






乱码是我们在日常的工作中经常遇到的问题,你可能从网上好不容易下载了一个炫酷的jQuery插件,但是却在打开的时候,发现某几个js文件都是类似“澶у0?閬?”这样的怪异符号,其实这就是编码和解码不一致导致的,就好像我用英文给你写了篇信,你不懂英文用中文去解析它,自然觉得他是乱码。
本篇文章将会从计算机码的历史演变开始,简单介绍下主流的几种编码方式。希望对大家日后处理乱码有所帮助。
一、为何需要编码
由于计算机只能识别0和1,所以我们所有得字符和数据都是转换成二进制0和1的序列存放在计算机中的,但是我们在如何区分他们上产生了问题。就比如说,给一万个二进制的序列,你能读取出来其中哪些是字母哪些是数字么?不是不可以,难度很大,完全违背了我们使用计算机的初衷了。于是,我们可以规定每个字符的二进制序列,并把它存在计算机内,当需要将二进制位转换成我们能看懂的字符数据时,让计算机去截取二进制位查找对应的表,翻译成我们看的懂的数据。这规定字符的二进制序列就是一种编码行为,让计算机翻译就是一种解码行为。
二、ASCll 编码
我们都知道,计算机是美国人民发明的,所以他们在设计计算机编码的时候并没有考虑到给别的国家人用(尤其是我们第三世界国家人民)。ASCll 码全称是 American Standard Code for Information,美国信息互换标准代码。由于美帝人民使用26个英文字母的各种组合进行交流了(没有我们几万汉字那么多),于是他们使用八位二进制来表示所有的字符,从0到32用于特殊用途,比如:遇上00x10输出换行,遇上0x1b打印机工作等。还有一些空格,数字,字母等,一直编号到127(0111 1111),实际上他们只用了7个字节编完了所有的字符,因为最高位始终为0。
三、ISO 8859-1/Windows-1252
对于美国来说ASCll码足够用了,但是后来欧洲的一些国家也开始使用计算机,他们也为自己国家的语言进行扩充编码,于是他们将美国没用完的那个字节的后一半用来编码自己国家的语言,于是从128到255都有了定义。这一段编码我们叫做扩展字符集。ISO 8859-1就是这样的编码标准,0-127依然保存美帝的编码,128-255编码了一些他们需要使用到的字符。因为ISO 8859-1编码标准出现的比较早,而在后来又出现了一些比较中要的符号例如(欧元符号),这些符号并没有被编入,于是Windows-1252编码扩充了ISO 8859-1编码标准,删除了一些相对不常用的字符,替换了一些新的字符。可以说Windows-1252是ISO 8859-1的替代品。
四、GB2312
终于轮到我们伟大的中国人民,当我们能够使用计算机的时候,那一个字节已经被使用完了。于是我们决定保留美国的编码(ASCll 码),其余欧洲国家的编码全部删除,对于英文和西欧字符使用一个字节足够用了,对于我们汉字来说,需要使用两个字节来表示。小于127的依然表示原来的字符(也就是该字节最高位为0),当计算机遇到两个大于127的字节时候(也就是两个字节的最高位都是1),就一次性读取两个字节,将它解码成一个汉字。这就是GB2312编码,它大概能够表示7000多个简体汉字。不包括一些繁体字,但是对于日常使用已经足够。在这两个字节中,高位字节表示范围:0xA1-0xF7,低字节为表述范围:0xA1-0xFE。(可能大家看出来,有些范围并没有定义编码,后面说原因)
五、GBK
虽然已经编码了7000多个汉字,足够日常的使用了,但是我们勤劳的中国人民还是觉得不够用,于是他们发现:一个汉字使用两个字节表示,那如果第一个字节的最高位为1,那就不用将后一个字节的最高位也置为1,直接往后读取两个字节就好了。于是我们又扩充了一半的汉字。高位字节表述范围:0x81-0xFE,低位字节表述范围:0x40-0x7E和0x80-0xFE。
六、GB18030
为了照顾日韩和我们的少数民族,我们又对GBK加以扩充,使用变长编码,要么使用两个字节表示要么用四个字节表示。(至于为什么三个字节不用来表示,我也费解)那么我们怎么才能判断出某个字符他是用几个字节来表示的呢?用两个字节表示的字符和GBK一样,用四个字节表示的字符,第一个字节表述范围:0x81-0xFE,第二个字节表述的范围:0x30-0x39,第三个字节表述的范围:0x81-0xFE,第四个字节表述范围:0x30-0x39。每次解析的时候先拿过来这个字符的第二个字节判断范围是否在0x30-0x39之间,如果在说明这是四个字节表示的字符,如果不在说明这是两个字节表示的字符。从GBK的第二个字节表述范围看,它是大于0x39的。(这就是它低位字节0x30-0x39不编码的原因)
七、Unicode
每个国家都按照自己的标准编码的字符集,但是这会导致一个问题,两个编码不一致的国家的人相互之间交流成了很大的问题。(除了美国可以和任意的国家无障碍交流,因为每个编码标准都是兼容ASCll 的),于是当人们需要和别的国家之间进行交流的时候,就会在自己的系统上装上一个对方国家的编码转换系统。十分麻烦。于是 一个叫ISO(国际标谁化组织)的组织打算对世界上的所有编码进行统一,废除所有地方性编码方案。这就是UNICODE。所以,准确上来说UNICODE并不算是一种具体的编码标准,它只是将世界上所有的字符进行的编号,并没有指定他们具体在计算机中以什么样的形式存储。
不像上述的各种编码标准,准确的规定了每个字符在计算机中的二进制位,而UNICODE只是将所有的字符进行了编号,具体怎么存储它不关心。于是它有了几个具体的实现:UTF-8,UTF-32,UTF-16等。UNICODE的编号范围为:0x000000-0x10FFFF,包括将近110多万。基本囊括所有的字符,但是经常使用的范围在:0x0000-0xFFFF之间也就是65536以内。
UTF-32
UTF-32编码标准用固定4个字节进行编码。每个字符会有一个对应的Unicode编号,这个编号是个整数,它的二进制就是这个字符UTF-32编码。四个字节足够表示世界上的所有的字符,但是对于只需要的一个字节的ASCll 编码的字符也是使用了四个字节(浪费了三个字节),所以这种编码标准唯一的缺点就是浪费。一个概念,”大端”和”小端”。大端表示的是:四个字节序列,高字节在前,低字节在后。(也就是计算机读取顺序从前到后),小端则相反,将低字节排列在前面。这种编码方式缺点是很明显的,就是浪费空间,但是简单。
UTF-16
UTF-16使用的是变长字节表示,相对复杂些。分别使用两个字节或者四个字节表示。编号在 0x0000-0xFFFF之间的常用字符使用两个字节表示,其中0xD800-0xDBFF之间的编号没有定义字符。(用于辨别两个字节还是四个字节和GB18030类似)对于编号在0x10000-0x10FFFF之间的字符使用四个字节表示。只不过前两个字节被叫做高代理项后两个字节被称为低代理项,其中高代理项表述范围:0xD800-0xDBFF正好是上面没有定义的编号范围,低代理项表述范围:0xDC00-0xDFFF。区分一个字符是用的两个字节还是用的四个字节就不言而喻了。直接判断前两个字节的范围即可。
这种编码标准相对于UTF-32来说,是节约了不少空间,但是对于美国和西欧他们来说还是有点浪费。这种编码一般用于系统编码。
UTF-8
为了充分利用资源,还是被我们智慧的人类发明了UTF-8。UTF-8使用变长字节表示,分别可以使用1到4个字节不等,对于Unicode编号越小的自然使用的字节就越小。
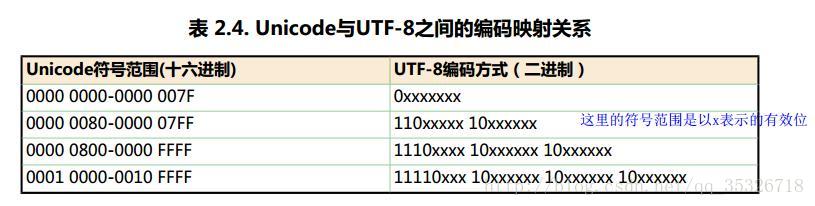
可以看到编号在127以内的使用一个字节表示(也就是ASCll ),(128-2047)使用两个字节表示,(2048-65535)使用三个字节表示,也就是我们大部分的汉字都是使用三个字节表示的,(65536以上)使用四个字节表示。
不同的区间范围对应了不同的模板。对于一个字符拿到Unicode编号之后,转换成而二进制判断所属范围,使用模板编码(具体怎么编码马上说)。除了用ASCll码的字符们,其他字符的模板的第一个字节都n个1加一个0,表示什么意思呢?第一个字节有几个1表示此字符由几个字节表示,方便计算机读取,低位字节开头都是10。 下面看一个例子:汉字“马”的Unicode编号是0x9A6C,转换成整数是39532,对应的模板是:1110xxxx 10xxxxxx 10xxxxxx。将整数39532转换成二进制:1001 1010 0110 1100。将这个二进制位从右向左开始,一次填入模板中x中,得到如下结果:1110 1001 1010 1001 1010 1100 1110。这就是“马”字的UTF-8编码。计算机解码的时候会一次性读取三个字节,逆操作解码,查表显示汉字。
最后小结一下,对于之前的一些编码标准都是按照编号转为二进制来形成编码,GB18030使用变长字节表示,通过比较任意字符的第二个字节的范围来判断存储时使用的字节数。UTF-16也是一种变长字节表示方案,通过比较高代理项的范围来确定使用字节数。UTF-8编码方式可以说是将上面的两种编码方式的有点扩充到了极致,使用变长字节表示,但是通过使用模板的方式来区分1-4个字节长度。只是过程有点复杂,但是综合还是UTF-8更加令人喜欢。
个人觉得所有编码标准应该都废弃,保留Unicode编码方式,使得从整个世界的角度上所有编码是统一的,这样就会大大减少乱码出现的频率。实际上,苹果早就抛弃所有方言编码标准,只接受Unicode编码标准。
本篇文章是作者学习总结,愚见,望对大家有帮助。
计算机编码基础

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









