







 最左匹配原则是MySQL中联合索引使用的关键,指从最左边的字段开始连续匹配。遇到范围查询会停止匹配。例如,对于(a,b)索引,查询条件a = 1 and b = 2能有效利用索引,而b = 2则不能。同样,对于(a,b,c,d)索引,若条件为a = 1 and b = 2 and c > 3,c后的d字段无法使用索引。这是因为B+树结构基于最左字段排序,后续字段在范围内是无序的。"
119837673,9741434,深度学习进阶:卷积神经网络与反向传播解析,"['深度学习', '神经网络', '卷积']
最左匹配原则是MySQL中联合索引使用的关键,指从最左边的字段开始连续匹配。遇到范围查询会停止匹配。例如,对于(a,b)索引,查询条件a = 1 and b = 2能有效利用索引,而b = 2则不能。同样,对于(a,b,c,d)索引,若条件为a = 1 and b = 2 and c > 3,c后的d字段无法使用索引。这是因为B+树结构基于最左字段排序,后续字段在范围内是无序的。"
119837673,9741434,深度学习进阶:卷积神经网络与反向传播解析,"['深度学习', '神经网络', '卷积']
顾名思义:最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
例如:b = 2 如果建立(a,b)顺序的索引,是匹配不到(a,b)索引的;但是如果查询条件是a = 1 and b = 2或者a=1(又或者是b = 2 and a = 1)就可以,因为优化器会自动调整a,b的顺序(in 和 =)。再比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,因为c字段是一个范围查询,它之后的字段会停止匹配。
详解:
因为索引的底层是一棵B+树,联合索引的键值数量不是一个,而是多个。
但是构建一棵二叉树只能根据一个值来构建,因此数据库依据联合索引最左的字段来建立B+树。
举个栗子:
假如创建一个(a,b)的联合索引,那么它的索引树是这样的
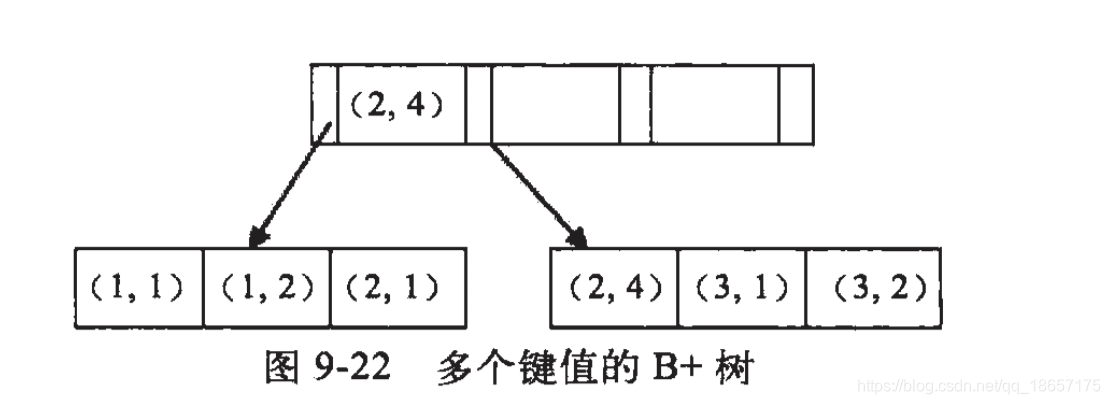
可以看到a的值是有顺序的,1,1,2,2,3,3
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2401
2401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









