






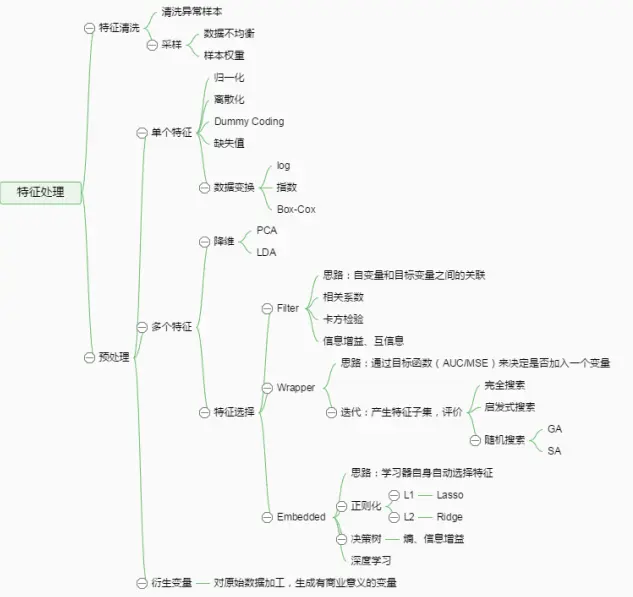
一、清洗异常样本
- 偏差检测:聚类、最近邻等
- 基于统计的异常点检测
例如极差,四分位数间距,均差,标准差等,这种方法适合于挖掘单变量的数值型数据。全距(Range),又称极差,是用来表示统计资料中的变异量数(measures of variation) ,其最大值与最小值之间的差距;四分位距通常是用来构建箱形图,以及对概率分布的简要图表概述。- 基于距离的异常点检测
主要通过距离方法来检测异常点,将数据集中与大多数点之间距离大于某个阈值的点视为异常点,主要使用的距离度量方法有曼哈顿距离、欧氏距离和马氏距离等。- 基于密度的异常点检测
考察当前点周围密度,可以发现局部异常点,例如LOF算法
二、采样
hu
三、预处理
(一)特征可能有以下问题:
- 不属于同一量纲:无量纲化。
- 信息冗余:二值化。
某些定量特征,包含的有效信息为区间划分,例如成绩转换成“1”和“0”表示及格和未及格。- 定性特征:序号编码、独热编码、亚编码、二进制编码。
- 存在缺失值:缺失值需要补充。
- 信息利用率低:对定性特征独热编码,对定量变量多项式化,能达到非线性的效果。
- 特征缺失:删除、统一填充、统计填充、预测填充
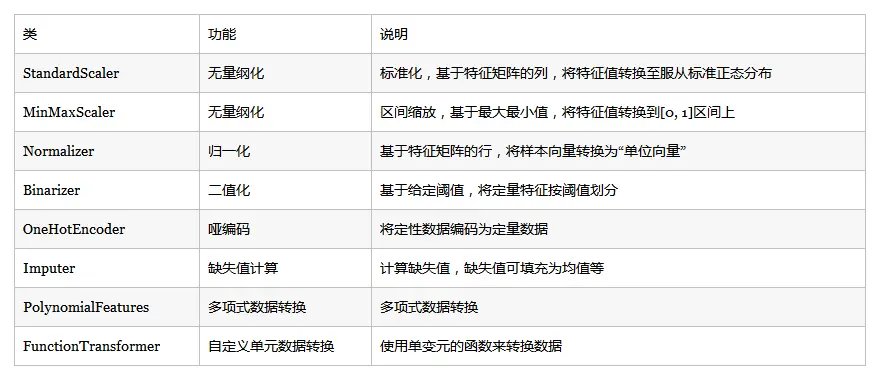
(二)无量纲化
- 标准化
z-score标准化,处理后均值0,标准差1,公式:
已有样本足够多的情况下比较稳定,适合大数据场景。from sklearn.preprocessing import StandardScaler StandardScaler().fit_transform(iris.data)
- 区间缩放法
通过线性变换把数据映射到[0,1]之间,公式:
数据流场景下最大值与最小值是变化的。另外,最大值与最小值易受异常点影响,鲁棒性差。from sklearn.preprocessing import MinMaxScaler MinMaxScaler().fit_transform(iris.data)
- 标准化与归一化的区别
标准化处理特征矩阵的列,通过求z-score,将样本的特征值转换到同一量纲下。
归一化处理特征矩阵的行,其目的在于样本向量在点乘运算或其他核函数计算相似性时,拥有统一的标准,转化为“单位向量”。from sklearn.preprocessing import Normalizer Normalizer().fit_transform(iris.data)
(三)二值化和独热编码
- 定量变量二值化
from sklearn.preprocessing import Binarizer Binarizer(threshold=3).fit_transform(iris.data) #阈值设置为3
- 定性变量独热编码
from sklearn.preprocessing import OneHotEncoder OneHotEncoder().fit_transform(iris.target.reshape((-1,1)))
(四)缺失值处理
- 删除
删除属性或者删除样本。如果大部分样本该属性都缺失,这个属性能提供的信息有限,可删除该维属性;如果一个样本大部分属性缺失,可删除该样本。- 统计填充
使用平均数、中位数、众数、最大值、最小值等。如果有可用类别信息,还可以进行类内统计,比如身高,男性和女性的统计填充应该是不同的。- 统一填充
对于含缺失值的属性,把所有缺失值统一填充为自定义值。如果有可用类别信息,也可以为不同类别分别进行统一填充。常用的统一填充值有:“空”、“0”、“正无穷”、“负无穷”等。- 预测填充
通过预测模型利用不存在缺失值的属性来预测缺失值。from numpy import vstack, array, nan from sklearn.preprocessing import Imputer #缺失值计算,返回值为计算缺失值后的数据 #参数missing_value为缺失值的表示形式,默认为NaN #参数strategy为缺失值填充方式,默认为mean(均值) Imputer().fit_transform(vstack((array([nan, nan, nan, nan]), iris.data)))
(五)数据变换
- 基于多项式的、基于指数函数的、基于对数函数的。
4个特征,度为2的多项式转换公式如下:

from sklearn.preprocessing import PolynomialFeatures #多项式转换 #参数degree为度,默认值为2 PolynomialFeatures().fit_transform(iris.data)
- 基于单变元函数的数据变换可以使用一个统一的方式完成,对数据进行对数函数转换的代码如下:
from numpy import log1p from sklearn.preprocessing import FunctionTransformer #自定义转换函数为对数函数的数据变换 #第一个参数是单变元函数 FunctionTransformer(log1p).fit_transform(iris.data)
四、特征选择
选择特征:
- 特征是否发散:如果一个特征不发散,方差接近于0,这个特征对于样本的区分并没有什么用。
- 特征与目标的相关性:与目标相关性高的特征,优先选择。
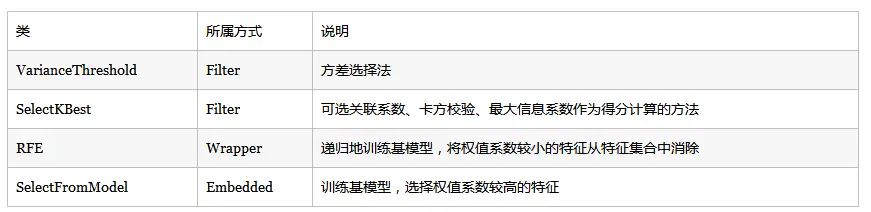
根据特征选择的形式分为3种:
- Filter:过滤法,按照发散性或相关性对特征评分,设定阈值或待选择的个数,选择特征。
- Wrapper:包装法,根据目标函数,每次选择若干特征,或者排除若干特征。
- Embedded:嵌入法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。
(一)Filter
采用统计中的一些检验来选择与输出变量最相关的那些特征。比如以卡方检验来检验与数据集预测变量(类别)的最佳特征。
(1)方差选择法
from sklearn.feature_selection import VarianceThreshold
#方差选择法,返回值为特征选择后的数据
#参数threshold为方差的阈值
VarianceThreshold(threshold=3).fit_transform(iris.data)
(2)相关系数法
from sklearn.feature_selection import SelectKBest
from scipy.stats import pearsonr
#选择K个最好的特征,返回选择特征后的数据
#第一个参数为计算评估特征是否好的函数,该函数输入特征矩阵和目标向量
#输出二元组(评分,P值)的数组,数组第i项为第i个特征的评分和P值。
#在此定义为计算相关系数
#参数k为选择的特征个数
SelectKBest(lambda X, Y: array(map(lambda x:pearsonr(x, Y), X.T)).T, k=2).fit_transform(iris.data, iris.target)
(3)卡方检验
经典的卡方检验是检验定性自变量对定性因变量的相关性。假设自变量有N种取值,因变量有M种取值,考虑自变量等于i且因变量等于j的样本频数的观察值与期望的差距,构建统计量
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
#选择K个最好的特征,返回选择特征后的数据
SelectKBest(chi2, k=2).fit_transform(iris.data, iris.target)
array = train_demo.values
X = array[:,0:19] #选取前19列为特征变量
Y = array[:,19] #选取target为目标变量
selection = SelectKBest(score_func=chi2, k=10).fit(X, Y) #设置卡方检验,选择k=10个最佳特征
fit = selection.fit(X, Y) #进行检验
feature_new = fit.get_support(indices = True)
print(fit.scores_) #打印卡方检验值
print(feature_new)
[4.71790022e+05 1.34089096e+02 1.21696988e+00 3.66069208e+04
1.53665557e+06 2.10423779e+00 3.46081823e+02 3.46034941e+02
2.90411325e+02 3.46070102e+02 4.16983624e+02 4.17051197e+02
4.17051197e+02 4.17051197e+02 6.30214866e+02 7.47235434e+01
1.29061811e+01 1.34089096e+02 8.00801618e+02]
[ 0 3 4 6 10 11 12 13 14 18]
(4)互信息法
经典的互信息也是评价定性自变量对定性因变量的相关性。
为了处理定量数据,最大信息系数法被提出
from sklearn.feature_selection import SelectKBest
from minepy import MINE
#由于MINE的设计不是函数式的,定义mic方法将其为函数式的,返回一个二元组,二元组的第2项设置成固定的P值0.5
def mic(x, y):
m = MINE()
m.compute_score(x, y)
return (m.mic(), 0.5)
#选择K个最好的特征,返回特征选择后的数据
SelectKBest(lambda X, Y: array(map(lambda x:mic(x, Y), X.T)).T, k=2).fit_transform(iris.data, iris.target)
(二)Wrapper
递归特征消除法
递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。
使用feature_selection库的RFE类来选择特征的代码如下:
from sklearn.feature_selection import RFE #导入RFE库
from sklearn.linear_model import LogisticRegression #导入逻辑回归库
model = LogisticRegression() #设置算法为逻辑回归
rfe = RFE(model, 10) #RFE-选择10个最佳特征变量构成子集,
fit = rfe.fit(X, Y) #进行RFE递归
print(fit.n_features_) #打印最优特征变量数
print(fit.support_) #打印选择的最优特征变量
print(fit.ranking_) #特征消除排序
10
[False False True False False True True True False True True False
True True True False True False False]
[ 7 9 1 4 6 1 1 1 3 1 1 2 1 1 1 10 1 8 5]
(三)Embedded
(1)基于惩罚项的特征选择法
使用feature_selection库的SelectFromModel类结合带L1惩罚项的逻辑回归模型,来选择特征。
from sklearn.svm import LinearSVC
from sklearn.feature_selection import SelectFromModel
print('原数据集维度:',X.shape)
lsvc = LinearSVC(C=0.01, penalty="l1", dual=False).fit(X, Y)
model = SelectFromModel(lsvc, prefit=True)
X_new = model.transform(X)
print('新数据集维度:',X_new.shape)
L1惩罚项降维的原理在于保留多个对目标值具有同等相关性的特征中的一个,所以没选到的特征不代表不重要。故,可结合L2惩罚项来优化。具体操作为:若一个特征在L1中的权值为1,选择在L2中权值差别不大且在L1中权值为0的特征构成同类集合,将这一集合中的特征平分L1中的权值。
(2)基于树模型的特征选择法
用GBDT进行特征选择
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import GradientBoostingClassifier
#GBDT作为基模型的特征选择
SelectFromModel(GradientBoostingClassifier()).fit_transform(iris.data, iris.target)
用随机森林进行特征选择
from sklearn.ensemble import RandomForestClassifier #导入RandomForest
array = train.values
X = array[:,0:52] #选取前52列为特征变量
Y = array[:,52] #选取target为目标变量
model = RandomForestClassifier(n_estimators=100) #设置RandomForest
model.fit(X, Y)
# 打印出有多少特征重要性非零的特征
feature_score_dict = {}
for fn, s in zip(feature_name_train, model.feature_importances_):
feature_score_dict[fn] = s
m = 0
for k in feature_score_dict:
if feature_score_dict[k] == 0.0:
m += 1
print('number of not-zero features:' + str(len(feature_score_dict) - m))
# 打印出特征重要性
feature_score_dict_sorted = sorted(feature_score_dict.items(), key=lambda d: d[1], reverse=True)
print('RF_feature_importance:')
for ii in range(len(feature_score_dict_sorted)):
print(feature_score_dict_sorted[ii][0], feature_score_dict_sorted[ii][1])
print('\n')
用XGBoost进行特征选择
from xgboost import XGBClassifier #导入XGBOOST
array = train.values
X = array[:,0:52] #选取前52列为特征变量
Y = array[:,52] #选取target为目标变量
model = XGBClassifier(n_estimators=50) #设置XGBOOST
model.fit(X, Y)
# 打印出有多少特征重要性非零的特征
feature_score_dict = {}
for fn, s in zip(feature_name_train, model.feature_importances_):
feature_score_dict[fn] = s
m = 0
for k in feature_score_dict:
if feature_score_dict[k] == 0.0:
m += 1
print('number of not-zero features:' + str(len(feature_score_dict) - m))
# 打印出特征重要性
feature_score_dict_sorted = sorted(feature_score_dict.items(), key=lambda d: d[1], reverse=True)
print('XGB_feature_importance:')
for ii in range(len(feature_score_dict_sorted)):
print(feature_score_dict_sorted[ii][0], feature_score_dict_sorted[ii][1])
print('\n')
五、特征组合
基于决策树:每一条从根节点到叶节点的路径都可以看做一种特征组合方式。
基于多项式:见数据变换中的多项式变换。
补充
参考资料:
《百面机器学习》
七种常用的特征工程
特征工程(sklearn)















 264
264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









