







背景介绍
主要测试使用java的JDBC对达梦数据库插入二百万条数据做一个测试并且进行调优。从java以及达梦数据库方面进行分析测试。以便大家更好的了解优化以及达梦数据库。
小结论
文章内容分为两部分:java代码的逻辑优化以及数据库的优化。
- java目前来说最优代码是采用D组的测试结果。
- java的代码逻辑优化远比数据库的优化来得更加明显无论是执行耗时还是便利程度上。形象的比喻是优化java代码就好比自行车换成小轿车的执行速度。调整数据库就只是给轿车换了比较好的轮胎。
搭建环境
基础描述
-
java的JDK1.8+DruidPool
-
达梦数据库DM8
-
VMware低配虚拟机
创建表
CREATE TABLE "SYSDBA"."T_ORDER"
(
"ID" INT IDENTITY(1, 1) NOT NULL,
"ORDER_NO" VARCHAR(20),
"CREATE_TIME" DATE,
"STATUS" CHAR(10),
CLUSTER PRIMARY KEY("ID"),
UNIQUE("ID")) STORAGE(ON "MAIN", CLUSTERBTR) ;
机器配置
为尽量保证数据准确数据库放到了虚拟机上

数据库实例信息

JAVA测试方案
执行两百万insert语句,使用不同方式。
A组:不用批处理,不用事务
测试结果是:插入10W条数据,需要60多秒
public class InsertTestDemo1 {
public static Connection getConnection(){
String url = "jdbc:dm://192.168.60.143:5236";
String user = "SYSDBA";
String password = "SYSDBA";
Connection connection = null;
try {
connection = DriverManager.getConnection(url, user, password);
} catch (SQLException e) {
e.printStackTrace();
}
return connection;
}
private static void insertData() {
Connection con = null;
PreparedStatement preparedStatement = null;
String insert_sql = "insert into \"SYSDBA\".\"T_ORDER\" (\"ORDER_NO\",\"CREATE_TIME\",\"STATUS\")" +
" values (?,'2020-1-19','0')";
try {
con = getConnection();
try {
preparedStatement = con.prepareStatement(insert_sql);
} catch (SQLException ex) {
ex.printStackTrace();
}
long time = System.currentTimeMillis();
for(int i=0; i<100000; i++){
preparedStatement.setString(1, "abc"+i);
preparedStatement.executeUpdate();
}
System.out.println("插入消耗时间"+(System.currentTimeMillis() - time) / 1000D + "s");
//插入消耗时间60.347s
} catch (Exception e) {
e.printStackTrace();
} finally {
if (preparedStatement != null) {
try {
preparedStatement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (con != null) {
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) {
insertData();
}
B组:采用批处理,不分批提交
结论是:执行次数2000000批量入2000000 条数据,耗费了23.909s
package com.dm.demo.millionInsert;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
/**
* 使用executeBatch()
*/
public class InsertTestDemo2 {
public static Connection getConnection(){
String url = "jdbc:dm://192.168.60.143:5236";
String user = "SYSDBA";
String password = "SYSDBA";
Connection connection = null;
try {
connection = DriverManager.getConnection(url, user, password);
} catch (SQLException e) {
e.printStackTrace();
}
return connection;
}
private static void insertData() {
Connection con = null;
PreparedStatement preparedStatement = null;
String insert_sql = "insert into \"SYSDBA\".\"T_ORDER\" (\"ORDER_NO\",\"CREATE_TIME\",\"STATUS\")" +
" values (?,'2020-1-19','0')";
try {
con = getConnection();
try {
preparedStatement = con.prepareStatement(insert_sql);
} catch (SQLException ex) {
ex.printStackTrace();
}
long time = System.currentTimeMillis();
for(int i=0; i<2000000; i++){
preparedStatement.setString(1, "abc"+i);
preparedStatement.addBatch();//添加到同一个批处理中
}
preparedStatement.executeBatch();//执行批处理
System.out.println("插入消耗时间"+(System.currentTimeMillis() - time) / 1000D + "s");
} catch (Exception e) {
e.printStackTrace();
} finally {
if (preparedStatement != null) {
try {
preparedStatement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (con != null) {
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) {
insertData();
//执行次数2000000批量入2000000 条数据,耗费了23.909s
//执行次数2000000批量入2000000 条数据,耗费了24.44s
//执行次数2000000批量入2000000 条数据,耗费了24.138s
}
}
C组:采用批处理,并分批提交
结论是:执行次数2000000批量入2000000 条数据,耗费了21.909s
注:JAVA层的话插入的耗时主要受每次批量插入数据多少影响,一般来说,事务控制下,分批大小在100-1000之间比较合适。因机器不同需要根据实际情况配置合适的参数
package com.dm.demo.millionInsert;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
/**
* 使用executeBatch()
*/
public class InsertTestDemo4 {
static int limitNum = 2000000;
public static Connection getConnection(){
String url = "jdbc:dm://192.168.60.143:5236";
String user = "SYSDBA";
String password = "SYSDBA";
Connection connection = null;
try {
connection = DriverManager.getConnection(url, user, password);
} catch (SQLException e) {
e.printStackTrace();
}
return connection;
}
private static void insertData() {
Connection con = null;
PreparedStatement preparedStatement = null;
String insert_sql = "insert into \"SYSDBA\".\"T_ORDER\" (\"ORDER_NO\",\"CREATE_TIME\",\"STATUS\")" +
" values (?,'2020-1-19','0')";
try {
con = getConnection();
con.setAutoCommit(false);//将自动提交关闭
try {
preparedStatement = con.prepareStatement(insert_sql);
} catch (SQLException ex) {
ex.printStackTrace();
}
long time = System.currentTimeMillis();
for(int i=0; i<limitNum; i++){
preparedStatement.setString(1, "abc"+i);
preparedStatement.addBatch();//添加到同一个批处理中
//优化插入第二步插入代码打包,等一定量后再一起插入。
//每100000次提交一次
if((i!=0 && i%100000==0) || i==limitNum-1){//可以设置不同的大小;如50,100,200,500,1000等等
preparedStatement.executeBatch();
//优化插入第三步提交,批量插入数据库中。
con.commit();
preparedStatement.clearBatch();//提交后,Batch清空。
}
}
System.out.println("插入消耗时间"+(System.currentTimeMillis() - time) / 1000D + "s");
} catch (Exception e) {
e.printStackTrace();
} finally {
if (preparedStatement != null) {
try {
preparedStatement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (con != null) {
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) {
insertData();
}
}
D组:采用批处理,分批提交,DruidPool连接池 (强烈推荐)
将数据池连接交给连接池管理,所以需要引入DruidPool的包以及配置文件
1. 引入Druid包+配置文件
- 手动下载jar包
Druid 数据库连接池 下载地址 :https://search.maven.org/search?q=druid
- maven文件坐标
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.7</version>
</dependency>
2. 配置文件
新建druid.properties并放到resources文件目录
driverClassName=dm.jdbc.driver.DmDriver
url=jdbc:dm://192.168.60.143:5236
username=SYSDBA
password=SYSDBA
initialSize=5
maxActive=10
maxWait=3000
3. java代码
结论是:执行次数2000000批量入2000000 条数据,耗费了19.909s
注:虽然java例子中只用到了一个连接,但测试结果是交给连接池管理后,效率确实有所提升
package com.dm.demo.millionInsert;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.Properties;
/**
* 使用executeBatch()
*/
public class InsertTestDemo7_DruidPool {
static int limitNum = 2000000;
public static Connection getConnection() throws Exception {
ClassLoader cl = InsertTestDemo7_DruidPool.class.getClassLoader(); // 得到classLoader 目的是找到项目目录的地址,并加载配置文件
InputStream ins = cl.getResourceAsStream("druid.properties"); //读取配置文件,并加载到properties中
Properties p = new Properties();
//加载配置文件到p对象中
p.load(ins);
//用工厂方法, 创建数据源, 参数为配置文件
DataSource dataSource = DruidDataSourceFactory.createDataSource(p);
//得到连接对象
Connection conn = dataSource.getConnection();
return conn;
}
private static void insertData() {
Connection con = null;
PreparedStatement preparedStatement = null;
String insert_sql = "insert into \"SYSDBA\".\"T_ORDER\" (\"ORDER_NO\",\"CREATE_TIME\",\"STATUS\")" +
" values (?,'2020-1-19','0')";
try {
con = getConnection();
con.setAutoCommit(false);//将自动提交关闭
try {
preparedStatement = con.prepareStatement(insert_sql);
} catch (SQLException ex) {
ex.printStackTrace();
}
long time = System.currentTimeMillis();
for(int i=0; i<limitNum; i++){
preparedStatement.setString(1, "abc"+i);
preparedStatement.addBatch();//添加到同一个批处理中
//优化插入第二步插入代码打包,等一定量后再一起插入。
//每100000次提交一次
if((i!=0 && i%100000==0) || i==limitNum-1){//可以设置不同的大小;如50,100,200,500,1000等等
preparedStatement.executeBatch();
//优化插入第三步提交,批量插入数据库中。
con.commit();
preparedStatement.clearBatch();//提交后,Batch清空。
}
}
System.out.println("插入消耗时间"+(System.currentTimeMillis() - time) / 1000D + "s");
} catch (Exception e) {
e.printStackTrace();
} finally {
if (preparedStatement != null) {
try {
preparedStatement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (con != null) {
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) throws Exception {
insertData();
}
}
达梦数据库的优化
小结:JAVA层的代码优化以后,我们主要来看数据库的优化。优化的主要是达梦数据库初始化实例以后的dm.ini文件参数。以下提供dm.ini文件的几个参数供参考,具体参数详细可以参考达梦安装目录下doc目录下的【DM8系统管理员手册.pdf】文件。
经过本人测试最少能在快4,5秒,当然也受机器,网络等不可控的因素。
1. 修改BDTA_SIZE参数

在dm.ini文件将数值调到最大值或者最小值,然后重启数据库后进行测试,看哪个效果更好。
2. 修改UNDO_RETENTION参数

在dm.ini文件将数值调到最大值或者最小值,然后重启数据库后进行测试,看哪个效果更好。(根据经验是越小越好)。
测试的时候把值改成0.1(比较极端),效果最佳。测试完了以后建议把值改到初始值。
3. 修改MEMORY_N_POOLS参数
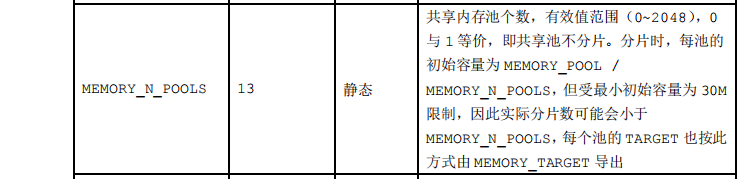
在dm.ini文件将数值调到最大值或者最小值,然后重启数据库后进行测试,看哪个效果更好。(根据经验是越大越好)。
4. 修改TEMP_SPACE_LIMIT参数

在dm.ini文件将数值调到者最小值。
5. 修改数据库的页大小
这个是在创建数据库实例的时候指定页大小设置为最大值32,如果库已经建立,只能删除重建并设置该值。

6. 额外的注意事项
插入数据的中文尽量与数据库的编码保持一致,比如说gbk转utf-8编码转换消耗的问题。
大结论
- java的代码逻辑优化远比数据库的优化来得更加明显无论是执行耗时还是便利程度上。形象的比喻是调整java代码就好比自行车换成了小轿车的执行速度。调整数据库就只是给轿车换了比较好的轮胎。
- 连接池最基本的也是最重要的优化策略,总能大幅提高性能。
- 批处理在效率上总是比逐条处理有优势,要处理的数据的记录条数越大,批处理的优势越明显,批处理还有一个好处就是减少了对数据库的链接次数,从而减轻数据库的压力。
- 在批处理执行的时候,每批执行完成后,最好显式的调用pstmt.close()或stmt.close()方法,以便尽快释放执行过的SQL语句,提高内存利用率。
- 虽然测试结果只能反映特定情况下的一些事实,以上的优化策略是普遍策略,可以明显缩短寻找最优策略的时间,对于效率要求很高的程序,还应该做并发性等测试。
- 测试是件很辛苦的事情,你需要有大量的事实来证明你的优化是有效的,而不能单单凭经验,因为每个机器的环境都不一样,使用的方式也不同。
代码地址
代码中还有一些对预编译sql、硬sql、c3p0连接池性能测试。
链接:https://pan.baidu.com/s/1gpEjdh6T0P7Bl2j6yNmGEw 提取码:9nl0
=======================================
有任何问题请到技术社区反馈。
24小时免费服务热线:400 991 6599
达梦技术社区:https://eco.dameng.com















 2701
2701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









