







 PCA(主成分分析)是一种常用的数据降维方法,通过线性变换将高维数据转换为低维空间,保留主要信息。在本文中,我们将探讨PCA图的绘制过程,数据准备包括从定量表中获取数据,以及如何使用R语言的ggplot2和ggbiplot库进行可视化。PCA图有助于区分样本组,聚集的样本表示差异性小,而远离的样本则表示差异性大。此外,介绍了在线平台BioLadder生信云用于便捷绘制PCA图。
PCA(主成分分析)是一种常用的数据降维方法,通过线性变换将高维数据转换为低维空间,保留主要信息。在本文中,我们将探讨PCA图的绘制过程,数据准备包括从定量表中获取数据,以及如何使用R语言的ggplot2和ggbiplot库进行可视化。PCA图有助于区分样本组,聚集的样本表示差异性小,而远离的样本则表示差异性大。此外,介绍了在线平台BioLadder生信云用于便捷绘制PCA图。
1.什么是PCA?
人眼一般能感知的空间为二维和三维。高维数据可视化的重要目标就是将高维数据呈现于二维或三维空间中。高维数据变换就是使用降维度的方法,使用线性或非线性变换把高维数据投影到低维空间,去掉冗余属性,但同时尽可能地保留高维空间的重要信息和特征。
主成分分析法,也被称为主分量分析法,是很常用的一种数据降维方法。主成分分析法采用一个线性变换将数据变换到一个新的坐标系统,使得任何数据点投影到第一个坐标(第一主成分)的方差最大,在第二个坐标(第二主成分)的方差为第二大,以此类推。因此,主成分分析可以减少数据的维数,并保留对方差贡献最大的特征。
本文我们就来讨论一下PCA图是如何绘制的以及如何对其进行解读。
2.绘图前的数据准备
demo数据可以在https://www.bioladder.cn/shiny/zyp/bioladder2/demoData/PCA/PCA.rar下载。
2.1 PCA数据
数据来源一般是搜库结果定量表。包含2个维度的数据,一般情况下,每一行是一个基因,每一列是一个样本。
| Control_1 | Control_2 | Control_3 | a_1 | a_2 | a_3 | b_1 | b_2 | b_3 | |
|---|---|---|---|---|---|---|---|---|---|
| P1 | 5.444152745 | 6.566785573 | 6.812233434 | 3.811535337 | 5.131083481 | 5.125230542 | 4.408900524 | 4.629775369 | 5.214981331 |
| P2 | 0.134216388 | 0.142388691 | 0.351898471 | 0.321926003 | 0.42922913 | 0.343332719 | 0.376903515 | 0.462213028 | 0.342565149 |
| P3 | 1.609307876 | 1.422010834 | 2.25798398 | 1.572262019 | 2.232753108 | 1.534304685 | 2.104263276 | 2.254176691 | 2.254898187 |
| P4 | 0.429061257 | 0.377513542 | 0.530739623 | 0.862860941 | 0.87512611 | 0.962928809 | 0.738676141 | 0.61435028 | 0.636783556 |
| P5 | 0.039323787 | 0.614189457 | 0.058814106 | 0.054956059 | 2.049875666 | 1.304961269 | 0.454248317 | 6.189823039 | 4.288463759 |
| P6 | 0.983452665 | 0.438816224 | 0.351440757 | 0.273694705 | 0.458174067 | 0.396366654 | 0.303059088 | 1.0059137 | 0.739135456 |
| P7 | 0.167541766 | 0.650786101 | 0.42608967 | 0.619695739 | 0.371239787 | 0.463518997 | 0.299902767 | 0.212751557 | 0.082936218 |
| P8 | 0.573221957 | 0.307041881 | 0.29383127 | 0.337560003 | 0.34921492 | 0.432229805 | 0.401436051 | 0.411867875 | 0.385195735 |
| P9 | 0.171089897 | 0.127747391 | 0.509622386 | 0.083465032 | 0.109354174 | 0.081346367 | 0.354884069 | 0.203768579 | 0.464355826 |
| P10 | 51.65234686 | 79.41075439 | 47.19026319 | 34.88368658 | 84.0383659 | 42.72408705 | 66.9012715 | 67.39819666 | 62.25990223 |
2.2 分组数据(可选)
行名的名称和个数要和之前的PCA数据保持一致,列名为分组名称,可以包含不止一个分组。
| Sample | Group |
|---|---|
| Control_1 | Control |
| Control_2 | Control |
| Control_3 | Control |
| a_1 | a |
| a_2 | a |
| a_3 | a |
| b_1 | b |
| b_2 | b |
| b_3 | b |
3. R语言怎么画PCA
# 加载R包,没有安装请先安装 install.packages("包名")
library(ggplot2)
library(ggbiplot)
# 读取PCA数据文件
df = read.delim("https://www.bioladder.cn/shiny/zyp/bioladder2/demoData/PCA/data.txt",# 这里读取了网络上的demo数据,将此处换成你自己电脑里的文件
header = T, # 指定第一行是列名
row.names = 1 # 指定第一列是行名
)
df=t(df) # 对数据进行转置,如果想对基因分组则不用转置
# 读取样本分组数据文件
dfGroup = read.delim("https://www.bioladder.cn/shiny/zyp/bioladder2/demoData/PCA/sample.class.txt",
header = T,
row.names = 1
)
# PCA计算
pca_result <- prcomp(df,
scale=T # 一个逻辑值,指示在进行分析之前是否应该将变量缩放到具有单位方差
)
# 绘图
ggbiplot(pca_result,
var.axes=F, # 是否为变量画箭头
obs.scale = 1, # 横纵比例
groups = dfGroup[,1], # 添加分组信息,为分组文件的第一列
ellipse = T, # 是否围绕分组画椭圆
circle = F)+
geom_text( # geom_text一个在图中添加标注的函数
aes(label=rownames(df)), # 指定标注的内容为数据框df的行名
vjust=1.5, # 指定标记的位置,vjust=1.5 垂直向下1.5个距离。 负数为位置向上标记,正数为位置向下标记
size=2 # 标记大小
)
# 更多请 ?ggbiplot 获取帮助
4.BioLadder生信云平台在线绘制PCA图
不想写代码?可以用BioLadder生信云平台在线绘制PCA。
5.PCA结果解读
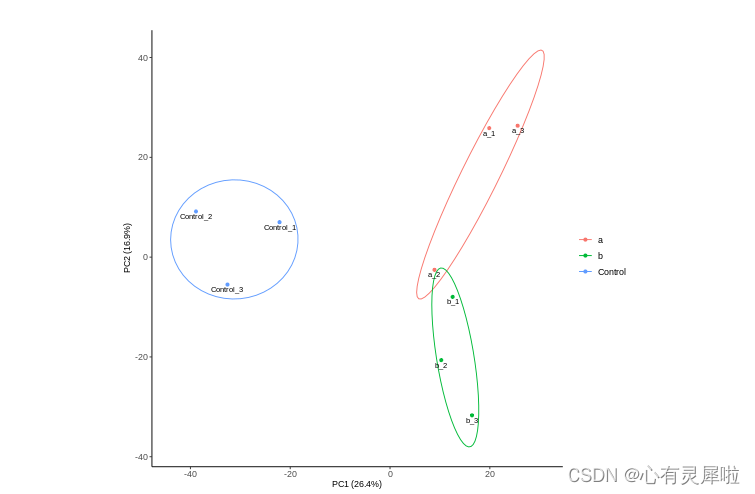
是主成分分析的PC1和PC2的结果,横纵坐标分别为前两个主成分,括号内的百分比为该主成分能解释的变量的百分比。PCA得分图能将对照组和实验组样本区分开。在PCA图中,如果样本之间聚集在一起,说明这些样本差异性小;反之样本之间距离越远,说明样本之间差异性越大。不同颜色的散点表示不同实验分组的样本。

















 299
299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









