







一、框架目录结构
- 1)tools目录用来放公共方法存储,如发送接口以及读取测试数据的方法,响应断言 数据库断言 前置sql等方法;
- 2)datas目录用例存储接口用例的测试数据,我是用excel来存储的数据,文件数据 图片数据等;
- 3)testcases目录用来存放测试用例,一个python文件对应一个接口模块的测试用例,不同接口分别别多个不同的python文件;
- 4)outputs里有reports和logs,report目录用来存放测试报告,报告是HTML格式的;logs是存放框架日志的;
- 5)run.py是用来执行所有接口用例的入口文件;
二、框架结构代码图解
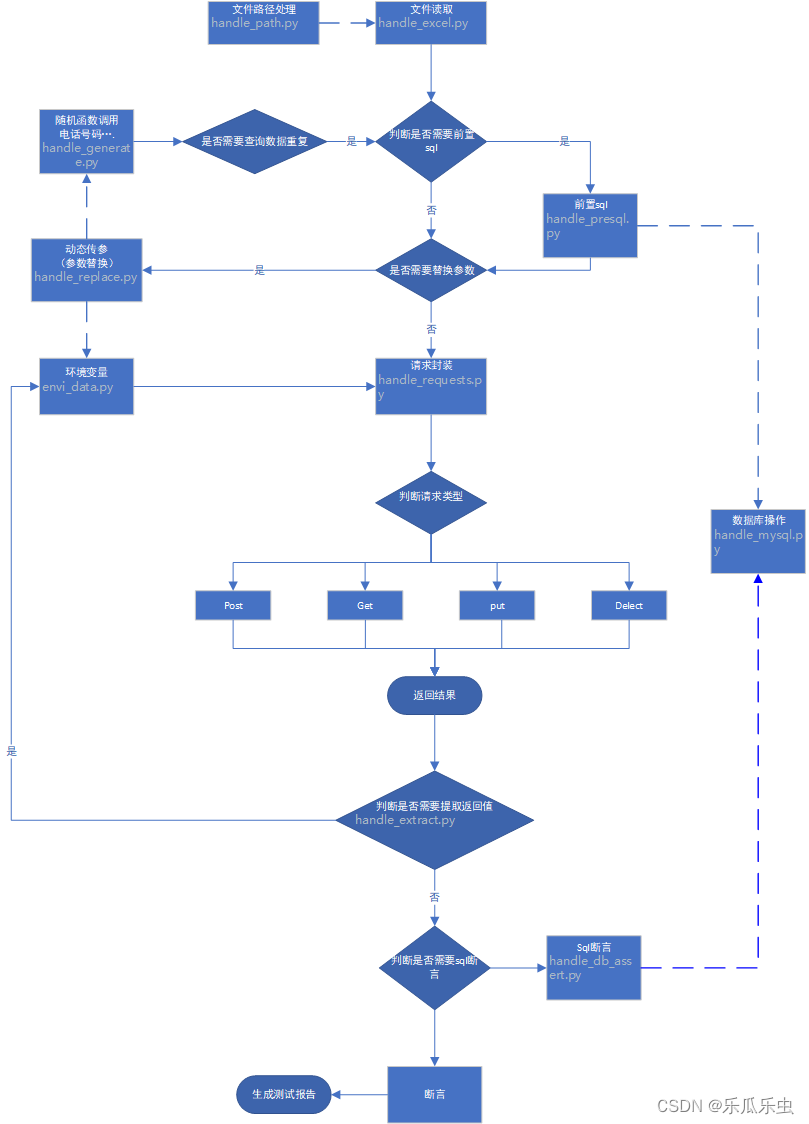
三、各文件内容详解
tools扩展封装类详解
handle_path.py :文件路径处理
from pathlib import Path
log_path = Path(__file__).absolute().parent.parent/"outputs"/"logs"/"mytest.log"
# excel表格的路径处理
exc_path = Path(__file__).absolute().parent.parent /"datas" / "testcase_mall.xlsx"
# 上传文件 路径
pic_path = Path(__file__).absolute().parent.parent /"datas"
handle_excel.py:读取excel文件内容
主要运用openpyxl函数中load_workbook方法读取文件内容
from pathlib import Path
from openpyxl import load_workbook
def read_data(exc_path,sheetname):
"""
这是读取excel表格函数
:param exc_path: 用例文件的路径
:param sheetname: 用例表单的名字
:return:
"""
wb = load_workbook(exc_path)
sh = wb[sheetname]
cases = list(sh.values) # 所有的用例的列表 [(第一行-title),(第二行用例),(),()]
title = cases[0] # 得到标题行
list_case = []
for case in cases[1:]:
data = dict(zip(title,case)) # 第一条用例的字典
list_case.append(data) # 每一条用例追加到列表里。
return list_case
if __name__ == '__main__':
exc_path = Path(__file__).absolute().parent.parent /"datas" / "testcase_mall.xlsx"
print(read_data(exc_path, "登录"))
envi_data.py:存储环境变量
# 这个类就是为了存储环境变量 实现环境变量的共享的
class EnviData:
pass
handle_replace.py
检查excel读取的内容是否需要替换变量,
需要替换变量,先提取需要替换的变量名,
再查通过需要替换的变量名在环境变量中查询对应的值
替换变量的值并返回。
并引用loguru 函数中logger方法导入日志模块返回替换字段的日志
"""
1、def封装
2、参数化
3、返回值: 最终要拿到替换后的字符串 --- 头部 参数 要用于发送接口测试的
4、加上日志: 但凡你想确认数据结果的地方 都可以加上日志
5、因为有些接口不需要做数据提取,所以判空处理:
6、异常捕获: 因为有可能环境变量里没有这个属性名 和属性值
"""
import re
import allure
from loguru import logger
from tools.envi_data import EnviData
from tools.handle_generate import GenData
@allure.step("替换占位符变量")
def replace_mark(str_data):
while True:
if str_data is None:
return
result = re.search("#(.*?)#",str_data)
if result is None: # 如果没有占位符 就是None 跳出循环
break
mark = result.group() # 结果是 #prodId# --要被替换的子字符串| #gen_unregister_phone()#
logger.info(f"要被替换的子字符串:{
mark}")
if "()" in mark:
fun_name = result.group(1) # 第一个分组的值 结果是 gen_unregister_phone()
logger.info(f"要提取环境变量的函数名:{
fun_name}")
# 通过eval拖引号之后,不可以直接GenData().gen_unregister_name(),要导包
gen_data = eval(f'GenData().{
fun_name}') # 接口函数的返回值结果-生成的数据
logger.info(f"生成的随机的数据是:{
gen_data}")
# 1、存数据到环境变量里 -- 类属性的名字 函数名去掉()
var_name = fun_name.strip("()") # 结果是 gen_unregister_phone
setattr(EnviData,var_name,gen_data) # 属性名:gen_unregister_phone 属性值: gen_data
logger.info(f"环境变量的属性值:{
EnviData.__dict__}")
# 2、完成第一条的参数的替换 用刚刚生成的数据替换
str_data = str_data.replace(mark,str(gen_data))
logger.info(f"替换完成后的字符串是:{
str_data}")
else:
var_name = result.group(1) # 第一个分组的值 结果是 prodId
logger.info(f"要提取环境变量的属性名:{
var_name}")
try:
var_value = getattr(EnviData,var_name) # 结果 : 7717--int类型
except AttributeError as e:
logger.error(f"环境变量里不存在这个属性:{
var_name}")
raise e
logger.info(f"要提取环境变量的属性值:{
var_value}")
str_data = str_data.replac 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1724
1724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









