






by:linshao
前述:
mysql由于锁机制等等对于大量数据里查找某几条的操作是非常耗时的,索引虽然能大大加快查询的速度,但是需要新增一些内存用于存放索引,
ELK是一款主流的日志平台架构,分布式,毫秒级响应的特性适用于大量数据的筛查,支持api接口访问,但是其缺点在于会使用源文件约2.5倍的空间(以空间换时间了)
目录:
1.什么是ELK
2.简单的ELK架构
3.部署安装
1.什么是ELK:
ELK 不是一款软件,而是 Elasticsearch、Logstash 和 Kibana 三种软件产品的首字母缩写。这三者都是开源软件,通常配合使用,而且又先后归于 Elastic.co 公司名下,所以被简称为 ELK Stack。根据 Google Trend 的信息显示,ELK Stack 已经成为目前最流行的集中式日志解决方案。
-
Elasticsearch:分布式搜索和分析引擎,具有高可伸缩、高可靠和易管理等特点。基于 Apache Lucene 构建,能对大容量的数据进行接近实时的存储、搜索和分析操作。通常被用作某些应用的基础搜索引擎,使其具有复杂的搜索功能;
-
Logstash:数据收集引擎。它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置;
-
Kibana:数据分析和可视化平台。通常与 Elasticsearch 配合使用,对其中数据进行搜索、分析和以统计图表的方式展示;
2.简单的ELK架构
ELK最简单的架构只需要一台机器即可架设
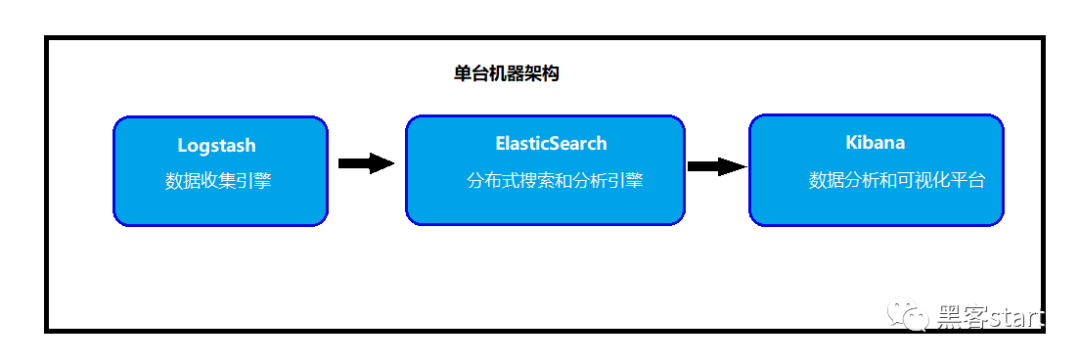
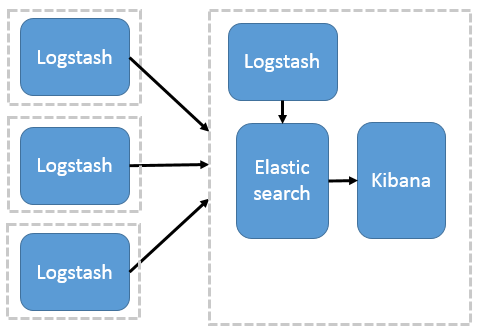
多台服务器分布式的日志搜集: 多台设备通过logstash搜集日志信息,发送到ElasticSearch服务器进行存储,再使用Kibana平台进行可视化分析
3.安装部署
1).环境准备:
java7环境以上
elasticsearch-6.5.4
下载地址:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.5.4.zip
kibana-6.5.4
下载地址:https://artifacts.elastic.co/downloads/kibana/kibana-6.5.4-windows-x86_64.zip
logstash-8.0.1
下载地址:https://artifacts.elastic.co/downloads/logstash/logstash-8.0.1-windows-x86_64.zip
2).开始安装
解压三个压缩包
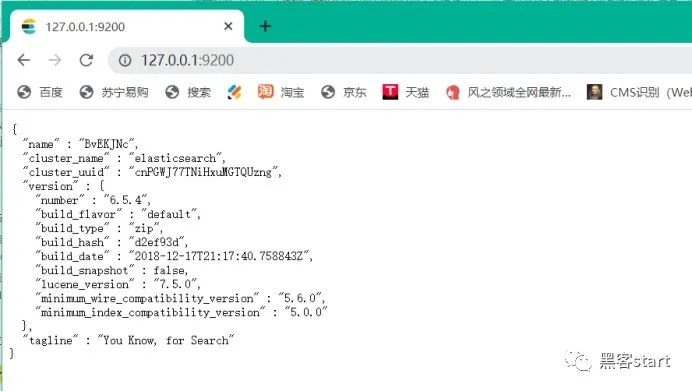
进入/elasticsearch-6.5.4/bin/ ,运行elasticsearch.bat,浏览器访问127.0.0.1:9200如下即成功:
接下来进入kibana-6.5.4-windows-x86_64\bin\ ,运行kibana.bat
浏览器访问http://127.0.0.1:5601端口看到以下界面说明kibana运行成功:
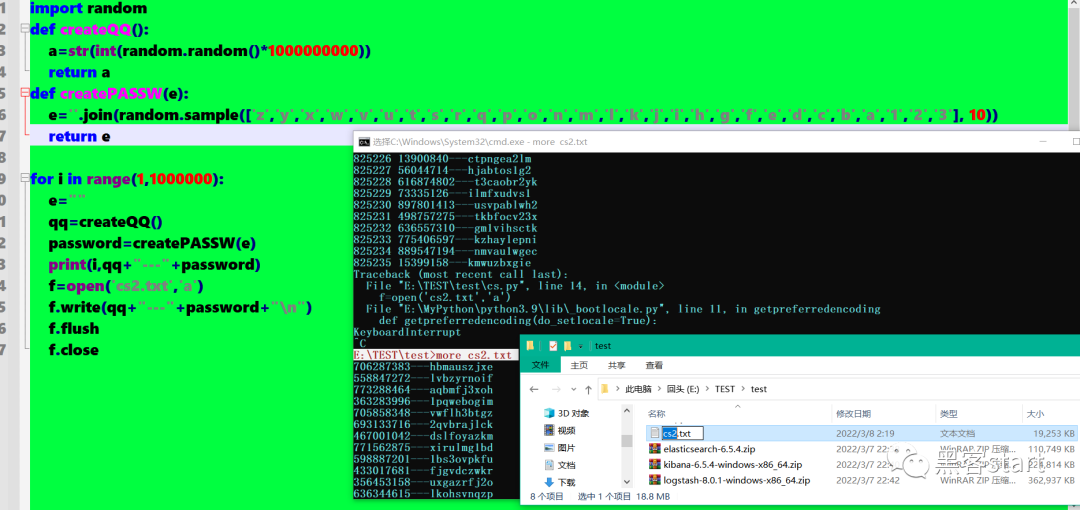
使用py生成一批测试账号密码
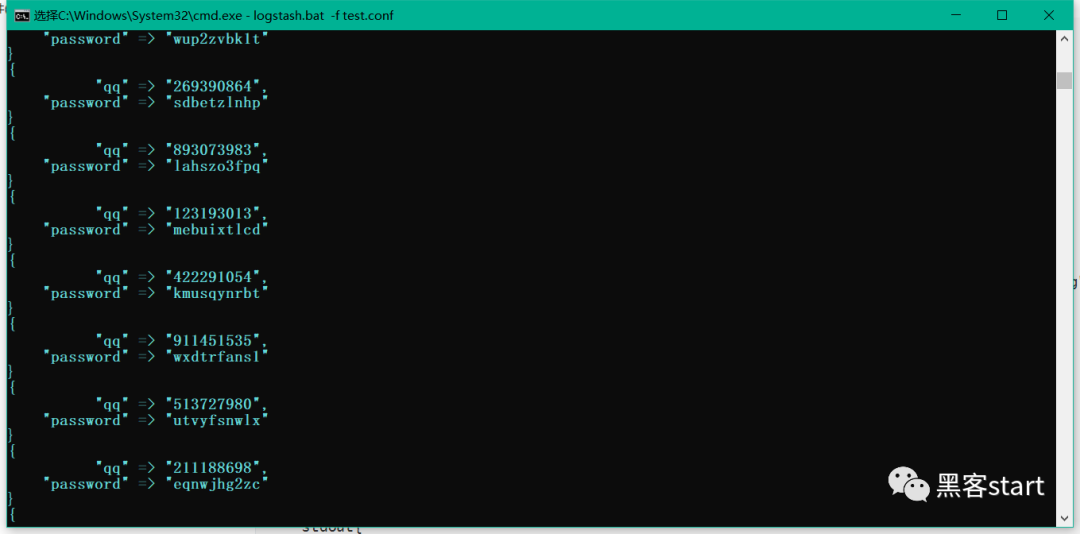
进入\logstash-8.0.1\bin目录,新建编写配置文件test.conf
input { #输入
file{
path=>"E:/TEST/test/cs2.txt" #输入源文件,注意此处不能使用反斜杠
start_position=>beginning #定义开头
}
}
filter { #过滤
csv{
columns=>["qq","password"] #存储的字段名字
separator=>"---" #分割符
}
mutate{ #移除默认的一些输出信息
remove_field=>["message","path","host","@timestamp","@version","original","event","log"]
}
}
output { #输出
elasticsearch{ #对elasticsearch进行配置
hosts=>["127.0.0.1:9200"] #host地址
index=>"wb" #库名
document_type=>"qq" #类型名
}
stdout{
codec=>rubydebug
}
}进入\logstash-8.0.1\bin,执行命令:logstash.bat -f test.conf如图下即开始写入数据
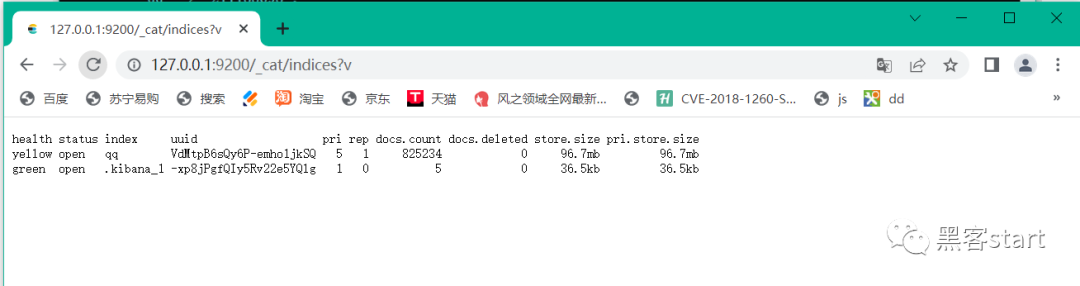
浏览器打开http://127.0.0.1:9200/_cat/indices?v可以看到任务存在了
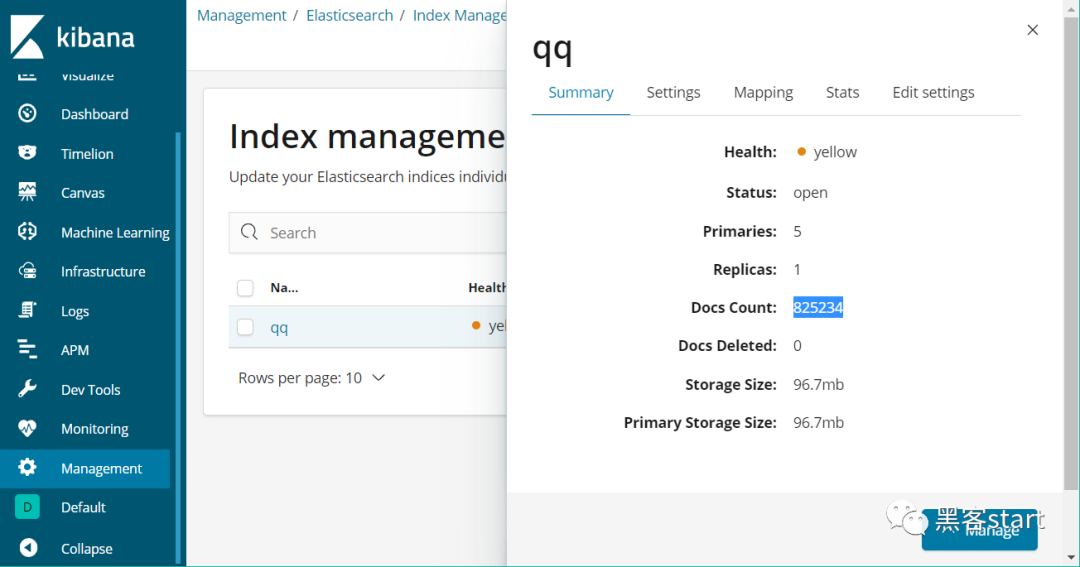
打开http://127.0.0.1:5601/在managerment->qq->可以看到导入了82万条数据
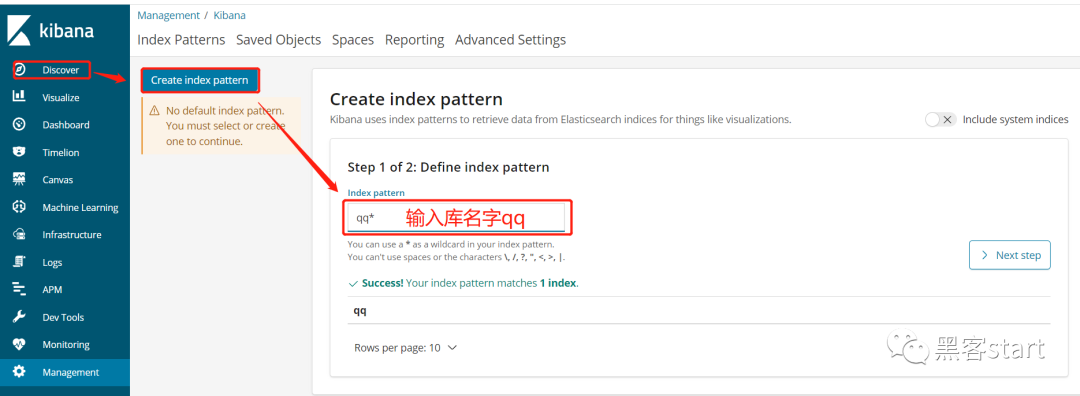
打开http://127.0.0.1:5601/创建一个模式(Managerment->index pattern->create也可以创建),一路下一步确定
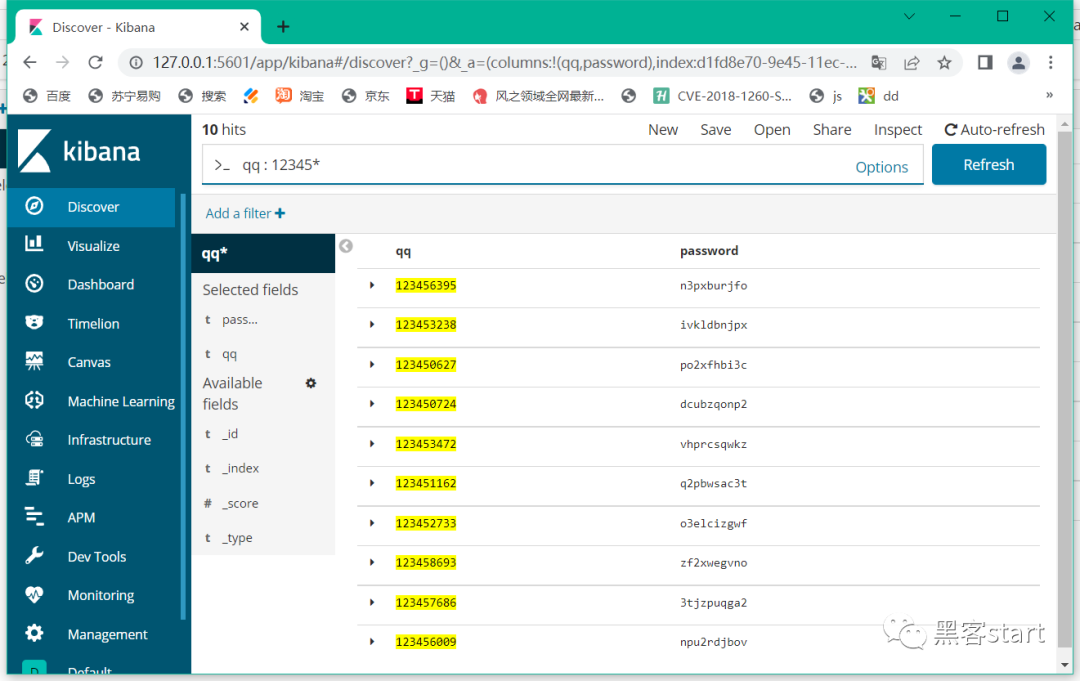
再次点击discover查找输入如qq:12345*(星号为通配符),响应速度非常快,秒出结果,几亿条大概响应时间为5-10s
结语:
心之所向,必是远方
















 3859
3859











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









