









1.准备
默认安装jdk1.8
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64
服务器分配,2台机器:
192.168.14.44 node01 -- Master Worker
192.168.14.46 node02 -- Worker2.Spark下载
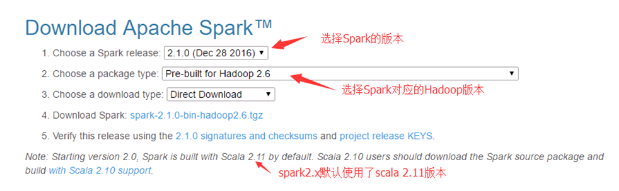
需要下载和Hadoop对应的版本,版本一定要选择好
默认是使用scala2.11版本
3.安装
(1)解压到指定目录
tar -zxvf spark-2.4.5-bin-hadoop2.6.tgz -C /dbdata/
目录重命名
cd /dbdata/
mv spark-2.4.5-bin-hadoop2.6 spark
(2)修改配置文件
以下两个文件拷贝一份并重命名
cd /dbdata/spark/conf
cp slaves.template slaves
cp spark-env.sh.template spark-env.sh
-
配置spark-env.sh
vi spark-env.sh
# jdk安装目录
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64
# master运行host
export SPARK_MASTER_IP=192.168.14.44
# master运行端口
export SPARK_MASTER_PORT=7077-
配置slaves
添加集群
vi slaves
192.168.14.44
192.168.14.46
(3)拷贝目录到其他服务器
cd /dbdata/
scp -r spark 192.168.14.46:$PWD
4.启动
/dbdata/spark/sbin/start-all.sh
这边会发现start-all.sh命令和hadoop的是重名了
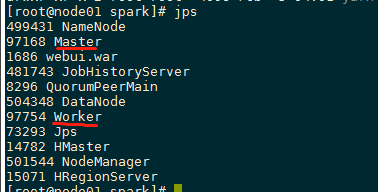
查看是否启动成功:jps
看到有Master和Worker就说明安装成功
5.启动Spark shell
spark-shell是Spark自带的交互式Shell程序,方便用户进行交互式编程,用户可以在该命令行下用scala编写spark程序。
spark-shell --master spark://node01:7077 --executor-memory 2g --total-executor-cores 2
参数说明:
#指定Master的地址
--master spark://node01:7077
# 指定每个worker可用内存为2G
--executor-memory 2g
# 指定整个集群使用的cup核数为2个
--total-executor-cores 2
启动之后进入如下界面:
















 1092
1092











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









