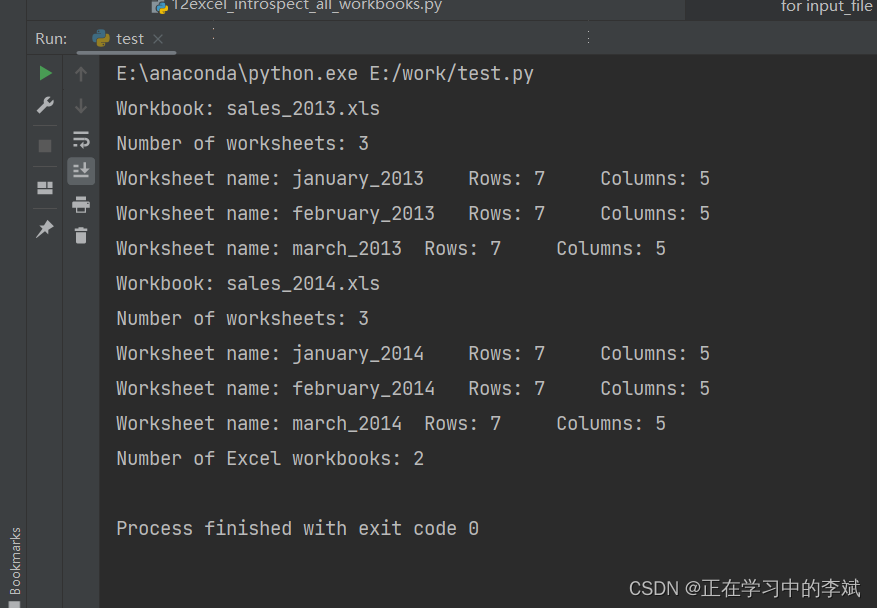
os.path.basename(input_file) 文件名
workbook.nsheets 一个工作簿中 sheet 数量
worksheet.nrows 一个 sheet 中 总行数
worksheet.ncols 一个 sheet 中 总列数
import glob
import os
from xlrd import open_workbook
input_directory = "E:\work\code\excel"
workbook_counter = 0
for input_file in glob.glob(os.path.join(input_directory, '*.xls')):
print(input_file)
workbook = open_workbook(input_file)
print('Workbook: {}'.format(os.path.basename(input_file)))
print('Number of worksheets: {}'.format(workbook.nsheets))
for worksheet in workbook.sheets():
print('Worksheet name:', worksheet.name, '\tRows:',\
worksheet.nrows, '\tColumns:', worksheet.ncols)
workbook_counter += 1
print('Number of Excel workbooks: {}'.format(workbook_counter))
二、合并(concat)多个工作表中的数据
将多个工作簿中的多个 sheet 文件合并,主要用到 append 和 concat。
第一层循环 遍历所有的工作簿 all_workbooks。
第二层循环 遍历每个工作簿中的 all_worksheets
axis=0 表示将数据垂直拼接起来,axis=1 表示将数据平行拼接起来。
merge 如果想要根据某个关键字拼接数据,可以用 merge。
import pandas as pd
import glob
import os
input_path = "E:\work"
output_file = "E:\work\output_file.xlsx"
all_workbooks = glob.glob(os.path.join(input_path,'*.xls*'))
data_frames = []
# 第一层循环
for workbook in all_workbooks:
all_worksheets = pd.read_excel(workbook, sheet_name=None, index_col=None)
# 第二次循环
for worksheet_name, data in all_worksheets.items():
data_frames.append(data)
all_data_concatenated = pd.concat(data_frames, axis=0, ignore_index=True)
writer = pd.ExcelWriter(output_file)
all_data_concatenated.to_excel(writer, sheet_name='all_data_all_workbooks', index=False)
writer.save()
三、批量计算工作簿和工作表总数和均值
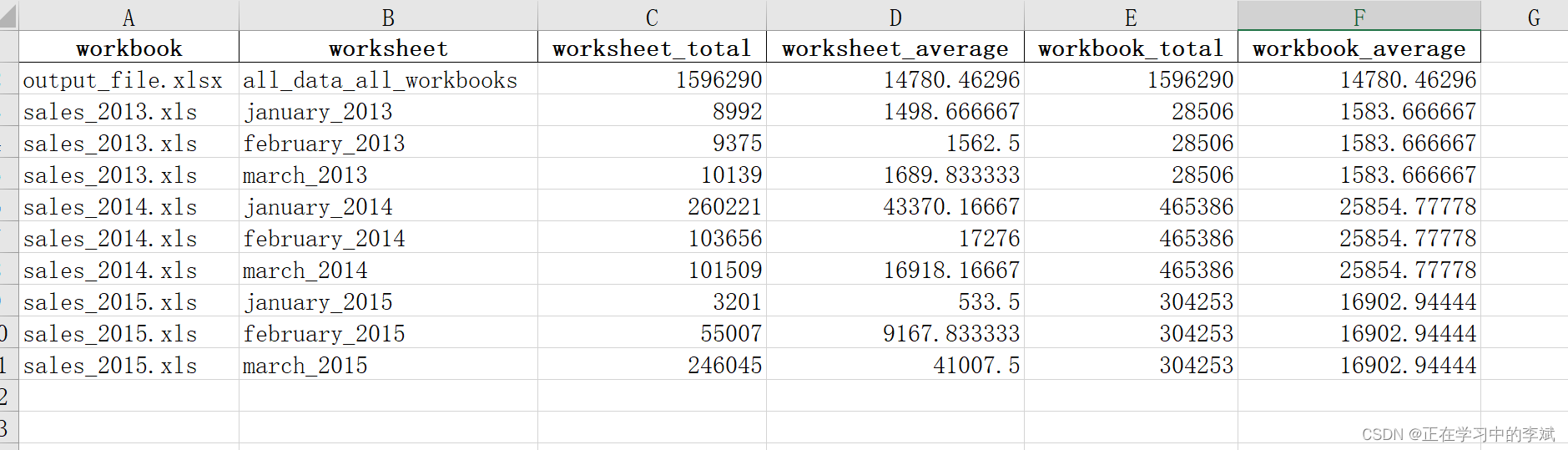
每个 workbook 工作簿 的总数,平均值。
每个 worksheet 表 的总数,平均值。
pd.Series(total_sales / number_of_sales) 总销售额 除以 总数量 的时候,格式会发送变化,需要用 pd.Series 转换
#!/usr/bin/env python3
import pandas as pd
import glob
import os
input_path = "E:\work"
output_file = "E:\work\output_file.xlsx"
all_workbooks = glob.glob(os.path.join(input_path, '*.xls*'))
data_frames = []
# 第一层遍历,获取到虽有的工作簿 workbook
for workbook in all_workbooks:
all_worksheets = pd.read_excel(workbook, sheet_name=None, index_col=None)
# 需要统计的数据项
workbook_total_sales = []
workbook_number_of_sales = []
worksheet_data_frames = []
worksheets_data_frame = None
workbook_data_frame = None
# 遍历一个工作簿中的所有 worksheet
for worksheet_name, sheet_data in all_worksheets.items():
# 获取销售总额, 保活替换空格 美元符号等
total_sales = pd.DataFrame([float(str(value).strip('$').replace(',', '')) for value in sheet_data.loc[:, 'Sale Amount']]).sum()
# 用 len() 函数 求出数量
number_of_sales = len(sheet_data.loc[:, 'Sale Amount'])
# 计算出 一个 worksheet 的平均值,这里需要用 Series 转换数据格式
average_sales = pd.Series(total_sales / number_of_sales)
# 将每个 worksheet 的销售总额 和销售量 记录,然后在 内层 for 循环结束后 求和,就得到单个 workbook 的总和
workbook_total_sales.append(total_sales)
workbook_number_of_sales.append(number_of_sales)
data = {'workbook': os.path.basename(workbook),
'worksheet': worksheet_name,
'worksheet_total': total_sales,
'worksheet_average': average_sales}
worksheet_data_frames.append(
pd.DataFrame(data, columns=['workbook', 'worksheet', 'worksheet_total', 'worksheet_average']))
worksheets_data_frame = pd.concat(worksheet_data_frames, axis=0, ignore_index=True)
# 求和,就得到单个 workbook 的总和
workbook_total = pd.DataFrame(workbook_total_sales).sum()
workbook_total_number_of_sales = pd.DataFrame(workbook_number_of_sales).sum()
# 除以 workbook 的总数 得一个工作簿的平均值
workbook_average = pd.Series(workbook_total / workbook_total_number_of_sales)
workbook_stats = {'workbook': os.path.basename(workbook),
'workbook_total': workbook_total,
'workbook_average': workbook_average}
workbook_stats = pd.DataFrame(workbook_stats, columns=['workbook', 'workbook_total', 'workbook_average'])
# 左连接 'workbook' 相当于连接key
workbook_data_frame = pd.merge(worksheets_data_frame, workbook_stats, on='workbook', how='left')
data_frames.append(workbook_data_frame)
all_data_concatenated = pd.concat(data_frames, axis=0, ignore_index=True)
writer = pd.ExcelWriter(output_file)
all_data_concatenated.to_excel(writer, sheet_name='sums_and_averages', index=False)
writer.save()















 3398
3398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









